
PostgreSQL Architecture - 1. Process, Memory
Exemは、創業以来蓄積してきたITシステムの性能管理に関する豊富な経験と研究力をもとに、専門性と差別化を備えたコンサルティングサービスを提供しています。
このたびDBMSの専門家であるExemが新たにお届けする「DBインサイド」では、さまざまなDBMSや関連技術について、わかりやすく、そして深くご紹介していく予定です。
第一弾として PostgreSQLからスタートしてみたいと思います。
PostgreSQLは、オープンソースのオブジェクト関係型データベース管理システム(ORDBMS)です。リレーショナルデータベース(RDB)としての堅牢さを持ちながら、NoSQL的な機能にも対応しており、近年ではクラウド環境においても高く評価されている注目のDBのひとつです。
主要 Process
PostgreSQLでは、postmasterとpostgresというサーバープロセスを通じてコネクションが生成され、ユーザーからのリクエストを受け取ります。これらのリクエストは、さまざまなバックグラウンドプロセスによって処理されます。
本稿では、こうしたサーバープロセスの仕組みと、中心的な役割を担う主要なバックグラウンドプロセスについて詳しく見ていきます。
📌 本セクションで言及されたパラメータは、postgresql.confファイルで設定できます。
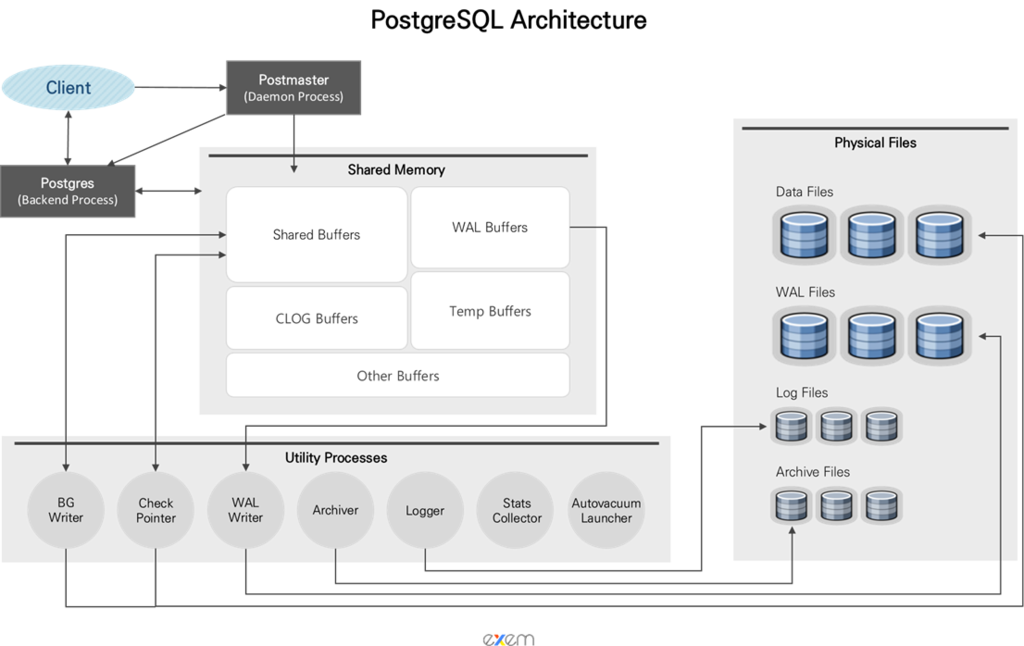
postmaster : Supervisor Daemon Process
- PostgreSQLサーバーを起動/中止するための必須プロセスであり、最初に立ち上がるプロセスです。postmasterプロセスは、共有メモリ領域を割り当て、様々なバックグラウンドプロセスを開始します。
- postmasterプロセスは、クライアントからの接続要求を常に待ち受けています。接続要求を受け取ると、postmasterはそのクライアントのために個別のpostgresプロセスを生成し、以降の通信および処理を引き継がせます。
- 最上位のプロセスとして、下位プロセスに異常がないかを常に監視し、問題が発生した場合には該当プロセスの再起動を行う役割も担っています。
postgres : Backend Process
- クライアントから要求されたSQLおよびコマンドを処理するプロセスは、クライアントとの接続が切断されると終了します。
- postmasterプロセスによって起動され、クライアントとは1対1の関係になります。
- max_connections (Default:100) この数値の分だけクライアントが同時に接続可能です。
Utility Process (Background Process)
PostgreSQLのバックグラウンドプロセスにはバージョンごとの違いがありますが、その中でも特に重要な2つの必須プロセス(BG Writer、WAL Writer)と、5つの選択的なプロセスについて解説します。
BG Writer
- OracleのDBWRプロセスに類似しており、Shared Buffer内のDirty Blockをディスクに書き込むプロセスです。
- BG Writerは bgwriter_delay (200 ms)ごとに最大 bgwriter_lru_maxpages (100 Pages)を ディスクに書き込みます。
- 定期的にBG WriterがDirty Blockをディスクに書き込むことで、Checkpoint発生時にFlushすべきDirty Blockの量を減らし、安定したI/Oパフォーマンスを維持できます。
WAL(Write Ahead Log/Xlog) Writer
- WALバッファを定期的にチェックし、未書き込みのすべてのトランザクションレコードをディスク(WALファイル)に書き込むプロセスです。
- WAL Writerは、トランザクションのCommit時やログファイルの空き領域がなくなった場合に、WAL Bufferをディスク(WALファイル)にフラッシュします。WALファイルはDatabaseのリカバリに使用されます。
📌 WALの核心的な概念は、「データファイルの更新は、トランザクションログへの記録が行われた後に実施されるべきである」という点です。Checkpointer
- Checkpointを実行するプロセスであり、PostgreSQL 9.2バージョンで追加されました。
- PostgreSQL 9.1以前のバージョンでは、BG Writerが定期的にCheckpointを実行していましたが、9.2以降はCheckpointerプロセスが追加され、その機能がBG Writerから分離されました。
- PostgreSQLサーバーのダウンやクラッシュなどの問題が発生した場合は、最後のCheckpointレコードを確認し、リカバリ処理が開始されます。
Checkpointの発生条件は以下の通りです。
- 前回のCheckpoint 発生以降、 checkpoint_timeout(5min)の時間が経過した場合
- WALファイルのサイズが max_wal_sizeを超過した場合
- Database Serverを「smart」または「fast」モードでシャットダウンする場合
- pg_basebackup または pg_start_backupによってbackupが開始される場合
- superユーザーがcheckpoint Commandを実行した場合
📌 ただし, 前回の Checkpoint 以後に書き込まれた WALが存在しない場合は、checkpoint_timeoutを超えていても新たなCheckpointは発生しません。
Archiver
- Oracleの ARCH(アーカイブプロセス)と同様に、 Archivingを遂行するプロセスです。
- Archivingは WAL セグメントが切り替わるタイミングで、WAL ファイルを Archive領域にコピーする機能で、コピーされたWALファイルはArchive と呼ばれます。
- Archive 領域のパスは archive_commandによって設定され、コピーの代わりに scp コマンドやファイルバックアップツールを使用して、他のホストへ転送することも可能です。
- これらのファイルは、PITR (Point In Time Recovery). すなわち Databaseを特定の時点・状態に復元する際に使用されます。
Stats Collector
- PostgreSQLの Database統計情報を収集するプロセスです。
- Session 情報(pg_stat_activity) やテーブル統計情報(pg_stat_all_tables)など、DBMSの利用統計を収集し、pg_catalogに情報を更新します。
- Optimizerは、最適なQuery 実行計画を生成するために、これらの統計情報を参照します。
- Serverが完全にシャットダウンされた場合でも、統計情報のコピーが pg_stat サブディレクトリに保存されるため、再起動後も統計情報が引き継がれます。
Autovacuum Launcher
• Autovacuumを実行/管理するプロセスです。
• Autovacuum Workersという複数のプロセスで構成されたDaemonプロセスであり、このプロセスによってvacuumの実行が自動化されます。
• Autovacuum Launcher プロセスは Autovacuum Workers プロセスを周期的に呼び出し、vacuum及びvacuum analyzeを実行します。
• autovacuum_naptime(1分)ごとにAutovacuum LauncherプロセスがDatabaseを確認し、 autovacuum_max_workers(3つ)のAutovauum Workersプロセスを呼び出します。
📌 PostgreSQLでは、行(Row)を更新する際、該当する行を物理的に書き換えるのではなく、新しい領域が割り当てられて使用されるため、変更前の行の領域は再利用されたり削除されたりしません。
この不要な領域を整理する処理(VACUUM)は必ず実行する必要があり、定期的に行うことが推奨されます。Logger
- エラー メッセージをログ ファイルに記録するプロセスです。
- Utilityプロセス、Backendプロセス、およびPostmaster Daemonの動作に関する情報は記録され、すべてのプロセス情報は $PGDATA/pg_log 以下に保存されます。
Memoryの分類
PostgreSQLはサーバーの起動時に、共有メモリ(Shared Memory)と呼ばれる共通のメモリ領域を割り当て、バックエンドプロセスごとにローカルメモリ(Local Memory)も割り当てます。
Shared Memoryとは、Data Blockやトランザクションログなどの情報をキャッシュする領域であり、PostgreSQL Serverのすべてのプロセスによって共有される領域でもあります。また、Process, Lock, globalな統計情報もこの領域に格納されます。
これとは別に、各バックエンドプロセスに対して個別に割り当てられ、他のプロセスとは共有されないローカルメモリという領域も存在します。この領域は、ソートやバキューム処理などの要求を処理するための作業領域です。
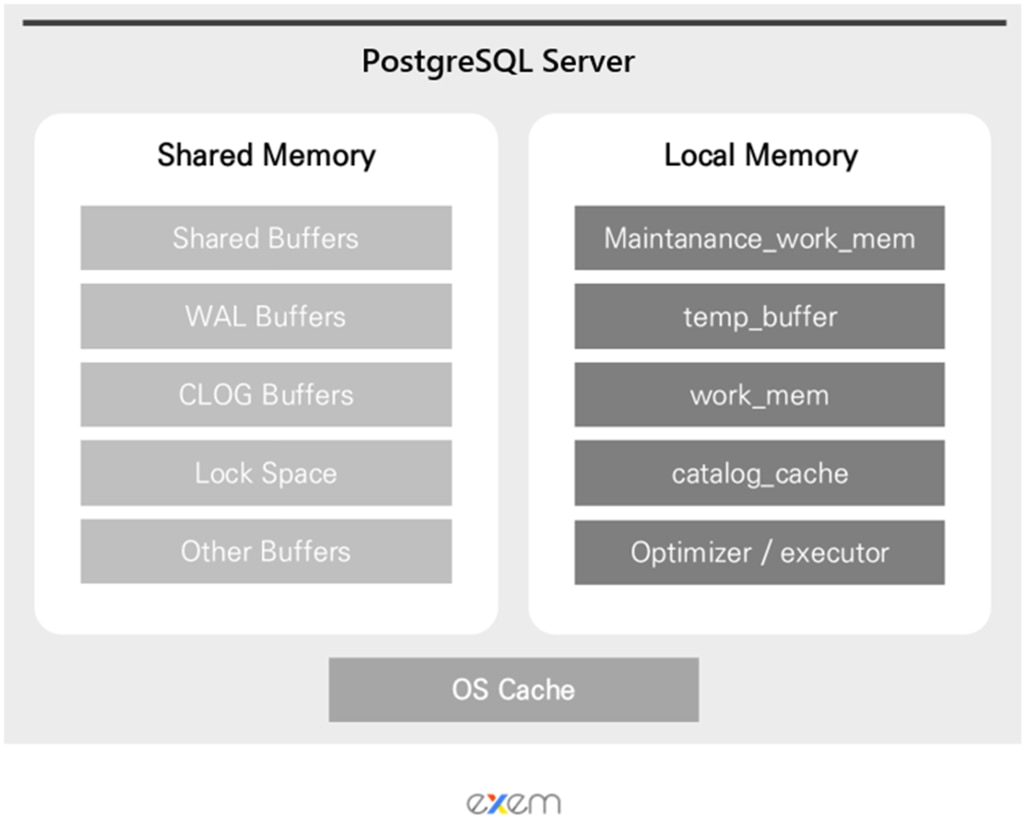
Shared Memory
Shared Memoryはすべてのプロセスで共有されて使用され、OracleのSGA領域と類似しています。ここでは、Shared Memoryを構成する代表的な4つの領域について見ていきましょう。
Shared Buffer
- Oracleのバッファキャッシュに類似しており、データおよびデータの変更内容をブロック単位でキャッシュし、I/O処理を高速化するための領域です。
- postgresql.conf の shared_buffers パラメータでサイズを設定できます。デフォルト値は128MBで、1GB以上のRAMを搭載したサーバーの場合は、システムメモリの25%を設定することが推奨されます。
- Shared Bufferに記録される単位は、block_size(デフォルトは8KB)です。
📌 PostgreSQLでは通常「ページ(Page)」という用語が使われますが、「ブロック(Block)」と併用されることもあります。
両者は使用される文脈や場所によって区別されることもありますが、本ドキュメントでは同じ意味として扱います。WAL Buffer (Write Ahead Log Buffer)
- Sessionが実行するトランザクションに関する変更ログをキャッシュする領域であり、リカバリ時にDataを再構築できるようにするためのものです。
- postgresql.conf wal_buffers パラメータでサイズを設定できます。デフォルト値は -1 であり、この場合は shared_buffersの1/32のサイズが自動的に設定されます。
Clog Buffer (Commit Log Buffer)
- 各トランザクションの状態(in_progress、committed、aborted)情報をキャッシュする領域で、すべてのトランザクションの完了状況を確認できるようにするためのものです。
- サイズを設定する専用のパラメータはなく、データベースエンジンによって自動的に管理されます。
Lock Space
- 共有メモリ領域のうち、Lockに関連する情報を保持する領域であり、PostgreSQLインスタンスが使用するすべての種類のロック情報が格納されます。ロック情報はすべてのバックグラウンドプロセスおよびユーザープロセスによって共有されます。
- ユーザーが特定のテーブルにアクセスする際、他のトランザクションがそのテーブルを削除または変更(DDL)しないように動作を追跡する必要があります。その追跡情報を保存するのがLock Spaceです。
📌 Lock Spaceに保持される Lock数は max_locks_per_transaction * (max_connections + max_prepared_transactions です。
Local Memory (Process Memory)
各Backendプロセスが個別に割り当てられて使用する領域で、OracleのPGAに相当します。この領域のサイズは各プロセスごとのものであるため、接続数全体を考慮して設定する必要があります。
また、Local Memoryは基本的にセッション単位で割り当てられますが、トランザクション単位で任意に調整することも可能です。
Maintenance Work Memory
- メンテナンス作業に使用されるメモリ領域であり、maintenance_work_mem のデフォルト値は64MBです。
- Vacuum処理、インデックス作成、テーブル変更、外部キーの追加などの操作に使用されます。
- これらの作業のパフォーマンスを向上させるためには、このメモリサイズを増やす必要があります。
Temp Buffer
一時テーブル(Temporary Table)に使用される領域で、 temp_buffersデフォルト値は8MBです。
-
一時テーブルを使用する場合にのみ割り当てられ、セッション単位で確保される非共有メモリ領域のため、過剰な一時テーブルの使用は問題を引き起こす可能性があります。
• この領域はテンポラリファイル(Temp File)とは関係がありません。 (Work Memory を参照してください)
Work Memory
- 大量のSort/Hash処理が発生した際に、一時ファイルを使用する前に利用されるメモリ領域です。work_memのデフォルト値は4MBです。
- 他のLocal Memoryと同様に、複数のセッションで同時に大量のSort/Hash処理が行われると、メモリ不足などの問題を引き起こす可能性があります。
📌 ソート処理には ORDER BY、DISTINCT、MERGE JOIN などがあり、ハッシュ処理には HASH JOIN、HASH AGGREGATION、IN サブクエリ などがあります。Catalog Cache
• System Catalog データを利用する際に使用されるメモリ領域です。セッションが頻繁にメタデータを参照するため、ディスクから毎回読み込むとパフォーマンス低下を招く可能性があり、この情報は個別のメモリに保持されます。
Optimizer & Executor
• 実行されるクエリに対して最適な実行計画を立案し、それに従って処理を実行するためのメモリ領域です。



