
FLM (Free List Management) - 日本エクセム株式会社 Oracle 技術情報
目次[非表示]
- 1.基本情報
- 1.1.フリーブロック
- 1.2.フリーリストの概念
- 1.3.フリーリストとフリーブロックの競合
- 1.4.フリーリストのグループとグローバルフリーブロックの競合
- 2.分析事例
- 2.1.RAC環境における、同じテーブルDMLによる性能低下現象分析
- 2.1.1.性能低下区間の確認
- 2.1.2.性能低下区間のズームアップ
- 2.1.3.待機イベントの検出および分析
- 2.1.4.RAC固有のパフォーマンス情報の分析
- 2.1.5.RAC相手ノード実行の分析
- 2.1.6.セッションの詳細分析を通じた問題の原因究明
- 2.1.7.結論
- 2.1.8.解決策
SQLチューニングのためには、そのSQLがどのように動いていて、データベースにどのように影響しているのか、を把握する必要があります。『MaxGauge』があれば簡単に状況が把握でき、適切なSQLチューニングができるようになります。
『MaxGauge』の資料はこちらから。
基本情報
FLMは、Oracleの伝統的なセグメント領域管理手法で、Oracle10g R2でもまだ使用可能な技法である。ただし、Oracleの10g R1までFLMがデフォルト属性でしたが、Oracleの10g R2からASSMがデフォルト属性となりました。
FLMはFree List Managementの略で、文字通りフリーリストの管理を使用してセグメント領域を管理するということを意味します。また、フリーリスト(Freelist)はフリーブロックのリストを意味します。フリーリストを理解するには、まずフリーブロックの意味を正確に理解する必要があります。
フリーブロック
セグメントレベルでのフリーブロック(Free Block)とINSERT操作のために使用可能な空きブロックを意味します。次のようなブロックがフリーブロックに分類されます。
フリーブロックにするかどうかを決定する要素は、セグメントの作成時に付与するPCTFREE属性とPCTUSED属性にあります。
フリーリストの概念
フリーリストとフリーブロックをリスト形式で管理することを意味します。セグメントヘッダブロック(Segment Header Block)にフリーリストのヘッダー(Header)とテール(Tail)の値を持っており、それぞれは、フリーブロックのDBA(Data Block Address)の値を持っています。各フリーブロックは、次のフリーブロック(Next Free Block)のDBA値を持っています。つまりフリーリストとセグメントヘッダの{ヘッダー/テール}{フリーブロック}{フリーブロック}…で行われたリストを意味します。
オラクルは、全3種類のフリーリストを使用する。
フリーリストとフリーブロックの競合
同時に複数のプロセスが同じセグメントに対してINSERT操作を実行する場合は、フリーブロックをめぐる競合が発生します。INSERT過程でフリーブロックの競合が発生した場合buffer busy waits待機イベントが発生します。もしRAC環境であれば、gc buffer busyイベントやgc current request類の待機イベントが発生します。
Oracleは、フリーブロックの競合を減少させるために、プロセスフリーリスト機能を提供します。例えば10個のプロセスが同時に同じセグメントに対してINSERT操作を実行する場合を想定してましょう。すべてのプロセスが、マスタープロセスからフリーブロックを割り当てられるならば、同じフリーブロックを使用することになり、フリーブロックの競合が発生します。これにより、ほとんどのプロセスに同じフリーブロックのbuffer busy waitsの待機イベントが発生します。一方、FREELISTSプロパティを介して、10個のプロセスフリーリストを作成した場合には、ほとんどのプロセスが自分だけのフリーリストを使用することになります。したがって、各プロセスが異なるフリーブロックを使用することになり、ブロックの競合も著しく減少します。
残念ながらFLMを使用している場合は、テーブルのセグメントのFREELISTS属性のデフォルト値は「1」です。これは1つのフリーリスト(マスターフリーリスト)だけを使用するという意味であり、すべてのプロセスが同じフリーブロックを使用することを意味します。FLMを使用する場合に発生するパフォーマンスの問題の多くの部分が間違っFREELISTS属性値に起因しています。したがって、同時実行性の高いシステム、すなわち同時に多数のプロセスが同じセグメントのINSERT操作を実行するシステムでは、必ずFREELISTS属性の値を適切に付与する必要があるのです。FREELISTS属性値を付与する方法は、以下の通りです。
フリーリストのグループとグローバルフリーブロックの競合
RACのようなマルチインスタンス環境では、グローバルフリーブロックの競合が発生します。プロセスフリーリストを付与して、ローカル・ノードでのフリーブロックの競合を解消したとしても、他のノードが互いに同じフリーブロックを使うような場合、グローバルフリーブロックの競合によってパフォーマンスが低下します。グローバルフリーブロックの競合が発生した場合には、gc buffer busyイベントやgc current request類の待機イベントが発生します。
Oracleは、グローバルフリーブロックの競合解消のためにフリーリストのグループ(Freelist Group)機能を提供します。フリーリストのグループとは、各インスタンスごとに個別のフリーリストを使用することを意味します。例えばフリーリストのグループ数が2個とすれば、1回目のインスタンスはフリーリストのグループ1番を、2回目のインスタンスはフリーリストのグループ2番を使用します。各フリーリストのグループは、独自のマスターフリーリストとプロセスフリーリストを使用します。したがって、各インスタンスの間のようなフリーブロックを使用しないようになり、自然にグローバルフリーブロックの競合が減ります。
各セグメントのフリーリストのグループ数は、FREELIST GROUPSプロパティで指定され、クラスタ内のインスタンスの数だけ指定すればよいのです。例えば、2つのノードからなるRACでグローバルにアクセスされるセグメントについては、次のように属性を指定すればよいです。
フリーリストのグループの一つの欠点は、データの非対称(Data Skew)現象が発生することです。例えばインスタンス1回目では、テーブルに対してINSERT操作のみ実行して、インスタンス2回目では、DELETE操作のみ実行する場合を想定してみましょう。もしフリーリストグループ属性が指定されていない場合、2回目のインスタンスのDELETE操作によって確保されたフリーブロックが1回目のインスタンスのINSERT操作にリサイクルされます。しかし、フリーリストのグループ属性が指定されて、両方のインスタンスがそれぞれ異なるフリーリストのグループを使用している場合には、2回目のインスタンスのDELETE操作によって確保されたフリーブロックが1回目のインスタンスのINSERT操作にリサイクルすることができません。したがって、セグメントの空き容量が十分にもかかわらず、継続的に新しいエクステントを割り当て受ける現象が発生することになるのです。データ非対称現象が発生する場合は、次のとおりです。
データ非対称現象は、フリーリストグループの実装方式により必然的に発生することがフリーリストのグループを使用していないか、またはASSMを使用すること以外に解決策はありません。
次の例は、2つのノードからなるRACシステムでFLMを使用する場合は、フリーリストのグループの設定に基づいて、グローバルフリーブロックの競合がどのように影響を受けるかをテストした結果です。フリーリストのグループをノード数と同じように2に設定した場合、グローバルフリーブロックの競合が顕著に減少を確認することができます。
分析事例
RAC環境における、同じテーブルDMLによる性能低下現象分析
一般的に、RAC環境でのパーティショニングは、パフォーマンス管理の重要な項目です。RAC各Nodeで同じテーブルのDMLを実行する場合には、Single Node環境よりも深刻なパフォーマンスの低下が発生する可能性があります。各Nodeで同じテーブルに対してDelete/ Insert作業が同時に発生した場合の性能低下現象をOracle DBMSの性能診断/分析ツールMaxGauge(マックスゲージ)を活用して分析して見ます。
性能低下区間の確認
パフォーマンスの問題が発生した「RAC02」のインスタンスで収集された稼働履歴ログから日間の推移グラフを確認してみると、「CPU使用率」には、明確な変化がないように見えますが、23時24分〜23時28分の間に「Active Session」の数が急増しすることを容易に確認することができます。
■CPU使用率の推移グラフ

■Active Session数の推移グラフ

■Wait Eventsの推移グラフ(Wait Time)

性能低下区間のズームアップ
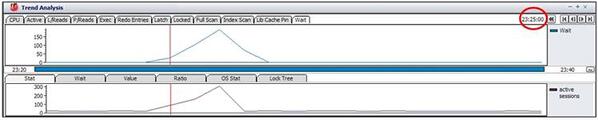
問題区間を簡単に確認するために23時20分〜23時40分のデータを確認した結果23時25分からパフォーマンスの問題が発生しており、23時27分Peak時点であることを知ることができます。
待機イベントの検出および分析
Active Sessionの急増による性能低下(Performance Slow-Down)の原因を究明するために、問題のPeak時点(23時27分)の待機イベント発生内容を確認してみます。
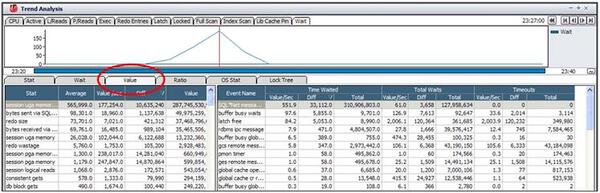
「Value」タブで、同時点のトップ待機イベントを確認した結果、アイドルイベント(SQL* Net message from client、rdbms ipc message)を除いたトップ待機イベントは、buffer busy waits、latch free、buffer busy global CR順となっていることがわかります。
「セッションGrid」画面で、同時点のセッションの待機イベントとSQLを確認してみます。
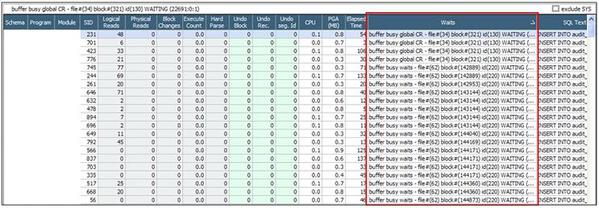
確認の結果、すべてのセッションが同じSQL(Insert文)を実行中であることがわかります。また、buffer busy global CRイベントを待機するセッションはすべて同じfile#(34)block#(321)を待機しています。
buffer busy waitイベントを待機するセッションもほとんど同じfile#、block#を待機しP3(reason code)=220であることを知ることができます。buffer busy global CRイベントはRACと関連している待機イベントなので、RAC関連のパフォーマンス情報を確認してみましょう。
RAC固有のパフォーマンス情報の分析
buffer busy global CRイベントは、相手Nodeからブロックを転送されることと関連する待機イベントなので、global cache current blocks received、global cache cr block received性能指標の推移を確認してみます。イベントは、RACと関連している待機イベントなので、RAC固有のパフォーマンス情報を確認してみることにします。
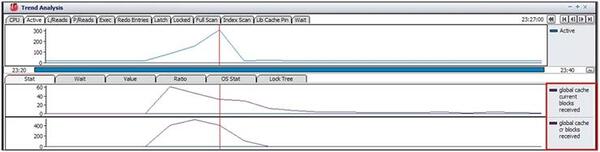
確認の結果、global cache current blocks received数値が最も高い時点から、パフォーマンスの低下が発生しており、性能低下区間の間にglobal cache cr blocks received数値も継続的に高くなっていることがわかります。つまり、この区間に相手ノードから「RAC02」のインスタンスでInsertのために使用するブロックのDMLを実行していることがわかります。
RAC相手ノード実行の分析
「RAC02」のインスタンスで発生したglobal cache current blocks receivedとglobal cache cr blocks receivedが「RAC01」のインスタンスと関連があるかどうかを再確認するために「RAC01」のインスタンスでglobal cache current blocks servedとglobal cache cr blocks served指標の推移を確認してみます。
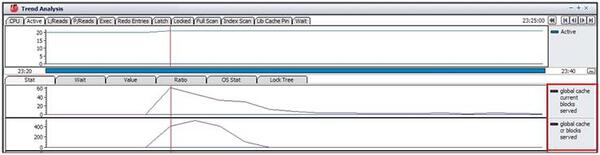
確認の結果、2つの指標間の数値が完全に一致することがわかります。つまり、「RAC01」のインスタンスでは、CURRENTブロックを毎秒60ブロック送り、「RAC02」のインスタンスでは、CURRENTブロックを毎秒60ブロック受けたことを知ることができます。また、「RAC01」のインスタンスでCRブロックを毎秒400ブロック送り、「RAC02」インスタンスでCRブロックを毎秒400ブロック受けたことを知ることができます。今「RAC01」のインスタンスでどのような操作が行われているか調べてみます。
「セッションGrid」で23時25分時点にセッションが実行されたSQLを確認してみます。

確認の結果、1つのセッションで「RAC02」のインスタンスでInsertするテーブルと同じテーブルのDeleteタスクを実行しているのがわかります。
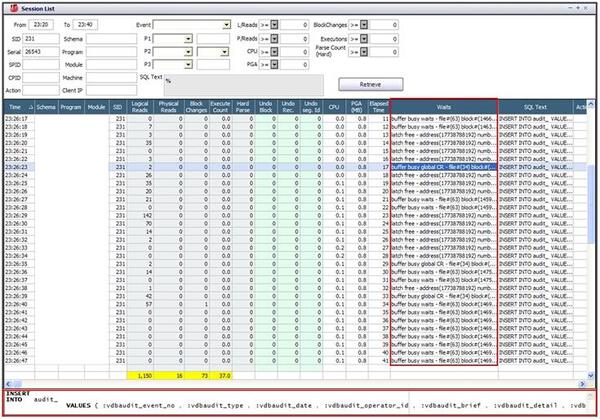
セッションの詳細分析を通じた問題の原因究明
「RAC02」のインスタンスでパフォーマンスの低下を経験しているセッションを分析してみると、Insert文1回を実行(Execute Count=0である)するため、buffer busy global CR、latch free、buffer busy waitsイベントを繰り返し待機しています。また、buffer busy global CRイベントのP1(File#=34)P2(Block#=321)を利用して、DBA_SEGMENTSビューを照会した結果、そのブロックは、テーブルヘッダブロックであることを知ることができます。
結論
今までのMaxGauge分析データを利用して、次のような結論を出すことができます。
つまり、このような現象は、FLM(FreeList Management)環境でFREELIST GROUPSを1に設定したので発生したものと見ることができます。
解決策
・解決策1:FREELIST GROUPSパラメータを2にして、テーブルの再生成を行います。
・解決策2:方式を、ASSM(Automatic Segment Space Management)に変更します。
SQLチューニングのためには、そのSQLがどのように動いていて、データベースにどのように影響しているのか、を把握する必要があります。『MaxGauge』があれば簡単に状況が把握でき、適切なSQLチューニングができるようになります。
『MaxGauge』の資料はこちらから。

