
Oracle SQLチューニング Season2(第29回)第6章 大量のデータ処理性能改善方法 (2/5)
今回のSQLチューニング 2nd Season(第29回)は「第6章 大量のデータ処理性能改善方法」と題しまして計5回シリーズで解説しています。今回はその第2回目「大量のデータ変更作業の性能改善戦略」です。
では、早速始めましょう。
6.2 大量のデータ変更作業の性能改善戦略
大量のデータを変更しなければならない作業(大量のDML)は、それだけで大きな負担になります。さらに、変更作業自体に限定されるものではなく、変更前のデータと変更後のデータをそれぞれ保存・管理しなければならないと言うOracleのメカニズムで考えるのであれば、パフォーマンスの改善をしなければならない立場においては、より大きな頭痛の種となります。
文字通り大量のデータを変更しなければならない作業では、その特性上において、SQL Tuningだけで性能を改善する余地は多くないだけではなく、改善したとしても劇的な効果を期待するのは難しいところがあります。また、必然的に発生するredoとundoデータによる追加の負荷は、Oracleの合理的な同時性保証のメカニズムがむしろ恨まれることになるかもしれません。
したがって、今回のテーマでは、大量のDMLを処理する時、先に説明したパーティションテーブルを活用した構成及び変更やDirect Path Insertを誘導する方法などを通じて、DML作業自体の性能改善はもちろん、Redoデータを減少させてシステムのDown Timeの最小化にも貢献することができる方法についての話をしたいと思います。
6.2.1 大量のDelete
月単位、あるいは特定の期間単位でデータを定期的に削除する業務は、どのシステムにおいても従来から良く見られる作業の1つであり、慣れ親しんだ作業です。しかし、その作業の性能を改善することは容易ではありません。
大量のDelete作業は、Table Full ScanやIndex Scanなどの様な当該テーブルにAccessする方法による非効率よりも、必然的に発生するredo, undoデータ生成に加え、当該テーブルにIndexが存在する場合、Indexの数によって追加のOverheadが発生することが性能低下を招く主な理由となるからです。
Note
Indexで発生する追加のOverheadとは、削除対象のデータをIndexでも削除する必要があるのと同時に、この過程でもredoとundoデータが生成されることを意味します。
上記のように負荷を抑えながら大量のDelete作業の実行速度を改善するにはどんな方法があるでしょうか?答えはやはりPartition Tableの構成にあります。
定期的に削除する期間が決まっている場合、そのカラムをKeyにするRange Partitionを構成し、削除対象となる期間に該当するPartition TableをAlter Table [Table_Name] Drop Partition [Partition_Name]; コマンドでDMLではなくDDLで作業を置き換えることができます。
DDLへのDelete操作の代替は、redoデータが生成されず、単にそのPartitionをDropする作業のみ行われるため、速度の差は比較できないほど大きく、大量のredo / undoデータが発生しないため、Down Timeの最小化にも大きく貢献することができます。
以下のテスト結果からその違いについて詳しく見てみましょう。
あくまでもテストであるため、パーティションテーブルと一般テーブルを生成して、両方のテーブルに同じデータを入力しました。
今度は大量のデータを削除する作業をそれぞれ実行してみましょう。
PARTITION_TEST2テーブルの3年分のデータをDeleteする作業を行った結果、注目すべき部分としては、その作業時に発生したRedoデータの量と応答時間です。
3年分のデータを消去するのにかかった時間は約7分程度であり、この過程で発生したRedoデータは約5.5GB程度であることが分かります。
一方で、PARTITION_TESTテーブルは年単位のRange Partitionで構成されており、Alter Table [Table_Name] Drop Partition [Partition_Name]; コマンドで3年間のデータに該当する3つのPartitionをDropするDDL文を実行するため、Redoデータが発生せず、1秒以内に作業が完了しました。
このように、Partition Tableへの移行は、先に紹介した内容のように単純に読み取り作業だけに限定されず、DML作業にも業務によって性能上有利な構造を提供します。続くInsert関連作業もPartition Tableへの転換が可能な場合、パフォーマンスの観点から有利な様々な方法の考案が可能です。
Partition Tableの移行が大容量データを扱う上で有利な点を多く提供するので、積極的な導入の必要性を改めて強調したいと考えます。
6.2.2 大量のインサート
大量のInsert操作の性能改善策のうち、広く知られている /*+ append */ ヒントを活用する方法については、以前に「 チューニングとヒントのInsert制御ヒントの部分」で詳しく説明しました。この方法を用いない性能改善方法について紹介します。
Index SplitによるDirect Path Insertの性能差
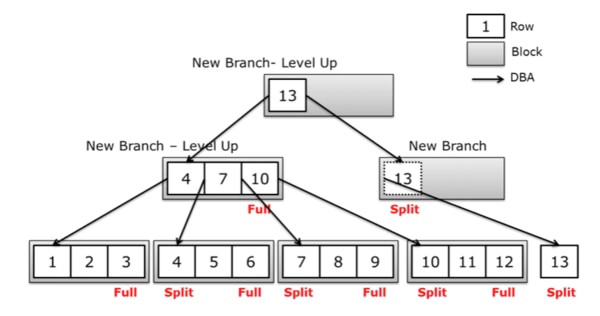
図6.2.2 9:1 Index Splitプロセス
常に増加する値をInsertする必要があるカラムが存在することがあります。
代表的な例は、日付カラムにSYSDATEが入力される状況でしょう。
もし、このカラムにIndexが生成されていると仮定して、大量のInsert作業が行われると、9:1 Index Splitが頻繁に発生する現象が自然に現れるでしょう。前述したように、Index Splitは決して軽いものではありません。
では、なぜそうなのか、その過程を見てみましょう。
まず、9:1 Splitとは、Max値が入力される状況で、右側の最下位Index Leaf Blockにこれ以上保存するスペースがない場合、Free ListのFree Blockを持ってきて、既存の最下位Index Leaf Blockの最小限のデータを新しいFree Blockに移して、新しく保存されるデータをそのBlockに入力する過程を指します。
これは、データが増加する過程で必然的にIndex Sizeが増加し、Index Splitはこの過程で発生する自然な現象です。ただし、Index Splitプロセスは無料ではありません。
Index Splitの全過程は redoが発生し、Splitが開始され、完了する時点までLockingを通じてこの作業を保護します。この時、すべてのTransactionはEnq: TX – Index ContentionというWait EventでSplitが完了する時点まで待機します。
したがって、常に値が増加する性格のカラムにIndexが生成されていて、そのテーブルに大量のデータが入力される場合、Index SplitによるWait Timeの増加に加え、redoの発生などでInsert速度の低下は必然的に発生します。
では、これを改善する方法はあるのでしょうか?
結論から言うと、問題のあるIndexに別のカラムを追加して再作成する方法は存在します。
この方法の目的は、大量のデータが入力された時、既存の右下位Index Leaf Blockに競合が集中していたのが、結合Indexによってその競合がある程度分散されるからです。
新しく結合するIndex構成対象カラムのNDV(Number of Distinct Value)値が大きいほど、Index Split減少の効果はさらに大きくなります。
ただし、この部分で注意することは、Index Clustering Factorが大きく減少する可能性があるので、NDV値が大きいカラムを優先的に構成する必要はありません。
Note.
Index Clustering Factor(CF)とは、整列が保証されたIndexの整列度とテーブルの整列度を数値化して表現したもので、CBO(Cost Based Optimizer)がIndex ScanのCost計算に決定的な影響を与える尺度である。CFの数値がテーブル全体のBlock数に近いほど性能上有利であり、テーブル全体のrows数に近いほど性能上不利な特徴を持つ。
6.2.2.1 アレイ処理
大量のDML作業は、データをLoadしたり、Update(Delete)する時、一般的にLOOP文を使って処理することが多くあります。
この方法は、毎Loopごとに1回ずつDML作業が行われ、それだけDBMS Callが発生するため、性能上で不利です。
しかし、Array Processingを利用したBulk SQLを使用すると、Loopなしで一度のSQL実行だけで処理が可能です。
つまり、大量のDMLを一度(Limit予約語を使用して一度に処理できる件数を制限しない場合)に処理することができるので、DBMS Callを減らしてLoopで処理されていた方法に比べ、大きな性能改善効果を見ることができます。
以下のテスト結果は、その性能差をよく示していると思います。
P_BULK_INSERT_TEST1はArrary Processingを活用してInsert作業を行うプロシージャであり、P_BULK_INSERT_TEST2は、1つ1つのInsert作業を行うプロシージャです。
同じ件数をInsertするとき、2つの方法の性能差がどのように現れるか確認してみましょう。
この場合、Insert操作を実行するよりもArray Processingを活用する方が性能上、はるかに有利な結果が出ました。
ちなみに、Array ProcessingはInsert操作だけでなく、UpdateやDelete操作でも効果を見ることができます。
6.2.3 Merge構文の活用
Merge構文はUpdate, Delete, InsertなどのMultiple DML作業を一度に処理する方法を提示します。
Sourceテーブルから抽出したデータをTargetテーブルへDMLを処理する形で動作するのが大きな特徴です。
MERGE構文を理解するため、構文の構成要素について説明します。
INTO節:Targetテーブルの定義とヒント構文の適用
USING節:Sourceテーブル定義とINTO節と同様にヒント構文が適用可能。
ON節 : SourceテーブルとTargetテーブル間のジョイン条件が明示され、このジョインは必ず1:1ジョインでなければならない。ON節は下記のように3つの部分に分かれています。
Note.
Merge構文使用時の制約事項
On節で指定されたSourceテーブルとTargetテーブル間の結合関係は必ず1:1結合でなければなりません。
また、Update対象カラムはOn節に使用することができません。
Merge構文が大量のデータを変更する作業で便利な場合は下記のような場合です。
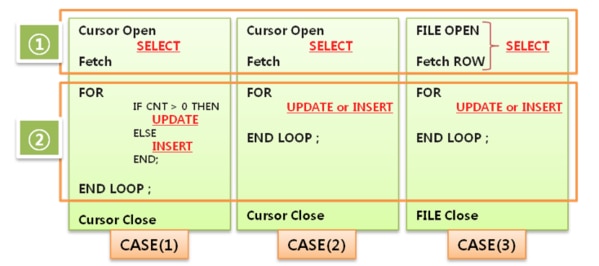
図 6.2.3 Merge構文で置き換えることができる例
上記のCASE(1), CASE(2), CASE(3)は共通的にCursor(Source Table)からデータを抽出し、抽出されたデータ数だけFOR文を繰り返し実行してUPDATE & INSERT構文を実行するパターンのプログラムです。
CASE(1),CASE(2)と違ってCASE(3)の場合は、物理ファイルを読み込んでファイルのRowずつFetchしてUPDATE構文を実行するのですが、これはFile Open + Fetch Row部分がCASE(1),CASE(2)のCursor部分と同じだと考えてください。
このようなパターンのプログラムはCursorから抽出されるデータ件数が性能を左右しますが、通常BatchプログラムはCursorから抽出される件数が最低数十万件から数百万件である場合が多く、CASE(1), CASE(2).CASE(3)のようなロジックで実行される場合、プログラムの実行時間はそれほど速くありません。
このような場合、MERGE構文を活用して性能問題を改善することができます。
MERGE構文は、Oracle 9iまではUPSERT(UPDATE+ INSERT)構文としてのみ使用されましたが、10g以降はOnly UPDATE、Only INSERT、UPSERT文など様々なパターンのDMLを処理できるように、MERGE構文の活用できる幅が広がり、CASE(1), CASE(2), CASE(3)のようなパターンのBatchプログラムの性能改善のために多く使用されています。
ただし、CASE(3)の場合、物理ファイルを読み込んでUPDATEやINSERT文を繰り返し実行するプログラムであるため、Oracle DWチューニングのために9iに新しく登場した機能であExternal TableとMERGE構文を一緒に利用すれば、性能を改善することができます。
以下は性格が似ているCASE(1), (2)とCASE(3)を分けてそれぞれMerge構文に変更して性能を改善した事例です。
Case (1), Case (2) – For Loop処理をMergeに変更する
上記のテストは、CASE (1), CASE (2) に該当するプログラムをテストするために作成したPL/SQL文です。
ロジックは、TAB_TEST1からデータを抽出し、抽出されたデータ数だけFOR文を繰り返し実行して処理するように構成されています。Trace結果を見ると、ほとんどの処理時間を消費した部分はUpdate構文です。
テーブルTAB_TEST1の抽出件数である918,843だけ繰り返し実行し、合計2,756,594 Block、約102秒のシステムリソースを使用したことが確認できます。
それでは、上のCursor For Loop構文をMerge Into文に変更した場合を見てみましょう。
Merge文を使用した場合、合計7,626 Block、約17秒のシステムリソースを使用し、従来のCursor For Loop構文に比べて大幅な改善効果を示しました。
2つの構文の性能差が発生する最も大きな理由は、大量のデータを処理する方法にあります。
Cursor For Loopの場合は、データを1つ1つ処理し、過度なDBMS Callの発生及び大量のLoop処理によるI/Oが過度に発生したのに対し、Merge構文の場合は、全体のデータを一度に処理するため、このような負荷が解消されたのです。
大量のデータ処理時において、全体のデータを一度に処理できる場合では、Merge構文の積極的な適用により該当業務をより良い性能で処理することができることを、ここではしっかりと覚えておいてください。
Case(3) – External Table + Merge活用
大量のデータに対するFileを開いてDMLを処理することも、先に説明したFor Loop処理と似たような脈絡を持ちます。 したがって、効率的な処理のためにMerge文で変更するには、そのFile形式のデータをテーブルに変更する必要があります。この時、便利な機能がExternal Tableです。
External Tableとは、Database外部のOSファイルをDatabaseのテーブルに変更して使うようにするのが核心です。ただし、External TableにはIndexを生成することができず、Select、Join、SortなどのRead Only機能しか提供されないという制約があります。それでも、FileをExternal Tableに変換する作業の高速性を保証し、Parallel Processingが可能で、大量のデータを一度に処理するのに適した性質を持っています。
以下は、File Open + For Loop UpdateをExternal TableとMerge文を活用して性能を改善したテストケースです。
大量のデータを変更する作業における性能改善の余地はやはり少ないのです。
Partitioningの有無と業務の特性によって性能改善の幅が左右されることが多くあります。
性能改善作業は、共通的に適用できる性格のものとそうでない性格のものがあり、大量のデータを変更する作業は特に後者に属する代表的な例です。
簡単に改善できるわけではないものの、意外と簡単に解決できる場合も多くあります。
もちろん、簡単に解決できる場合では、十分な関連知識の理解がベースになっているはずです。
今回紹介した要素について、日頃からよく理解していれば、関連する作業における閃くアイデアの提供者になれるものと私は確信しています。

次回のSQLチューニングブログは・・・
SQLチューニングブログ 2nd Season(第30回)
第6章「 Parallel Processing戦略 」
~ 次回は全5回シリーズの3回目をお送りしていきます ~


