Oracle SQLチューニング Season2(第31回)第6章 大量のデータ処理性能改善方法 (4/5)
今回のSQLチューニング 2nd Season(第31回)は「第6章 大量のデータ処理性能改善方法」と題しまして計5回シリーズの第4回目として解説していきます。今回のテーマは「Memory Caching戦略」です。
では、早速始めましょう。
大量のデータを扱うSQLの性能に関する最大の話題となるのは、Disk I/Oの有無です。
Index Scan、Table Full ScanともにDisk I/Oがどれだけ発生するかによって応答速度の差が大きくなります。
したがって、Memory内にCaching戦略を様々な方面で積極的に活用することにより性能改善を図る必要があります。
当たり前の話を強調してしまう側面がありますが、時にはこの当たり前の話を見落として通り過ぎてしまう事が多くあります。
今回のテーマを通じて、Memory Cachingを積極的に検討できる事案に対する理解を基に、適用まで繋がる機会になれば幸いです。
6.4 Keep Bufferの活用
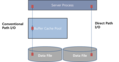
Memory Caching戦略において最も基本的かつ重要な部分はKeep Buffer Poolの活用です。
OracleのDefault Buffer PoolではなくKeep Buffer Poolを追加で構成して、大量のデータ照会に対して頻繁にアクセスするセグメントをKeep Buffer PoolにCachingしてDisk I/Oの発生余地を与えないことが核心です。
6.4.1 基本概念と使用方法
Keep Bufferの使用目的は、Buffer Cacheの目的と同様に、Objectをメモリに常駐させることで、物理的なI/Oを避けることにあります。
Keep Buffer PoolとDefault Buffer PoolがデータブロックをCacheしたり、Flushする時、異なるアルゴリズムを使用しません。
それでも、一つだったBuffer Cache領域をMultiple Buffer Poolに分けて使用するのは、業務の特性上、大量のデータ照会時に頻繁にアクセスするセグメントのMemory Cachingをするためです。
Keep Bufferのメモリ空間は、Sequentially管理されます。
一度Keepされたセグメントは、Keep Bufferのメモリ空間を全て割り当てるまでメモリに維持され、Keep Buffer空間を全て割り当てるようになると、最も古いブロックからDefault Poolに押し出されます。
そのため、Keep対象のセグメントのサイズを正確に計算してKeep Bufferのサイズを適切に割り当てる必要があります。
6.4.1.1 KEEP Bufferの使用手順
Keep Bufferは、次のような順序で使用していきます。
- Keep対象を選定する
- OS Memory & SGAスペースの確認
- Keep Bufferの設定
- テーブル/Index属性の変更
- テーブル/Index Keeping
- Keep効率チェック
- Keep対象選定基準
(1)Keep対象を選定する
Keep対象の選定をする場合、明確な基準点は存在しません。
実際の業務を考慮しつつ、各DBの運営環境に合った対象を選定しなければなりません。
もしKeep対象が非常に頻繁にアクセスされるBlockなのであれば、基本的なDefault Bufferを使ってもCacheされている可能性が高いものの、このような場合ではKeep Bufferの使用が性能上の利点をもたらさないことになります。
逆に、頻繁に使用されないBlockをKeep Bufferに常駐させると、使用しないメモリを持っていることになるので、全体的な性能を低下させる要因になることもあります。
したがって、Keep対象を選定するにあたっては、実際の業務を考慮することが必須となります。
例えば、一日の平均実行回数が少ないプログラムですが、業務の重要度が高く実行時間を短縮しなければならない場合や、多くの業務を処理する時間帯に必ず実行されなければならないのに、多くのI/Oのためにボトルネック現象を起こしてシステム全体に悪影響を与えるプログラムなどがあります。
このようなプログラムが使う Object が Keep 対象となることがあります。
しかし、上記のような業務プログラムに使用されるすべてのセグメントをKeep Bufferに常駐させることはできません。現実的に物理的なメモリ空間の使用が制限されるため、Keep Bufferに常駐させる対象は、各Databaseの運営環境を考慮して選定しなければならなくなります。
選定基準[1] プログラムの重要度
Keep対象を選定する上で最も重要な部分は、そのセグメントを照会する業務プログラムの重要度です。そのプログラムが重要でなければ、Keep Bufferを使用する必要はありません。逆に、そのセグメントを照会するプログラムの重要度が非常に高く、これにより実行時間をできるだけ短縮しなければならない場合は、プログラムの実行頻度に関係なくKeep対象への選定を検討することができます。
選定基準[2] セグメントサイズ
セグメントのサイズが一定ではなく、過度に大きくなるセグメントはKeep Bufferの効率を低下させる可能性があります。Keepされたセグメントは、Keep Bufferの容量が不足すると、古いBlockからDefault Bufferに押されることになりますが、サイズが大きくなり続けるセグメントがKeep Bufferに存在する場合、Keep Buffer内に競合を誘発し、他のセグメントを照会するプログラムの性能低下をもたらすことになるからです。 したがって、一定のサイズまたはサイズの変化が激しくなく、最大サイズが一定レベル以下である場合のセグメントを選定することが望ましいことになります。例えば、「最大サイズが10万Block以下のセグメント」のような基準を各Databaseの性格に合わせて定めることができます。
ただし、Databaseの運営状況によってKeep Buffer PoolのSizeに差がある場合があります。物理的に確保できるメモリ容量が不足する場合もあり、逆に十分なスペースをKeep Buffer Poolに割り当てることができる場合には、セグメントのサイズが選定基準で重要な基準にならない場合があります。
しかし、ほとんどの場合は限られたスペースを効率的に使用する必要があるため、業務上Partitioningが可能であれば、積極的にPartitioningを計画し、主照会条件に該当するPartition Tableだけを選択的にKeep対象に指定する戦略も必要です。
選定基準[3] Table Full Scan & Index Full Scan & Index Fast Full Scan , Disk I/O
Keep Bufferにキャッシュされたセグメントを照会するとき、その効率が最大化される場合は、大量のデータを処理する場合です。 したがって、Table Full Scan, Index Fast Full Scanなどで処理されるセグメントがその対象に含まれることがあり、Disk I/O が非常に高いセグメントも対象に含まれることがあります。以下は、紹介した選定基準に合う対象選定スクリプトの例です。
KEEP対象選定スクリプト(例) :
(2)Keep Bufferの設定
Keep Bufferの設定は、Keep BufferのサイズとSGAの空き容量に応じて、Online作業またはOffline作業で行います。
下記のスクリプトは、SGA領域のメモリ管理を手動で行う場合を基に作成しました。
Keep Buffer設定 Script
[ Keep BufferのサイズがSGAのFreeスペースより小さい場合 Online (Keep Buffer 100M) ]
[Keep BufferのサイズがSGAのFreeスペースより大きい場合(Keep Buffer 300M) ]
1. SGA全体のサイズを大きくした後、KEEP Bufferを割り当てるOffline作業が必要です。
2.SGAの他の領域のサイズを小さくした後、Keep Bufferを割り当てる場合、Online作業が可能。
* Online状態で変更可能 Parameter抽出
(3) テーブル/Index属性の変更
Keep対象に選定されたセグメントが決定されると、以下のようなコマンドを実行することによって、Keep Buffer Poolに実質的にCachingすることができます。
テーブル/Index属性変更Script例
[一般テーブル/Index属性の変更]
(4)テーブル/Index Caching
Keepに設定したセグメントは、そのセグメントにアクセスする最初のSQL実行時に初めてKeep Buffer PoolにCachingが行われます。
したがって、最初のセグメントをLoadingする時にはDisk I/Oが発生します。
それ以降は、Keep Buffer Poolに該当セグメントブロックがAge Outなどの理由でCachingされない状況がなければ、Disk I/Oは発生しないものと考えて良いでしょう。
もし、Keep対象セグメントにアクセスするすべての業務に対して、Disk I/Oの発生を根本的に封鎖したい場合には、定期的に該当セグメントをTable Full ScanあるいはIndex Fast Full ScanでKeep BufferにLoadingする別のプログラムを実行する方法を導入する必要があります。
この課題に関しての詳細については次回、『Keep Bufferのメンテナンスと常駐戦略』の部分で説明します。
(5) Keep Bufferの効率判断
Keep Bufferの使用については明確な基準が決まっているわけではなく、運用環境によって違いが存在します。
したがって、すべての運用環境で同じ方法での効率を判断するのにはやや無理があります。
しかし、次のような資料がKeep Bufferの効率を判断する根拠資料として参考の価値があります。
Keep Buffer Size & Hit Ratioスクリプト :
もし、Keep Bufferを使用するセグメントサイズの合計がKeep Bufferのサイズより小さい場合、そのSegmentのサイズがこれ以上増加しない場合、一度Keep領域にキャッシュされたセグメントのCache Hit Ratioは、100%に達することになるでしょう。
一方、Keep Bufferのサイズがその領域を使用するSegmentsのサイズより小さい場合、Keep Buffer領域で競合が発生し、それによりPhysical I/Oが発生し、Cache Hit Ratioが低下することがあります。
この時、Keep Bufferのサイズをさらに大きくしたり、重要度の低いセグメントを調査して必要ない場合は、そのセグメントをKeep Buffer PoolのCaching対象から除外するなどの管理方法が必要となってきます。
次のスクリプトを使えば、DBA_HIST_SEG_STATビューを照会してSegment照会時に発生するI/O発生量に対するAWR情報を確認してSegment別の効率を判断することができます。
Segment I/O 関連スクリプト :
6.4.2 Keep Bufferのメンテナンスと常駐戦略
Keep Buffer Poolを構成して使用すると、Disk I/O発生による非効率を減らすことができるというメリットがあるため、大量のデータを扱う業務においては、かなり魅力的に感じられるでしょう。
効果を実感することができれば、拡張や積極的な使用は自然に続くでしょう。
OS上のFree Memoryに余裕があれば、Keep Buffer PoolのSizeを増加させながら、必要なセグメントをCachingする運営をすることになるでしょう。
しかし、細心の管理が行われず、セグメントのKeep属性の適用を乱発すると、効率的に維持されていたKeep Buffer Poolに競合が発生し、それに伴う性能低下現象が続くことは明らかです。
リソースは常に限られているので、Memoryを無限に増加させることには限界があり、一定レベルの増加させることが可能であったとしても、セグメントサイズも時間に比例して増加していくため、根本的な解決策とはなりません。
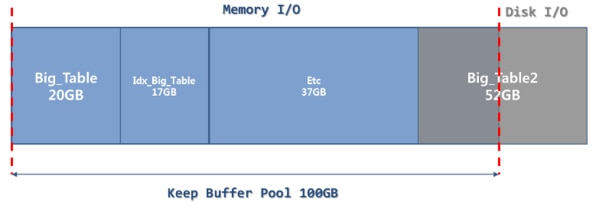
[図6-12] Keep Buffer Pool競合
この様なケースが発生した場合に必要となる概念こそがメンテナンス戦略です。
このメンテナンス戦略において一番重要な要素は、先に紹介した積極的なPartitioning戦略と共 に、業務の重要度に応じて選択的にセグメントをKeep Buffer PoolにCachingする意思決定です。
例えば、業務の特性上、照会期間が一定レベルで決まっている場合、そのテーブルをPartitioningして該当期間のPartition Table、あるいはPartition Indexだけを選択的にCachingすれば、全セグメントをKeep対象に選定する必要がなく、Keep対象セグメントSizeの総和を減らすことに大きく貢献するでしょう。
Partition Tableへの転換が不可能な場合、その代替として提示したGlobal Partitioned Indexもこの対象として含めることができ、この方法でさえも適当な方法ではない場合には、対象テーブル全体、またはIndex全体のセグメントをKeep対象として指定しますが、そのセグメントの増加量は継続的にチェックする方法が伴わなければならないでしょう。
◆ ここで一旦、メンテナンス戦略をまとめてみると・・・
- 業務重要度に応じたCaching対象セグメントの選定
- 該当セグメントの積極的なPartitioning案の策定
- 1. Partition Table/Index : 業務特性及びAccess Patternを考慮した選別的Keepinging
- 2. Non Partition Table/Index : 業務重要度把握及び当該セグメントの周期的なSize増加量チェック
- 新規作成対象セグメントの場合、Caching対象かどうかを決定します。
- Keep Buffer Pool効率レポート
- すべての事案を管理する自動化プロシージャの作成及び実行
当該Databaseの業務特性に適合するように効率的なメンテナンス戦略を構成した場合、限られたKeep Buffer Poolスペースをある程度スムーズに使用することができるでしょう。
Note.:メンテナンス戦略と関連して紹介した考慮事項をすべての環境で必ず共通的に適用しなければならないという意味ではありません。考慮すべき要素や方法はいくらでも各環境に合わせて新しい戦略を策定するのが自然であり、紹介した事項はあくまで一般的な例示に過ぎないということ。
メンテナンス戦略と同時に考慮すべき事項があります。
それは、セグメントのKeep Buffer Pool常駐戦略(以下、常駐戦略)です。
常駐戦略とは文字通り、Keep対象に選定した対象セグメントがKeep Buffer Pool内で押し出されないようにする戦略が必要であることを意味します。
合理的なメンテナンス戦略を立てて運営に細心の注意を払ったとしても、Keep Buffer Poolのサイズはある程度限定されており、セグメントのSize増加は必然的となるため、業務の環境や重要度は常に変更される可能性があります。
このような伏兵たちによって、Keep Bufferの効率が減少する可能性がある状況に対しては対処が必要となってきます。
常駐戦略の核心は、業務の重要度です。
大量のデータが伴うことを前提として、常に迅速な応答速度が要求される優先順位の高い業務がある場合、当該SQLがAccessするセグメントは、必ずMemory I/Oで実行されなければ、要求されるレベルの応答速度が期待できることでしょう。したがって、これらがKeep Buffer Pool内で押し出されないようにする運営方法が必要です。
Keep Buffer Poolも頻繁にAccessされるほどKeep Buffer内に常駐する確率が高くなることを利用して、業務重要度に相当するセグメントを定期的にAccessする戦略こそが、筆者が言う常駐戦略の核心です。
◆ 常駐戦略についてまとめてみると・・・
- 業務重要度の把握
- 業務重要度に対応するセグメントリストの整理
- 該当セグメントの周期的Access
- すべての事案を管理する自動化プロシージャの作成及び実行
メンテナンス戦略と同様に、常駐戦略も上記の考慮事項が必ず伴わなければならないという意味ではありません。
当該DatabaseのCPU使用率などのリソースに余裕があり、迅速な応答時間が保証されなければならない業務がある場合において初めて検討する価値がある事項であるのです。
上記の2つの戦略に共通して入力した項目は、自動化プロシージャの作成と実行の部分です。
自動化プロシージャが必要な理由は、いちいち管理するのが面倒なことがありますが、引き継ぎが必要となる場合なが発生した場合、運営全般において様々な柔軟な対応が可能となるからです。
以下は、特定の状況を想定してメンテナンス戦略と常駐戦略を策定し、その手順について作成した例です。
- Partition Tableは月単位、週単位のPartition Tableのみ存在。
- 月単位のPartition Tableの照会条件は常に前月のデータが対象となる。
- 週単位のPartition Tableの照会条件は常に前週のデータが対象となる。
ADM_KEEP_BUFFER_MANAGERスクリプト(Keep対象セグメント管理)
ADM_KEEP_BUFFER_MANAGER プロシージャはPartition Tableや一般テーブル、IndexなどのKeep対象セグメントにKeep属性を付与し、既存のKeep属性で指定されていたセグメントのDefault属性を付与する役割をする例です。
上記のプロシージャの使用を想定した状況は、Partition Tableの場合、月別、週別のPartition周期を把握し、Keep属性を付与する対象は、現在の時点を基準に、それぞれ前週、前月に該当するセグメントがその対象になるようにしています。一方、照会条件から外れる既存のKeep対象セグメントを再びDefault属性に変更するロジックも含まれています。
Partition Table以外の一般テーブルやIndexの場合は、そのセグメントのサイズを測定するロジックが含まれていますが、これはそのセグメントのサイズが急激に増加する場合、これによるKeep Buffer Pool内の競合が発生する可能性があるので、これに備えるためです。
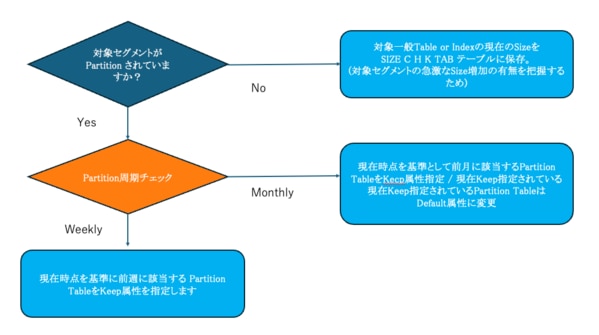
図 6-13] Keep Buffer Poolの効率性を維持する方法
簡単な状況について想定した例ですが、このように運営すれば、Keep Buffer Poolの効用を最大限に活用することができるでしょう。
管理するポイントが増えるのは事実ですが、プロシージャの実行でほとんど自動化されているので、簡単な管理が可能でしょう。
もし業務の重要度が変更されたり、新しいテーブルなどが追加されたら、その内容を再度ADM_KEEP_BUFFER_MANAGERプロシージャに登録するだけで良くなります。
ADM_KEEP_BUFFER_LOADINGスクリプト(Keep target segment Loading) :
ADM_KEEP_BUFFER_LOADING プロシージャは、Keep対象として登録されたセグメントを対象に、一定の周期ごとにそのセグメントの Full Scan を実行する役割を担当します。
このプロシージャの存在の目的は、常にKeep Buffer Poolが設定されたサイズに合わせて運営されるという保証がありません。
それは、もしKeep Buffer Poolの設定されたサイズ以上のKeep属性が指定されたセグメントが存在する状況であれば、必然的にKeep Buffer Pool内に競合が発生する余地があるからです。
したがって、業務の重要度に応じて、上記のプロシージャにFull Scan対象セグメントを登録し、定期的にKeep Buffer PoolにCachingされるように誘導すると、重要な業務を遂行するSQLの性能がDisk I/Oの含有による応答速度の低下現象を未然に防ぐことができます。
6.5 Result Cacheの活用
Memory Caching戦略でResult Cacheを活用することは、「画竜点睛」を施すようなものだと思います。
もちろん、運用可能な環境であれば話は別ですが・・・。
(※ 画竜点睛 [がりょうてんせい]:物事の最も大切な部分のこと)
ここで何故、少し大げさな表現を使ったのか?と言うと、パフォーマンスの面においてどの方法よりも速く、ヒントだけで簡単に適用することができるからです。
「こんな魔法のような方法があったなんて…」
Result Cacheを活用することは「画竜点睛」や「魔法」といった表現が違和感なく使えるほど、高速なパフォーマンスを保証します。
しかしその一方で、Result Cacheの動作原理を正しく理解していなかったり、使用時の注意事項を理解していなければ、パフォーマンス改善戦略として使用することができません。
本テーマを通じて、Result Cacheの動作原理、機能設定及び解除方法、使用時の注意事項について学び、どのような場合に効果的に使用できるのか?事例を通じて理解を進めることで、性能改善戦略として使用できる機会となれば幸いです。
6.5.1 Result Cache 動作原理
一般的にSQLが実行され、Buffer Cacheに目的のBlockが存在する場合、要求したセッションにBlockを送信します。
もし、Buffer Cache領域に存在しない場合、Disk I/O発生後、Buffer CacheにBlockを置き、要求したセッションに結果値を送信します。
Result Cache機能は一般的なSQL動作方式と同じですが、結果値をCachingする点が異なります。
(1)RESULT CACHE QUERYの初回実行
- Result Cache SQLが実行されると、まず最初にShared Pool領域のResult CacheメモリでObjectのCachingの有無を確認します。
- ObjectがCachingされていない場合、Buffer CacheでBlockを探します。
- Buffer Cacheに目的のBlockが存在しない場合、DiskからBlockを読み込んでBuffer Cacheに転送する。
- その結果値をQueryしたセッションに送信します。
- 最後にResult Cache領域にSQL結果値を保存します。
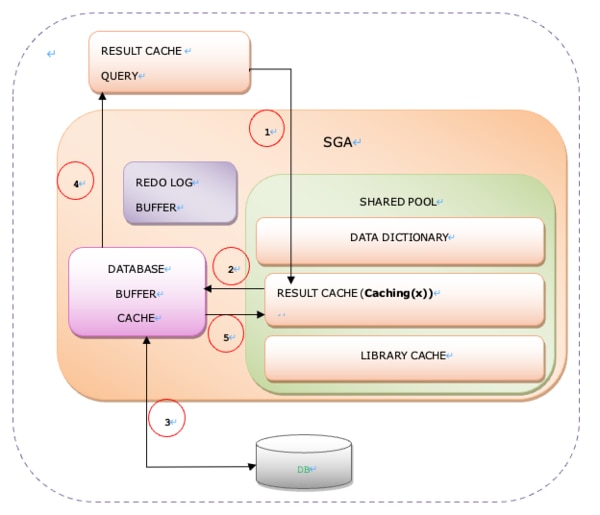
[図6-14] Result Cacheの初回実行
(2)RESULT CACHE QUERYの繰り返し実行
- Result Cache SQLが実行されると、まず最初にShared Pool領域のResult CacheメモリでObjectのCachingの有無を確認します。
- キャッシュされた情報が存在する場合、I/O を発生させず、キャッシュされた結果値を要求したセッションに送信する。
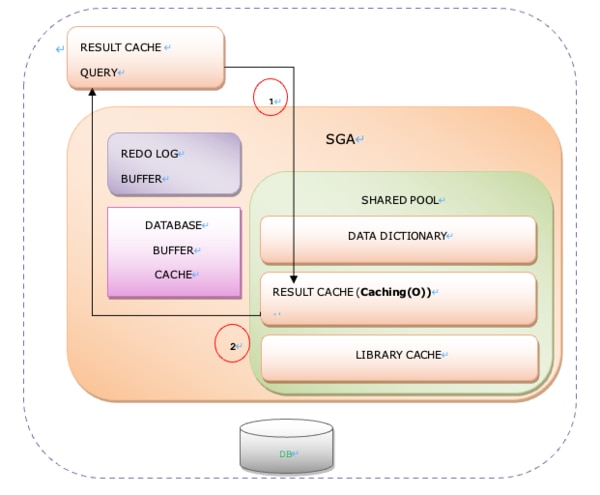
[図 6-15] Result Cacheの繰り返し実行
6.5.2 Result Cache機能の設定と解除
6.5.2.1 Result Cache機能を設定する
Parameter設定でResult Cache機能を使うことができます。
ここでは、設定に必要な主なParameterを説明していきます。
(1) RESULT_CACHE_MODE
RESULT_CACHE_MODE Parameterの値によって2つのModeの設定が可能です。その値はMANUALとFORCEです。MANUALの場合には、SQLごとに/+ RESULT_CACHE */ Hintを付与しなければ、Result Cache機能を使うという意味であり、FORCEの場合には全てのSQLがResult Cacheの対象になります。
ただし、/+ NO_ RESULT_CACHE */ Hintを付与すると、その対象から除外されます。
RESULT_CACHE_MODE Parameter の Default 値は MANUAL です。
(2) RESULT_CACHE_MAX_SIZE
Result Cache 機能を使用するには、RESULT_CACHE_MAX_SIZE 値も明示的に指定しなければなりません。このパラメータの最大値は、Shared Pool の最大 75% までしか設定できません。
(3) RESULT_CACHE_MAX_RESULT
1つのSQLに結果セットに対するキャッシュ領域全体を最大で割り当てることができるメモリサイズです。
Default値は5%です。
(4) RESULT_CACHE_REMOTE_EXPIRATION
Remote Database Object の保管周期を時間(分)で指定する Parameter で、Default 値は 0 です。
6.5.2.2 Result Cache機能を解除する
Result Cache機能を解除する方法には、特定のInstanceがResult Cache機能を使用できないように設定する方法と、Result Cache機能は使用できるが、CacheからObjectを解除する方法があります。
InstanceでResult Cache機能を使用しない場合は、RESULT_CACHE_MODEの値を0に設定し、Instanceを再起動します。Result Cache機能は使えますが、CachingされているObjectを解除する方法はResult Cacheパッケージを利用して解除することができます。この方法は例題を通して説明します。
CachingされたObjectを解除する方法:
[ Result Cache 照会 ]
Result Cacheに登録されたSQL(Object)の中で特定のObjectを解除する場合には、DBMS_RESULT_CACHE.INVALIDATEパッケージを活用すればよく、全てのObjectを解除する場合には、DBMS_RESULT_CACHE.FLUSHパッケージを使います。
6.5.3 Result Cache機能を活用
Result Cache機能の活用方法について、特定の顧客における実際の事例を通じて説明していきます。
「 顧客の商品に対する販売実績を行う業務がありました。その実績テーブルについては1年間保管され、Non Partitionテーブルが月毎に12個存在しています。
また、特定の月に該当する実績を見るためには、そのテーブルに全てのデータを読み込まなければなりません。
その場合、多くのI/Oが発生するため、高速性能を期待することはできません。
この問題に対する対応策として、毎日行われる夜間バッチで前日の実績集計テーブルの更新を行うようにしていました。これにより多くの改善効果はあったものの、読まなければならないデータの絶対量が減った訳ではないため、Overheadは依然として残っている状況でした。」
この状況下において、各月毎に該当する実績照会をResult Cache機能を使用するように誘導したらどうでしょうか?
特定の月に該当する実績のテストデータを生成し、Result Cache機能を活用するテストを実施してみましょう。
そして、どのような結果となるのか?についても詳しく見ていきたいと思います。
< Result Cacheを活用した性能改善テスト >
テストSQLを最初に実行する際、Result Cache機能を使用したのではなく、Result Cache領域に該当する結果値が入力されたことが確認されました。
その後の実行時には、こちらで意図した通りRESULT CACHEオペレーションが目撃され、同時に約38,000 BlockをI/OしていたSQLが、I/Oが全く発生させることなく、0.000002秒という驚くべき応答時間を記録しました。
Result Cache機能は、このようにSQL全体での活用が可能であると同時に、必要に応じてSQL Blockごとに指定して適用する方法も可能です。これは、異なるSQLにもResult Cacheを指定したBlockが同じであれば、同じように適用されて使用可能であることを意味します。
そこで、実際に適用できるか?について確認してみましょう。
SQL Block別Result Cache適用テスト :
異なるSQLではあるものの、Result Cache適用対象のSQL Blockが同じである場合、Result Cacheが適用されたSQL Blockが含まれていれば、どんなSQLでもResult Cacheが適用されたSQL Blockだけに改善性能が期待できることが証明されました。また、一つのSQL内で同じSQL Blockを繰り返し使用する場合であっても十分に活用することが可能となります。この点は、Result Cache活用の拡張性に大きく貢献できる特徴であり、うまく活用することができれば、複数のSQLの性能を同時多発的に改善できる効果も期待することが可能であることを意味します。
6.5.4 Result Cache使用時の考慮事項
(1)DMLとResult Cache
CachingされたObjectにDML(変更事項)が発生すると、変更された時点でResult Cache機能は無効になります。
その理由としては、CachingされたObjectが変更されると、SQLの結果値に対する整合性を保証することができないからです。したがって、DMLが頻繁に発生するObjectについては、Result Cache機能を使用しない方が良いと思います。
(2)Bind変数使用時の考慮事項
Bind変数の変更が多いSQLでも非効率は発生します。
下記のテスト結果を見てみると、Bind変数の値によって独立してCachingされることが分かります。 そのため、Bind変数が多様化された場合、特定のSQLがCacheの領域を全て使うことになり、Cacheしようとする様々なクエリによってCacheの登録と解除が頻繁に発生します。
それにより、Cacheの効率自体が減少することはもちろん、Cacheを管理するコストが増加することになります。
同じSQLでBind変数の値が様々な場合、テスト :
[ Query 実施 1 ]
[ Query 実施 2 ]
[ Query 実施 3 ]
[ Result Caching 結果の確認 ]
(3)特定のObject使用時の考慮事項
以下は、クエリ結果セットをCachingできないもう1つのケースです。
- 一時テーブルまたはDictionary Object (DBA_, V$_, GV$_* など) 参照時
- シーケンスCURRVALおよびNEXTVAL Column呼び出し時
- QueryでSQL関数を使う場合 ( CURRENT_TIMESTAMP, LOCAL_TIMESTAMP, SYS_GUID, SYSDATE, SYSTIMESTAMPなど)
Result Cacheの詳細とテストについて理解することができた中で、冒頭のResult Cacheの紹介文を振り返ってみると、どのような印象を受けるでしょうか?
その効果を正しく享受するためには、思ったよりも多くの制約事項が存在し、その表現が誇張されていると思う読者の方もきっと多いことでしょう。
しかし、その原理と制約事項を正しく理解した時点から、’画竜点睛’、’魔法’などの表現を正しく使うことができると思います。正確な理解が基盤になった後、性能改善作業の画竜点睛を正しく打つ始まりだからです。
すべてのSQLにおいて共通的に適用することはできませんが、業務の性格や重要度、Databaseの環境、DML、Bindなど様々な変数を考慮して適用可能な業務を選別して適用すること自体が、望ましい性能改善作業の結果であることを証明することができます。

次回のSQLチューニングブログは・・・
SQLチューニングブログ 2nd Season(第32回)
「第6章 大量のデータ処理性能改善方法」 ~ 量のデータに対するSummary戦略 ~
2nd Seasonも次回がいよいよ最終回です。