
PostgreSQL PWI : LOCK > Row-level Lock(1)
PWI(PostgreSQL Wait Interface)- LOCK
PostgreSQLのWait Eventについて説明する前に、まずPostgreSQLで使用されるロック全般について取り上げます。
PostgreSQLでは、Relationのようなオブジェクトを保護するHeavyweight Lock(HWLock)、Relationの構成要素である行(Row)を扱うRow-level Lock、そして主に共有メモリ内のデータ構造へのアクセス時に使われるLightweight Lock(LWLock)など、さまざまな種類のロックが提供されています。
この「PWI - Locks」シリーズでは、PostgreSQLにおけるロックの種類や特徴、動作の仕組みについて解説し、実際の使用例を通じてロックの取得および解除の流れを確認していきます。
前回の記事で取り上げたRelation-level Lockに続き、今回はRelationを構成する要素であるRow-level Lockについて詳しく見ていきます。
Row-level Lock(行レベルロック)
複数のトランザクションが同じ行(Row)を同時に更新することを防ぐためには、ロックによる管理が必要です。Relation(リレーション)の1つ1つのレコードは「Row(行)」と呼ばれ、物理的には「Tuple(タプル)」と表現されます。そのため、一般的にユーザーが考えるRow-level Lockは、実際にはTupleに対して作用するロックであると言えます。
📝 Tupleは、PostgreSQLのMVCC(Multi-Version Concurrency Control)メカニズムにおいて重要な概念です。トランザクションによって変更された行(Row)を複数のバージョンとして管理することで、MVCCを実現しています。この各バージョンが「Tuple」であり、別の言い方をするとRow Version(行バージョン)」とも呼ばれます。
Tupleはヘッダ領域とデータ領域で構成されており、ヘッダには以下のようなフィールドが含まれています。
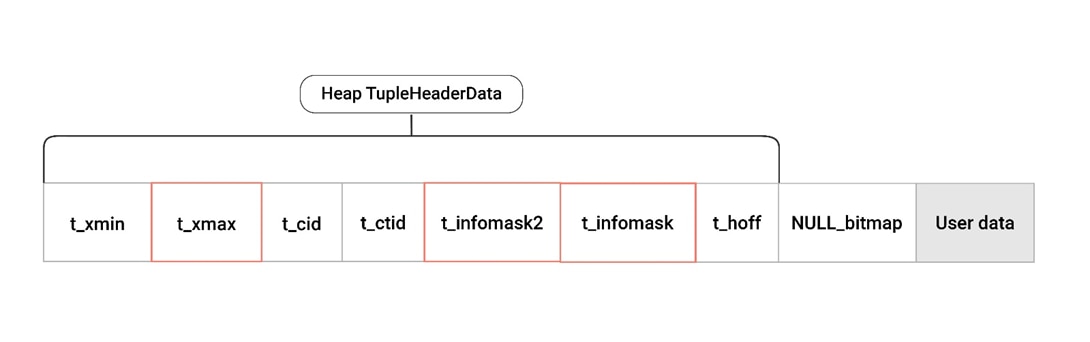 • xmin、xmax- トランザクションID表示、これは同じRowを指す他のバージョンと該当バージョンを区別
• xmin、xmax- トランザクションID表示、これは同じRowを指す他のバージョンと該当バージョンを区別
• cid - 現在のトランザクション内でこのCommandが実行される前に実行されたSQL Commandの数
• ctid - 同じRowの次のアップデートバージョンに該当するTupleを指すポインタ
• infomask - バージョン属性を定義する情報を表すビット(Hint bit)
• hoff - Tuple Headerのサイズ
• null bitmap - NULL値を含むことができる列を表示するビット配列
Relationとは異なり、Rowは一度に大量の変更要請が可能です。 この場合、実質的に当該Rowに対応するTupleに対するロック設定が必要ですが、これをすべて共有メモリに保存して管理することは不可能です。 これを解決するために、PostgreSQLではTwo-levelのメカニズムを使用します。
特徴1: Two-levelメカニズム
Row-level Lockの重要な特徴の一つであるTwo-levelメカニズムは、以下のように実装されます。
[Level 1] Lock情報の書き込み:TupleヘッダにLock情報を記録します。このメカニズムを使用すると、少ないコストで多数のTupleに対するLockを設定できるため、同時に多くのRowに対するリクエストを処理することができます。
[Level 2] Wait Queueの管理:Tupleに対するHWLock(Heavyweight Lock)の獲得および解放の過程が追加され、Lock Managerを使用します。このメカニズムは、2つ以上のトランザクションが同時に同じRowに対して修正要求を行う場合、そのLockに対するWait Queueを実装し、該当Tupleの作業順序を管理することができます。
すべての状況でRow-level Lockに対してHWLockを使用すると、サーバーの共有メモリ空間を占有するだけでなく、Lockの対象が多くなると管理の限界が発生する可能性があります。そのため、PostgreSQLでは現在Rowを修正しているトランザクションが存在する場合、その情報をTupleに記録する方式を用いてRow-level Lockを実装します。そして必要な場合に限り、追加でTupleに対するHWLockを使用します。
[Level 1] Lock Information Write
上で説明したように、トランザクションが現在Rowを修正中であるという状態情報を、Rowに対応するTupleのHeaderに記録する方式です。Rowを修正しようとするトランザクションは、該当Rowに作業中の他のトランザクションがあるかどうかを、Tuple Headerに記録された情報を確認することで作業可能かどうかを判断できます。
このメカニズムを通じて、Row-level Lockを実際のLock ObjectではなくTupleの属性として管理するため、メモリを追加で使用しないという利点があります。
📝TupleはPostgreSQLのShared Buffer内のData PageのData領域に位置しているため、Tuple HeaderにLock情報を記録するということは、Buffer内のData Pageを変更しようとすることを意味します。したがって、Buffer関連の作業に必要なLockを獲得する過程が追加される可能性があると予想されます。
Row-level Lockに関連して、Tuple Headerに情報を記録する過程について見ていきます。
Tuple Headerには、Lock情報を含めたさまざまな状態情報が保存されています。その中でLockに関連する領域は、xmax、infomask、およびinfomask2です。xmaxにはRowに対して作業中のトランザクションのIDが記録され、infomask、infomask2にはTupleの状態情報がビットで保存されます。これらの情報を基に、トランザクションのCommit/Rollbackの有無、Row-level Lock、Update処理方式など、さまざまな情報を知ることができます。
📝Tupleの状態情報をビットで表したinfomaskとinfomask2を、今後は総称して「infomask bit」と呼ぶことにします。
トランザクションがRowを修正しようとすると、まず該当Rowに対応するTuple Headerのxmaxの値を確認します。xmaxがNULLであれば、現在そのTupleに作業中のトランザクションはいないと判断し、すぐに作業が可能です。しかし、xmaxにトランザクションIDが記録されている場合は、さらにinfomask bitを確認して、トランザクションの状態およびRow-level Lockの設定有無を確認する必要があります。その結果により、xmaxに記録されたトランザクションが完了するまで待機しなければならない場合があります。
このメカニズムでは、作業中のトランザクションが終了した後、待機中のすべてのトランザクションの待機が解除されます。もし待機中のトランザクションが多数であれば、次に作業するトランザクションを決めるために競争が発生し、この過程で無期限に待機するトランザクションが生じる可能性があります。こうした現象を防ぐために、Level 1メカニズムよりも強いLockメカニズムが必要になります。
[Level 2] Wait Queue Manage
上記の理由により、Level 1メカニズムによってRow-level Lockの状態を確認し、トランザクションの待機有無を判断することはできますが、待機中のトランザクションの中から次に作業するトランザクションを選定することはできません。したがって、より強力なLockメカニズムであるLevel 2メカニズムが必要となります。
Level 2メカニズムは、Lock Managerを使用してWait Queueを実装することで、Row-level Lockを待機しているトランザクションの作業順序を提供します。Queueを実装するためにはHWLockが必要であり、Tupleに対するHWLockの獲得および解放の動作が追加されます。
📝トランザクションがRowを修正しようとする際の動作過程は次の通りです。
- まず修正しようとするRowに対応するTuple Headerのxmaxとinfomask bitを確認します。他のトランザクションにより修正中のTupleである場合、Tupleに対するHWLockを要求します。
- HWLockの獲得に成功した場合、現在Tupleを修正中のトランザクションの終了時点を追跡するために、そのトランザクションIDに対して追加でLockを要求します。一方、すでに他のトランザクションが該当HWLockを保持している場合、HWLockの獲得に失敗し、Wait QueueでHWLockの獲得を待機します。
- 先に作業していたトランザクションが終了すると、最初に待機していたトランザクションがTupleを修正できるようになります。Tuple HeaderのxmaxにトランザクションIDを記録し、要求通りにinfomask bitを設定します。
- 獲得していたTupleに対するHWLockを解放します。
次に、Row-level Lockの衝突が発生したとき、Wait Queueを実装する過程を図を用いて詳しく見ていきます。
- 3つのトランザクション(T1、T2、T3)が順番に同じRow(Tuple A)を修正しようとしている状況です。
- 3つのトランザクションはいずれも互換性のないモード「ExclusiveLock」を要求していると仮定します。
- T1、T2、T3はいずれも自分自身のトランザクションIDに対して、Lockを「Exclusive」モードで獲得した状態です。
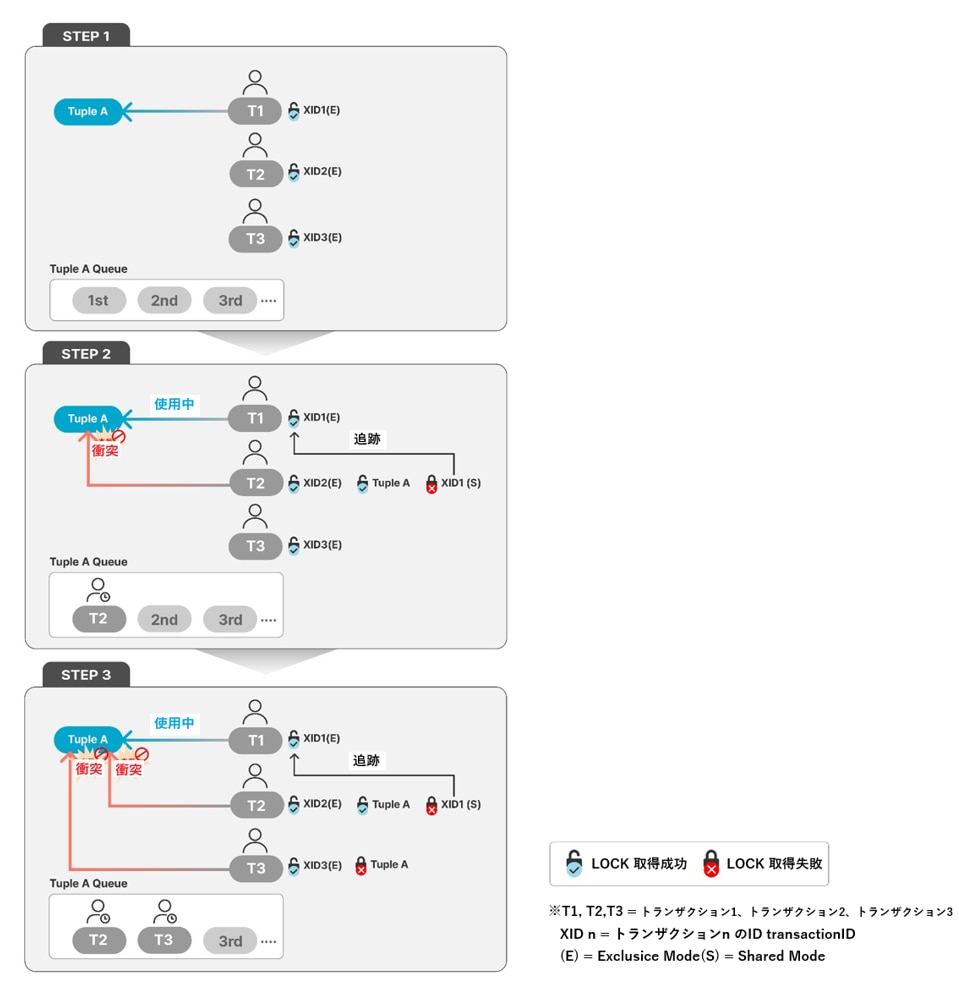
まず最初に、T1がTuple Aを更新しようとアクセスします。Tuple Aのヘッダにあるxmaxとinfomask bitを確認します。Tuple Aは他のトランザクションによって使用されていないため、Tuple AのヘッダにT1のトランザクションIDをxmaxに記録し、T1の要求に従ってLock情報を含む状態をinfomask bitに設定します。
続いて、T2もTuple Aを更新しようとしますが、Tuple Aは既にT1によって更新中であるため、アクセスがブロックされます。Tuple Aに対する処理を行うため、T2はTuple AにLockを要求し、Wait Queueで待機します。(このとき、T2はTuple Aに対するLockの取得には成功します。T2は最初に待機するトランザクションであり、T1の終了後、最優先でTuple Aを更新することができます。)
また、T2は先に作業を行っているT1のトランザクション終了を追跡するため、T1のトランザクションIDに対してShareLockを要求しますが、T1がそのトランザクションIDに対してExclusiveLockを保持しているため、取得には失敗し、Sleep状態で待機することになります。T3もTuple Aを更新しようとアクセスします。しかし、Tuple Aは依然としてトランザクションT1によって使用中であるため、T2と同様に、待機のためTuple Aに対するLockを要求します。ただし、すでにT2がTuple Aに対してLockを取得しているため、T3は取得に失敗し、自分の順番が来るまでWait Queueで待機します。
T1のトランザクションが終了すると、T2がTuple Aにアクセスして更新を行うことができるようになり、T2はTuple Aに対するHWLockを解放します。これにより、Wait Queueで待機していたT3がTupleのHWLockを取得し、最初の待機者となってT2のトランザクション終了を追跡します。
📝Level 2のメカニズムで使用されるTupleに対するHWLockは、pg_locksで確認することができます。(locktype= 'tuple')
引き続き、Row-level Lockで使用されるLockモードの種類と、それぞれの動作について説明します。
特徴2: 4種類のLockモード
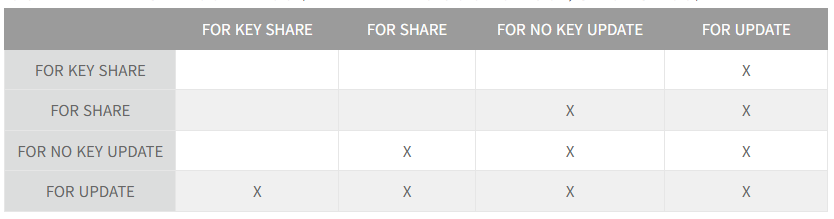
Row-level LockのLevel 1メカニズムで使用されるLockモードは、FOR KEY SHARE、FOR SHARE、FOR NO KEY UPDATE、FOR UPDATEの4種類です。各モードは、Tupleヘッダのinfomask bitにそれぞれ異なる形で記録されます。
Lockモードは、SQLコマンドに応じて自動的に選択される場合もありますが、明示的に指定することも可能です。自動的に選択される場合は、選択可能なモードの中で最も弱いモード、つまり互換性が最も高いモードが選ばれます。
以下の表は、モード間の互換性を示しています。(「X」は、モード間に互換性がないことを意味し、衝突が発生することを表します。)
Exclusiveモード
4つのモードのうち、「FOR UPDATE」と「FOR NO KEY UPDATE」モードは、他のモードと互換性がないという特徴を持つExclusive Lockの性質を持ちます。
- FOR UPDATE - すべての種類のRowの更新および削除処理で選択されるモードであり、他のモードとは互換性がありません。
- FOR NO KEY UPDATE - Unique Indexに含まれない領域に対するRowの更新および削除処理に限定して選択できるモードです。「FOR UPDATE」モードとは異なり、「FOR KEY SHARE」モードとは互換性があります。
Lockモードは、選択可能なモードの中で最も弱いモードを選択するという原則に従って、キー以外の領域に対する更新・削除処理が行われる場合には、ほとんどの場合「FOR NO KEY UPDATE」モードが選択されます。
Tupleヘッダに記録されたRow-level Lock情報を簡単に確認するために、pageinspect拡張機能を利用して関数を作成します。そして、テストのためにrow_testテーブルを作成し、データを挿入します。
▼ Tuple Header 情報確認のために使用する Script(pageinspect Extension-HEAP_PAGE_FUNCTION)
-- pageinspect Extension(pageinspect拡張機能の作成)
CREATE EXTENSION pageinspect;
-- Header情報を変換する関数の作成
CREATE FUNCTION heap_page(relname text, pageno integer)
RETURNS TABLE(
ctid tid
, xmin text
, xmax text
, LOCK_ONLY text
, IS_MULTI text
, HOT_UPDATED text
, KEYS_UPDATED text
, KEYSHR_LOCK text
, SHR_LOCK text
, t_ctid tid
)
AS $$
SELECT (pageno,lp)::text::tid as ctid,
t_xmin || CASE
WHEN (t_infomask & 256) > 0 THEN ' (c)'
WHEN (t_infomask & 512) > 0 THEN ' (a)'
ELSE ''
END AS xmin,
t_xmax || CASE
WHEN (t_infomask & 1024) > 0 THEN ' (c)'
WHEN (t_infomask & 2048) > 0 THEN ' (a)'
ELSE ''
END AS xmax,
CASE WHEN t_infomask & 128 = 128 THEN 'T' end as LOCK_ONLY,
CASE WHEN t_infomask & 4096 = 4096 THEN 'T' end as IS_MULTI,
CASE WHEN t_infomask2 & 16384 = 16384 THEN 'T' end as HOT_UPDATED,
CASE WHEN t_infomask2 & 8192 = 8192 THEN 'T' end as KEYS_UPDATED,
CASE WHEN t_infomask & 16 = 16 THEN 'T' end as KEYSHR_LOCK,
CASE WHEN t_infomask & 16+64 = 16+64 THEN 'T' end as SHR_LOCK,
t_ctid
FROM heap_page_items(get_raw_page(relname,pageno))
ORDER BY lp;
$$ LANGUAGE sql;CREATE TABLE row_test(
c1 integer PRIMARY KEY,
c2 text,
c3 numeric
);
INSERT INTO row_test values
(1, 'row1', 100.00), (2, 'row2', 200.00), (3, 'row3', 300.00);
c1|c2 |c3 |
--+----+------+
1|row1|100.00| -- ctid(0,1)
2|row2|200.00| -- ctid(0,2)
3|row3|300.00| -- ctid(0,3)次のように、1つのトランザクションでrow_testテーブルのPrimary Keyであるc1カラムに対するUpdate CommandとPrimary Keyではないc3カラムに対するUpdate Commandを実行します。
BEGIN;
-- UPDATE(1) - FOR UPDATE
update row_test set c1 = 20 where c1 = 1;
-- UPDATE(2) - FOR NO KEY UPDATE
update row_test set c3 = c3 + 100.00 where c1 = 2;今まで内容をすべて理解したなら、Primary Keyを修正しようとするUPDATE(1)は「FOR UPDATE」モード、Keyではない領域に対するUPDATE(2)は「FOR NOKEY UPDATE」モードを選択することが予想できます。 先ほど生成したheap_page関数を通して、Tuple HeaderにRow-level Lockが記録されているか結果を確認してみましょう。
-- heap_page:Tupleの状態を確認(xmax、infomask bitによるRow-level Lockの属性)
SELECT * FROM heap_page('row_test', 0); ①UPDATE(1)の対象であるctid
①UPDATE(1)の対象であるctid(0,1)に該当するTupleに記録された内容を見ると、key_updatedがTとなっており、「FOR UPDATE」モードであることを示しています。
そして、②UPDATE(2)によって更新されるctid(0,2)のTupleは、key_updated、keyshr_lock、shr_lockのすべてがNULLであるという結果から、「FOR UPDATE」「FOR KEY SHARE」「FOR SHARE」ではなく、「FOR NO KEY UPDATE」モードでRow-level Lockが記録されたことが確認できます。
📝上記の結果にあるctidカラムは、heap_page関数を作成する際に定義した内容であり、(0,2)はページ番号が0、ラインポインタが2であるTupleを指す値です。
また、hot_updated項目がTであることは、そのUpdateがHOT(Heap-Only Tuple)Updateとして処理されたことを意味します。
さらに、「SELECT FOR」コマンドを使用して、明示的に「FOR UPDATE」および「FOR NO KEY UPDATE」モードのRow-level Lockを使用することもできます。
前述のUpdateとの違いは、Rowを変更する操作ではないため、lock_only項目がTに設定されるという点です。
SELECT * FROM row_test WHERE c1 = 1 FOR UPDATE;
SELECT * FROM row_test WHERE c1 = 2 FOR NO KEY UPDATE;
-- heap_page:Tupleの状態を確認
SELECT * FROM heap_page('row_test', 0);

Sharedモード
Sharedモード
SELECT FORコマンドを使用して、明示的にRow-level Lockを以下のようなモードで使用することができます。
FOR SHARE すべての読み取り操作で選択できるモードであり、他のトランザクションによるあらゆる種類のTupleの更新を制限します。
FOR KEY SHARE 読み取り操作で選択できるモードである点は「FOR SHARE」モードと同様ですが、キー属性に該当するTupleの更新および削除操作のみを制限します。つまり、キーを変更せずにTupleを更新しようとするトランザクションはブロックされません。(このモードは、内部的に外部キーを確認する際にも使用されます。)
📝一般的なSELECTコマンドは、Row-level Lockを使用しません。
以下は、Row-level LockをSharedモードで使用する例です。
BEGIN;
-- SELECT(1) - SHARE
select * from row_test where c1 = 1 for share;
-- SELECT(2) - KEY SHARE
select * from row_test where c1 = 2 for key share;SELECT FORコマンドを使用して、明示的にRow-level LockをSharedモードとして選択します。
SELECT(1)とSELECT(2)はいずれも読み取り操作ですが、明示的に記述された構文であるため、それぞれ異なるモードが選択されます。
Tupleヘッダにどのように記録されたかを、heap_pageを使って確認してみましょう。
-- heap_page:Tupleの状態を確認
SELECT * FROM heap_page('row_test', 0) ; ① 2つのコマンドによって、ctid
① 2つのコマンドによって、ctid(0,1)およびctid(0,2)に該当するTupleのlock_onlyとkeyshr_lockの値がTに設定されていることが確認できます。
そして、②「FOR SHARE」モードでRow-level Lockを設定したTupleであるctid(0,2)には、shr_lockが追加で設定されています。
Tuple HWLock
Row-level Lockの2つのメカニズムのうち、Level 2に該当するLock Queue管理の場合、キューの実装のためにTupleに対するHWLockの取得および解放の処理が追加されるということを理解していれば、
次に生じる疑問は、「Tupleに対してHWLockを取得要求する際に、どのモードで要求しているのか?」という点です。
▼PostgreSQLでは、TupleのHWLockのLockモードはRow-level Lockに応じて次のように定義されています。
## postgres/src/backend/access/heap/heapam.c
/*
* Each tuple lock mode has a corresponding heavyweight lock, and one or two
* corresponding MultiXactStatuses (one to merely lock tuples, another one to
* update them). This table (and the macros below) helps us determine the
* heavyweight lock mode and MultiXactStatus values to use for any particular
* tuple lock strength.
*
* Don't look at lockstatus/updstatus directly! Use get_mxact_status_for_lock
* instead.
*/
static const struct
{
LOCKMODE hwlock;
int lockstatus;
int updstatus;
}
tupleLockExtraInfo[MaxLockTupleMode + 1] =
{
{ /* LockTupleKeyShare */
AccessShareLock,
MultiXactStatusForKeyShare,
-1 /* KeyShare does not allow updating tuples */
},
{ /* LockTupleShare */
RowShareLock,
MultiXactStatusForShare,
-1 /* Share does not allow updating tuples */
},
{ /* LockTupleNoKeyExclusive */
ExclusiveLock,
MultiXactStatusForNoKeyUpdate,
MultiXactStatusNoKeyUpdate
},
{ /* LockTupleExclusive */
AccessExclusiveLock,
MultiXactStatusForUpdate,
MultiXactStatusUpdate
}
};
/* Get the LOCKMODE for a given MultiXactStatus */
#define LOCKMODE_from_mxstatus(status) \
(tupleLockExtraInfo[TUPLOCK_from_mxstatus((status))].hwlock)
/*
* Acquire heavyweight locks on tuples, using a LockTupleMode strength value.
* This is more readable than having every caller translate it to lock.h's
* LOCKMODE.
*/
#define LockTupleTuplock(rel, tup, mode) \
LockTuple((rel), (tup), tupleLockExtraInfo[mode].hwlock)
#define UnlockTupleTuplock(rel, tup, mode) \
UnlockTuple((rel), (tup), tupleLockExtraInfo[mode].hwlock)
#define ConditionalLockTupleTuplock(rel, tup, mode) \
ConditionalLockTuple((rel), (tup), tupleLockExtraInfo[mode].hwlock)
TupleのHWLockのロックモードは、「設定しようとする」Row-level Lockのロックモードに応じて次のように決定されます。
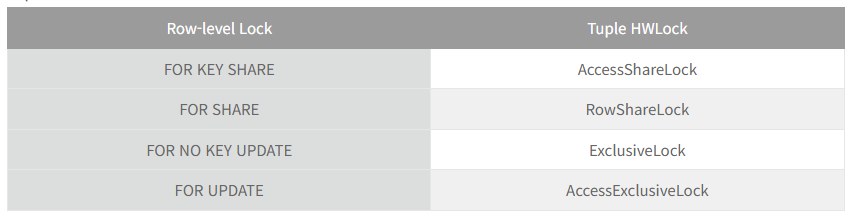
TupleのHWLockのモードは、Row-level Lockと同様に、AccessShare、RowShare、Exclusive、AccessExclusiveの4つのモードを提供します。
Row-level Lockのモードが
‘FOR KEY SHARE’ の場合、TupleのHWLockモードは ‘AccessShareLock’ として要求されます。
‘FOR SHARE’ の場合、TupleのHWLockモードは ‘RowShareLock’ として要求されます。
‘FOR NO KEY UPDATE’ の場合、TupleのHWLockモードは ‘ExclusiveLock’ として要求されます。
‘FOR UPDATE’ の場合、TupleのHWLockモードは ‘AccessExclusiveLock’ として要求されます。
実際のテストを通じて、SQLコマンドに応じてRow-level LockとTupleのHWLockがどのロックモードを使用しているかを確認してみましょう。
T: Transaction
T1) Row-level Lock: FOR UPDATE
update tuple_test set c1 = 20 where c1 = 1;
T2) Row-level Lock: FOR UPDATE -> Tuple HWLock: AccessExclusiveLock
update tuple_test set c1 = 20 where c1 = 1;
T3) Row-level Lock: FOR NO KEY UPDATE -> Tuple HWLock: ExclusiveLock
update tuple_test set c3 = c3 + 100.00 where c1 = 1;
T4) Row-level Lock: FOR SHARE -> Tuple HWLock: RowShareLock
select * from tuple_test where c1 = 1 for share;
T5) Row-level Lock: FOR KEY SHARE -> Tuple HWLock: AccessShareLock
select * from tuple_test where c1 = 1 for key share;それぞれの操作は個別のトランザクションによって異なるコマンドを実行しますが、すべて同じRowを対象としています。
そのため、選択されるRow-level Lockモードはすべて異なります。
最初にRowへの更新を要求したT1は、TupleヘッダにRow-level Lockの状態を記録するLevel 1メカニズム(Lock Information Write)に従っており、これはpgrowlocksの結果を通じて確認してみます。
その他のトランザクションはすべて**Level 2メカニズム(Wait Queue Manage)**に従ってTupleのHWLockを要求し、自分の順番を待つため、pg_locksを通じてTupleのLWLockを確認してみます。

📝PostgreSQLでは、Row-level Lockを確認するためのpgrowlocks拡張機能が提供されています。pgrowlocksを使用すると、パラメータとして指定したテーブルのRow-level Lock情報を確認することができます。
- ①pgrowlocksの参照結果から、modesが
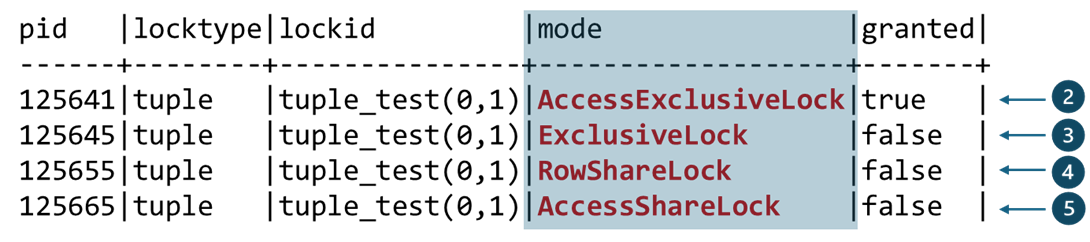
{Update}であることにより、最初のトランザクションであるT1が「FOR UPDATE」モードでRow-level Lockを設定していることが分かります。「FOR UPDATE」モードは、他のモードと互換性がありません。 - 続いてT2が、T1と同じRowを更新しようとしますが、T1がすでにそのRowに対応するTupleを更新しているため、待機が必要です。②pg_locksの参照結果から、T2はPrimary Keyを含む更新要求を行っており、Row-level Lockは「FOR UPDATE」モードが選択され、その結果、Tupleに対するHWLockは
AccessExclusiveLockとして取得されていることが確認できます(granted=true)。 ③キーに該当しない更新を要求したT3は、Row-level Lockとして「FOR NO KEY UPDATE」モードを選択し、それに応じてTupleのHWLockは
ExclusiveLockとして要求されました。続いて④「SELECT FOR SHARE」コマンドを実行したT4は、Row-level Lockを「FOR SHARE」モードで要求し、TupleのHWLockはRowShareLockとして取得待機中です。最後に⑤T5は「SELECT FOR KEY SHARE」コマンドを実行したため、Row-level Lockは「FOR KEY SHARE」モードであり、TupleのHWLockはAccessShareLockモードで要求されました。③~⑤のT3〜T5は、T2と同様にT1と同じRowにアクセスしようとしています。これらは同時に操作できないため、該当するTupleに対してHWLockを要求しますが、T2がすでに取得しているため、いずれも取得に失敗します(granted=
false)。
まとめ
これまで、PostgreSQLのRow-level Lockに関する特徴、使用されるLockモード、およびその詳細な動作過程について見てきました。
決して易しい内容ではありませんが、ここで改めてRow-level Lockの主要なポイントを以下にまとめます。
Row-level Lockは、PostgreSQL内部ではTuple単位で動作します。
Row-level Lockには、2段階のメカニズムである「Lock Information Write」と「Wait Queue Manage」が使用されます
Level 1メカニズムでは、Row-level Lockに関する情報が、Tupleヘッダのxmaxおよびinfomask bit(infomask、infomask2)に記録されます。
Level 2メカニズムは、Row-level Lockの記録(更新)過程で競合が発生する場合に追加的に必要となり、Lock Managerを利用してTupleに対するHWLockの取得・解放処理を通じてWait Queueが構築されます。
Row-level LockのLockモードは4種類あり、設定しようとするLockモードに応じて、Tupleに対するHWLockのLockモードが決定されます。
本記事では、PostgreSQL における Row-level Lock の仕組みや特徴、そして実際の動作過程について確認しました。
Row-level Lock が Tuple 単位で管理されることや、Lock Information Write と Wait Queue Manage という 2 段階のメカニズムを通じて実装されている点を理解できたと思います。
次回は、Row-level Lock の競合から発生する Dead Lock の仕組みと、その挙動について詳しく解説していきます。
※本記事は、以下のブログ記事を日本語向けに翻訳・再構成したものです:


