Oracle SQLチューニング Season2(第30回) 第6章 大量のデータ処理性能改善方法 (3/5)
今回のSQLチューニング 2nd Season(第30回)は「第6章 大量のデータ処理性能改善方法」と題しまして計5回シリーズの第3回目として解説していきます。
今回のテーマは「Parallel Processing戦略」です。
では、早速始めましょう。
6.3 Parallel Processing戦略
Parallel Processingは、大量のデータを扱う業務で必ず必要な処理方式です。
広いスキャン範囲をHintで指定したDegree値だけのセッションが同時に作業量を分けて処理を行います。
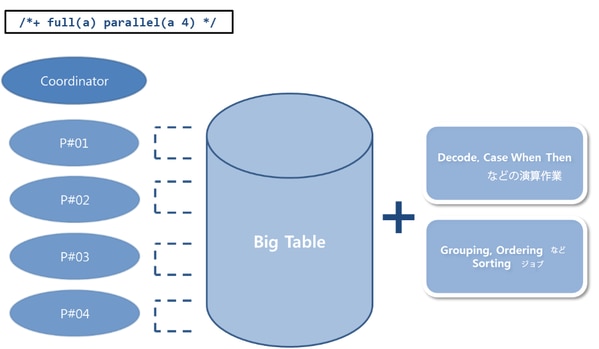
[図 6-5] Parallel Processing
Parallel Processingの処理方法を図式化すると上のようになります。一つのCoordinatorセッションと複数のSlaveセッションが目立ちます。
Coordinatorセッションは、Parallel Processingの作業主体を意味し、実際に作業を実行するセッションをSlaveセッションと言います。Coordinatorセッションは、Slaveセッションの作業範囲の指定と、そのセッションにおける作業結果を受け取ってユーザーに渡す役割などを担っています。
次にSlaveセッションは、指定された範囲のScanをそれぞれ実行します。
尚、特異な点については、Decode, Groupingなどの演算やソート作業もこれらのセッション作業のカテゴリに含まれています。
大量のデータをAccessしなければならないと言う業務の特性上、Grouping、演算作業が必然的に伴います。
ユーザーは演算後、Summarizedされた結果値が必要なのであって、数百万件のデータをすべて抽出して直接確認する理由などは存在しません。したがって、I/Oの並列処理だけでなく、各種演算及びGroping作業も並列処理が可能なParallel Processingの適用は、より多様な業務に戦略的に適用することができるでしょう。
今回のテーマを通じて、Parallel Processingについての偏見を克服し、積極的に活用できるきっかけとなればと考えています。
6.3.1 Parallel Processingに関する誤解
Q: ここで読者のみなさんに3つの質問をしたいと思います。
- Parallel Processingは、Batch Program作業のみに限定して使用すべきか?
- CPU、MemoryなどのResource面で過負荷を引き起こすか?
- 常識的にParallel Processingはなるべく使わない方が良いのか?
上記の3つの質問に対する読者のみなさんの答えはどうでしょうか?
仕事の特性上、Database関連職種の様々な人に会って多くの話をするたびに、Parallel Processingについて少なからずの人が多少の偏見を持っているという印象を受けることが多くあります。
それはもちろん、ほんの数年前までなら上記のような質問にすべて’はい’と答えることに躊躇はしなかったでしょう。しかし、結論から言えば、その考えは大きく変わりました。
大量のデータを扱う業務の増加、Big Data時代の到来を控えている現在の時点では、Parallel ProcessingはOnline、Batchの区分を置く必要がなく、更には実行される時間帯の制約を受ける必要もありません。
すなわち、データの大量化に比例して日々発展するハードウェア装備の効率を最大化して使用するためには、Parallel Processingのニーズに応じた拡大適用を再考すべき時ではないかと思うのです。
Parallel Processingの必要性とどのような場合であれば適用を検討できるのか?について詳しく説明する事を目的として、A社のReporting業務を主に行う特定のDatabase(RPTDB)の事例を通じて説明していきます。
- RPTDBの平均CPU使用率は40%以内である。
- RPTDBで実行されるSQLはほとんどReport業務の特性上、応答時間の非効率が発生する。
- 対象SQLは大量のデータを対象として、ほとんどの集合関数、統計関数などが使用される。
- RPTDBのハードウェア性能はかなり良い方である。
業務の特性上、上記のような現象が目撃され、主なStatのグラフ推移は以下のような形を示します。
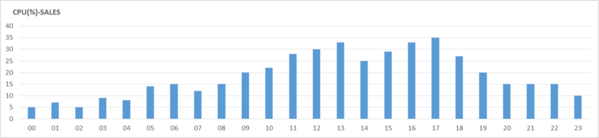
[図 6-6] RPTDB の時間別平均 CPU 使用率の推移
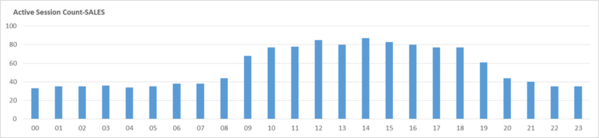
[図6-7] RPTDB の時間別平均 Active Session Count
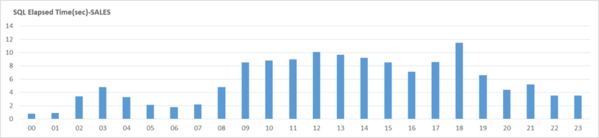
[図 6-8] RPTDB の時間別平均 SQL Elapsed Time
上記の性能グラフ(3種類)を分析してみると、業務時間帯にLong Running SQLによる応答時間の低下と、Active Sessionが増加する現象が共通して現れているのがわかります。
その一方で、CPU使用率については比較的に安定した状況で分析することが可能となっています。
以下は、A社のRPTDBでよく実行されるSQLの例です。
上記SQLの実行時間は約15秒かかり、約135万BlockのI/Oが発生しました。
業務の特性上、当該テーブルのTable Full Scanは最も効率的なScan方法であるにもかかわらず、RPT_SEASONテーブルに対して約104万件程度をIndex Scan及びTable Random Accessを実行し、大きな非効率が発生したことがわかります。
この時、そのSQLをTable Full ScanとParallel Processingを誘導した場合、結果はどうなるでしょうか?
最も大きな非効率を引き起こしたRPT_SEASONテーブルのAccess方法とParallel Processingの適用によって、15秒程度で実行されていたSQLが2秒の応答時間で十分だったことがわかりました。
もちろん、上記SQLの業務上の重要度が高く、実行回数が頻繁ではないため、実際の適用へとつながった訳です。
但し、すべての場合においてParallel Processingを適用することはできません。
同時性が高いSQLや、実行回数が多いSQLの場合であれば、Parallel Processingを適用するのは無理です。
しかし、上記の事例のようにLong Running SQLの場合において、CPUなどのリソースに余裕がある場合については、十分に積極的な適用を検討してみる価値があると考えます。
6.3.2 カバーインデックス
Parallel ProcessingとCovering Indexnには、どんな関係があるのでしょうか?・・・
一見、お互いに大きな関係がないように見えます。しかし、Parallel Processingの戦略的な性能改善の面においては深い関係があります。
ではまず、Covering Indexが何なのか?について説明します。

[図 6-9] 一般的な Index Scan
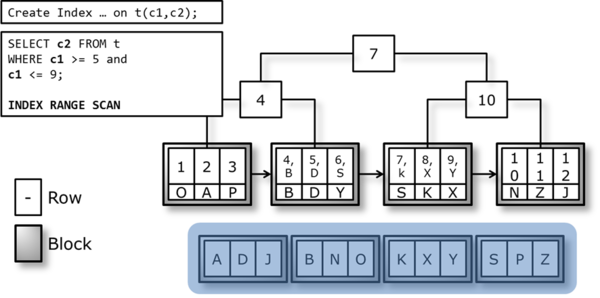
[図 6-10] Covering Index Scan
Note. IndexはIndex Key Columnの値を保存しているので、SQLで必要な全てのカラムを対象にIndexを生成すると、Table Random Accessオペレーションが発生しません。これをCovering Indexといいます。
一般的にIndex ScanとCovering Index Scanの決定的な違いは、Table Random Accessオペレーションの有無です。Covering Indexは、Table Random Accessの過程を経ずにIndex BlockのみAccessしても、目的の情報を抽出できることが存在の核心的な理由です。
ここで話をもう1度戻します。
Covering IndexとParallel Processingはどのような関係があるでしょうか?
広い範囲を処理するSQLでのIndex Scan性能が保証できない理由は、Disk I/Oが必然的に含まれており、その量が多くなればなるほど応答速度の低下は大きくなるからです。
当該業務にAccessする広い範囲での処理対象は、TableのSQLに使用されるColumnsを全てIndexで構成するCovering Indexを作成します。
当該IndexのScan方式をIndex Fast Full Scanに誘導する一方で、Parallel Processingを実行するようにヒントを与えてやれば、性能面において劇的な逆転勝利となる結果を引き出すことができます。
上記のSQLは、約3.5GBのSALES_INFOテーブルをFull Scanし、約9,000万件に対するデータをGroupingするのに処理時間のほとんどを費やしていたのがわかります。
ここで、SQLを分析してみると、実際にデータ抽出に必要なSALES_INFOテーブルのカラムは、AMOUNT_SOLD、CUST_IDの2つのカラムに過ぎず、そのカラムを含むIndexを生成してSizeをチェックしてみると、約1.9 GBであることが分かりました。そして、その結果から下記のような新規Indexを生成しました。
結果として、約7秒程度の応答速度を記録しました。
これは従来の46秒に比べて、大きな改善効果があることがわかります。
もちろん、Covering Indexの生成の是非を常にParallel Processingと結びつける必要はありません。
広範囲処理のためだけではなく、必要に応じたCovering Indexの生成はいくらでも検討することができます。
但し、上記のように Covering Index、Parallel Processing を同時に使用する形で性能改善効果を見出そうとする場合には、Covering Index 生成時に必要な Column の数と対象Tableの既に生成されているIndexの数などを考慮する必要があります。又、あまりにも多くのColumnが生成対象に含まれる場合、当該Tableのサイズに匹敵するIndexセグメントが生成されることを意味し、これをIndex Fast Full ScanすることとTable Full Scanすることを比較した場合、得られる性能上の利得は微々たるものとなってしまう為、Covering Indexの合理的な生成事由にはなりません。
また、すでに多数のIndexを保有しているテーブルにCovering Indexを生成することは、DML業務に悪影響を与えるなど、他のSide Effectが発生する可能性があります。その点においては、やはりその必要性に議論の余地があると考えます。
その一方、必要性に対する十分な検証後であれば、Covering Indexの生成と同時に続く『Memory Caching戦略』のトピックを参考として、当該IndexをMemory内に常駐させ、その効果をさらに最大化する方法も用意することができるでしょう。
6.3.3 インメモリPQ
Parallel Processingを性能の観点からさらに輝かせることができる要素は、In-Memory PQ機能です。
Oracle11gバージョンからサポートされたこの機能は、Parallel Processingの対象となるBlockがMemory内にCachingされている場合、CachedされたBlockをそのまま読み込んで処理する機能を言います。
Parallel ProcessingのI/O方式がDirect Path I/O方式のみ可能であったと知っていた読者には非常に興味深い内容でした。
参考までに・・・
Oracle 10gバージョンまでは、Parallel ProcessingはDirect Path I/O 方式のみで行われていました。
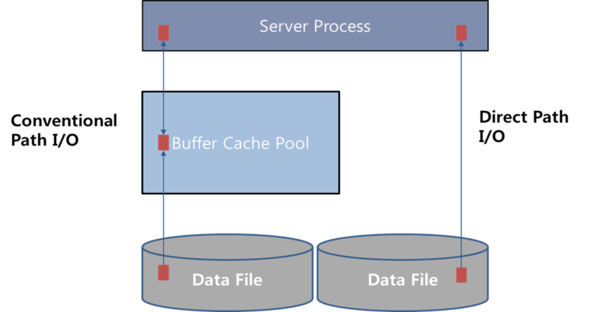
[図6-11] Conventional Path I/O vs. Direct Path I/O
Direct Path I/O は、 [図 6-11] のように Buffer Cache を通さずに Disk にある Block をそのまま Server Process が読み込む方式で実行されます。つまり、Parallel Processing は基本的に Disk I/O をベースにしているということです。
Disk I/Oを含むかどうか?によって、その応答速度の差が発生する事をこれまで何度も強調したことを覚えていれば、このような方式が効率的だと断定するには何かが足りないでしょう。
しかし、In-Memory PQ方式が導入され、この不足部分を埋めることができます。
Buffer CacheあるいはKeep Buffer CacheなどMemory内にCachingされたBlockに限ってMemory I/Oが行われるため、PQ対象セグメント全体をDisk I/Oするよりも速い性能を発揮し、場合によってはPQ対象セグメント全体がMemory内にCachingされている場合、より良い効果を見ることができるでしょう。
実際にIn-Memory PQ機能による性能差があるかどうか、テストを通じて確認してみましょう。
テストテーブルの生成後、そのセグメントがメモリにCachingされていない状況の実行結果です。
次に、そのテーブルをメモリ内にCachingした後、同じSQLを実行した場合の性能変化について見てみましょう。
該当セグメントをParallel Processingで実行した結果、I/O方式によって性能差が発生することが確認できました。
Direct Path I/O を実行した一般的な Parallel Processing の場合には、5秒以上の実行時間を記録したのに対し、In-Memory I/O を実行した Parallel Processing は0.4秒程度の実行時間を記録しました。
Parallel Processingの積極的な使用は、大量のデータを扱う業務に欠かせない要素です。
しかし、それだけに制約が多いのも事実です。
実際、Parallel Processingの実行を根本的に防止する運用をしているDatabaseも存在します。
公式のように普遍的に適用できないという限界と現実があることが残念ではありますが今後、その必要性が浮き彫りになると同時に、より頻繁に使用されることは間違いないのではないか?思います。
業務の重要度を考慮し、適用可能な範囲内で段階的に適用していけば、それによって発生する可能性のあるSide Effectを最小限に抑え、否定的な認識の再考も自然に行われることになるでしょう。

