
PostgreSQL Architecture - 5. SQL 処理過程
https://blog.ex-em.com/1653
本稿では、PostgreSQLのSQL処理過程について見ていくことにしましょう。
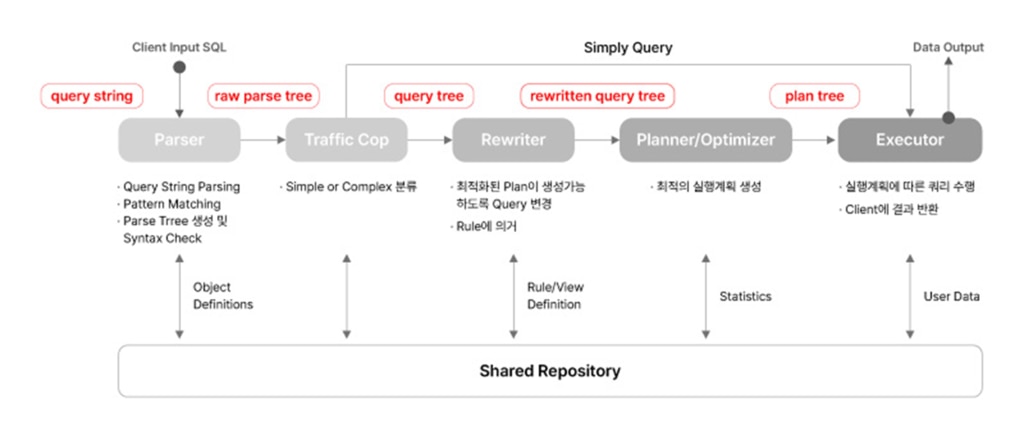
postgresプロセスは、クライアントからSQL(Query string)を受信すると、以下の5つのプロセスを経てSQLを処理し、その結果をクライアントに返します。 各コースでは、文法チェックおよび意味分析、最適化作業などを行い、詳細な内容をそれぞれ確認してみましょう。
Parser
Parsing段階はSQL処理過程の最初の段階で、Query構文を分析してSyntax Errorをチェックし、Parse Treeを生成します。 該当段階ではSystem Catalogを参照しないため、個別要素に対する意味分析(Semantic)ができず、単純な文法チェック(Syntax)のみを行います。
📌 システムカタログ(System Catalog)は、テーブル、Row、Schemaなどのメタデータ情報を保存する場所で、他のRDBMSではData Dictionaryと表記することもあります。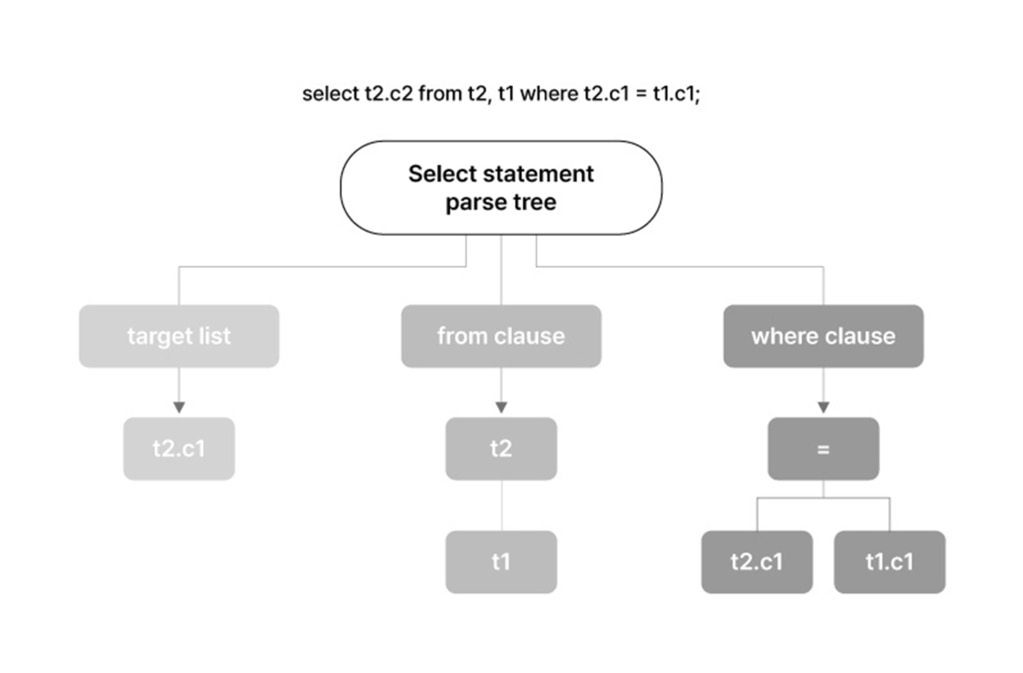
Traffic Cop (Analyzer)
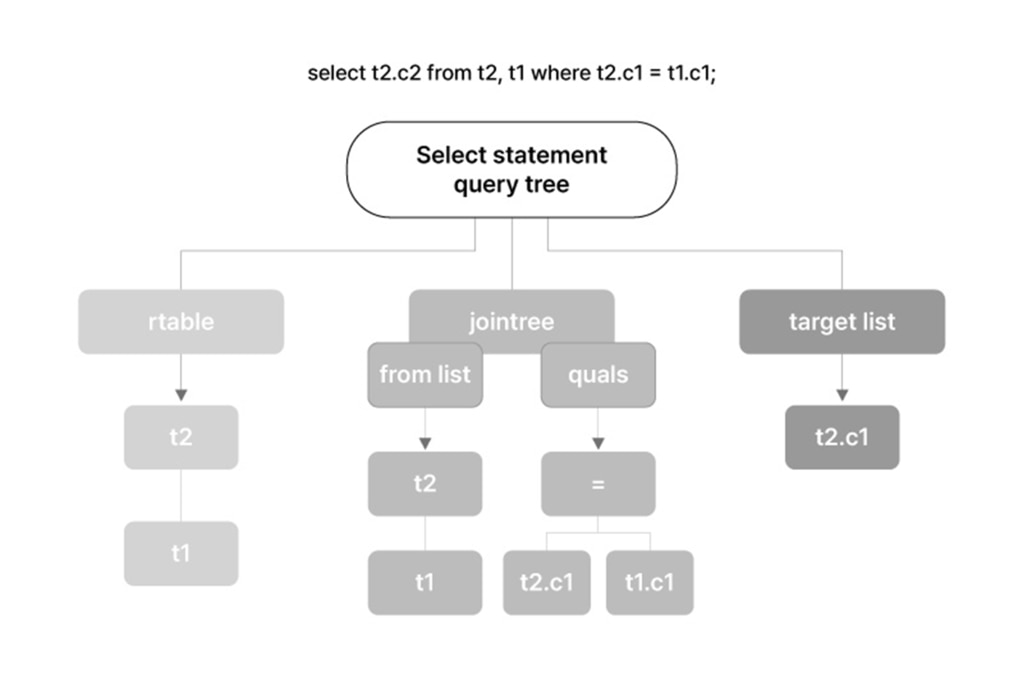
Parser段階で生成されたParse treeの意味を分析してQuery Treeを生成します。 SQLが参照するテーブル、関数、および演算子を理解するための意味分析(Semantic)過程を実行します。 Query Rewriteや最適化が必要ないSimple Queryの場合、すぐにExecutor段階に進みます。
- Simple Query : create, drop, alter, vacuumなどの制御構文
- Complex Query:select、joinのようなその他のQuery
Rewriter
Traffic Cop段階で生成されたQuery Treeに事前定義されたRuleを適用してQueryを単純化します。 入力、出力ともにQuery Treeです。
Query Rewrite 技法
■ Subquery Collapse
- SubqueryをMain Queryに併合します。(Subquery Unnest)
■ View Merging
- ViewまたはInline Viewを開いてテーブル間のJoinに変更します。
- View Mergingが可能な場合、テーブル間の様々な結合方法及び順序を選択することができます。
- Simple Viewは常にView Mergingに成功しますが、Complex Viewは常に失敗します。
■ JPPD (Join Predicate Push-Down)
- View Mergingが失敗した場合、Join PredicateをView内部にプッシュダウンする方法で
- Join Predicateは定数条件でなければPush Downができません。
- Lateral Viewを使用する必要があります。
📌 Simple View と Complex View
View内部にGROUP BY、DISTINCTのようなAggregationを使用していない場合をSimpleViewといい、反対の場合をComplexViewといいます。Planner (Optimizer)
最適な実行計画を作成するステップです。 選択可能なすべてのPlan Pathを作成して各PathのCostを計算し、その中で最も少ないCostを持つPlanを選択します。 この時、主な決定事項(Key Decisions)としてはScan及びJoin Methodがあります。
- Path単位の基準は、SCAN、JOIN、GROUP BY、SORTING、AGGREGATIONなどがあります。
- Costは、System Catalogに保存された統計情報に基づいています。 (pg_class, pg_statistics)
key Decisions
Scan Method
■ Sequential Scan
- テーブルをFull Scanしながらレコードを読みます。
- インデックスが存在しない、または選択できないとき、Sequential Scanを選択します。
■ Bitmap Index Scan
- テーブルへのランダムアクセスの回数を減らすために考案された方法です。
- インデックスカラムに対するテーブルレコードの整列状態を
Correlationといい、Correlationが良ければIndex Scanを、悪ければBitmap Index Scan方式を選択します。 - Bitmap Index Scan方式は、ブロック番号順にブロックを整列した後、Accessします。 そのため、Index Keyの順に出力されません。 (整列が保障されません.)
■ Index Scan
- Index Leaf Blockに保存されたキーを利用してレコードを読みます。
- レコードの並び具合によってBlock Accessの回数が大きく異なります。
- Index Keyの順に出力されます。 (整列が保障されます.)
Join Method
■ Nested Loop Join
• Outer(Driving)テーブルをAccessした後、Inner(Driven)テーブルを繰り返しAccessし、結合を行います。
■ Hash Join
• Innerテーブルのジョインキーを利用してHash Tableを生成し、OuterテーブルをAccessしながらHash Table結果と結合を実行します。
■ Sort Merge Join
• OuterテーブルとInnerテーブルからそれぞれ条件を満たすレコードを抽出した後、Joinキーを基準に整列作業を行います。
• 整列された結果を利用して結合を行い、結合に成功したら抽出バッファに入れてから出力します。
📌 CorrelationはOracleのClustering Factorと同じ概念で、インデックスとテーブルの類似度を示します。Executor
実行計画に従ってQueryを実行し、その結果をクライアントに伝えます。クエリを処理する際、あらかじめ割り当てられたtemp_buffersやwork_memのような一部のメモリ領域を使用し、必要に応じて一時ファイル(Temp)を生成することができます。



