
log file sync - 日本エクセム株式会社 Oracle待機イベント情報
目次[非表示]
- 1.概要
- 2.待機パラメータと待機時間
- 3.チェックポイントとソリューション
- 3.1.コミット数とlog file sync待機イベント
- 3.2.コミット数とロールバック(UNDO)セグメント
- 3.3.I/Oシステムの性能とlog file sync待機イベント
- 3.4.REDOデータ量とlog file sync待機イベント
- 3.5.REDOバッファ・サイズとlog file sync待機イベント
- 4.豆知識
- 4.1.REDO
- 4.2.sync writes
- 4.3.コミット
- 4.4.シーケンスとlog file sync待機イベント
- 4.5.PROCESSESパラメータとlog file sync待機イベント
- 5.分析事例
- 5.1.同時接続急増によるlog file sync待機イベント多発
- 5.1.1.性能低下区間の分析
- 5.1.2.待機イベントの確認と分析
- 5.1.3.log file sync待機イベントの発生原因調査
- 5.1.4.セッションおよびSQL分析
- 5.1.5.結論および解決策
- 5.2.REDOログ・ファイルの配置問題によるボトル・ネック発生
「 log file sync 」など待機イベントは、Oracleデータベースのボトルネックを調べるのに非常に有効です。
Oracleの性能状況把握のために押さえておくべき指標をまとめた「Oracle Wait Event Cheetsheet」をこちらから入手できます。主要な待機イベントの種類と、発生した場合の原因・改善策案などがわかります。
概要
ユーザー・プロセスがコミットまたはロールバックを行うと、サーバー・プロセスはLGWRへ要求を送ります。
LGWRはREDOバッファの一番最後に記録された部分からコミットした部分までの全REDOエントリをREDOログ・ファイルへ書込みます。この動作が行われた回数は、redo synch writesの統計で確認することができます。
サーバー・プロセスはコミットを実行した後、LGWRが正常にREDOエントリを書きだすまで待ちますが、この時、log file sync待機イベントで待機します。
つまり、ログ・バッファとファイルの同期化を行う間、LGWRプロセスはREDOエントリがREDOログ・ファイルへ書込みを完了するまでlog parallel write待機イベントで待機し、サーバー・プロセスはlog file sync待機イベントで待機します。
サーバー・プロセスでは2つの理由でlog file sync待機イベントが発生します。
1つ目は、ログの同期化が完了するまで待機します。2つ目は、待機がタイム・アウト(一般的には1秒)される場合です。
タイム・アウトが発生すると、サーバー・プロセスはコミットしたREDOがディスクへ書き出されたのかを確認するため、カレント・ログのSCNを確認します。
この時、コミットしたREDOエントリがディスクに書込まれたのであれば、待機は終了され、そのまま作業を進めます。もしそうでない場合は、log file sync待機イベントで待機します。
セッションが同じ領域に対して待機すると、V$SESSION_WAITのSEQ#カラムの値は毎秒増加していきます。
この場合、待たせているプロセスはLGWRですが、LGWRプロセスが他の原因で待機中ではないかについては確認をする必要があります。
一般的に、log file sync待機イベントは非常に日常的な待機イベントの一つです。ユーザーが意識しないほど短い時間で発生します。
しかし、log file sync待機イベントが過剰に発生すると、レスポンス時間が遅延しV$SYSTEM_EVENTおよびV$SESSION_EVENTに待機の統計情報の数値として記録されます。
下記のコマンドで、セッションが接続されてから現時点までlog file sync待機イベントで待たされたセッションを確認します。
待機パラメータと待機時間
待機パラメータ
log file sync待機イベントのパラメータは次の通りです。
- P1 : REDOログ・バッファ内のバッファ数
- P2 : 使用しません
- P3 : 使用しません
待機時間
1回の待機で最大1秒まで待機します。
チェックポイントとソリューション
トランザクションとは、データを更新することが目的なのでコミットが行われるのは当たり前です。
つまり、log file sync待機イベントも待機の中でもっとも一般的な待機イベントの一つです。
普通、ログ・バッファの内容がディスクに書込まれる時間は非常に早いです。
そのため、log file sync待機イベントが発生しても問題になるわけではありませんが、多量に発生してしまうと、解決しづらい待機イベントでもあります。
log file sync待機イベントが多発する場合は、次のようなことが考えられます。
- コミット数が多過ぎる
- I/Oシステムが遅い
- 不要なREDOエントリが作成されている
- REDOバッファが大き過ぎる
コミット数とlog file sync待機イベント
コミット数が多過ぎるのは、log file sync待機イベント発生のもっとも代表的な原因です。
もし、セッションがlog file sync待機イベントで長時間待機するのであれば、該当のセッションがバッチ・プログラムのプロセスなのか、OLTPシステムのプロセスなのか、それとも中間層(Tuxedo,Weblogic)のような永続接続なのかを確認すべきです。
もし、バッチ・プログラムのセッションであれば、ループ処理でコミットを繰り返し実行している可能性があります。
この場合、モジュール名を確認し、コミットの回数を減らせるかを検討するため、開発者へソースコードを確認するよう依頼しなければなりません。これは、アプリケーション側での話であり、解決方法としてはコミット数を抑えることです。
一般的には、コミットを1回実行する度に、log file sync待機イベントも1回発生します。従って、複数のセッションで同時に大量のコミットを実行すると、log file sync待機イベントが多く発生することになります。
下記のテスト結果を見ると、UPDATEを実行してからコミットをする度に、log file sync待機イベントの待機回数と待機時間が増加していることが確認できます。
PL/SQLブロックを使用する時、コミットをグループ化して実行することによって、コミットによる性能低下がある程度回避できますが、頻繁にコミットを実行した場合、多くの性能問題を引き起こします。
特に、短いトランザクションが同時に、コミットを行う場合、log file sync待機イベントによる深刻な性能低下は避けられません。従って、できるだけトランザクション単位でコミットをまとめて実行するなど、適切な対応が重要です。
コミット数とロールバック(UNDO)セグメント
アプリケーション開発者は、こまめにコミットをしなければ、ロールバック・セグメントが不足して作業が失敗すると考えがちです。
デッド・ロックも同じです。もっともいい方法はトランザクションの定義を明確にしてからトランザクション単位でコミットを実行することです。トランザクションというのは業務の単位です。
業務の単位というのは、その中にある一連の内容が全て成功するかもしくは失敗する時、完了します。
コミットまたはロールバックの適切な位置は1つの業務単位の一番最後の部分です。
ロールバック・セグメント不足問題やデッド・ロックを防止するため、追加のコミットを実行してはいけません。
これは根本的な解決にはならないためです。もし、業務単位内で処理できるロールバック・セグメントが不足しているのであれば、適切なロールバック・セグメントを追加します。Oracle9iより導入された自動UNDO管理機能を使用する場合は、UNDO表領域のための十分な領域を割り当て、適切なUNDO_RETENTIONの時間を設定しなければなりません。
不要なコミットを実行すると、また別の問題の原因になります。その中の一つがORA-01555エラーです。
このエラーは参照したいロールバック(もしくはUNDO)上のデータが上書きされた場合発生します。
また、コミットの実行が多いと、トランザクションの開始と終了時に負荷になります。
トランザクションが開始する時、ロールバック・セグメントを割り当て、ロールバック・セグメントにあるトランザクション表を更新します。これはトランザクションが終了する時も同じです。
ロールバック・セグメント情報が変更されると、その内容は必ずログ・バッファに記録しなければなりません。
従って、業務単位でコミットを行うようにアプリケーションを修正する必要があります。
ループ処理の内側にあるコミットは、ループ処理の外側に配置し、コミットが1回で済むようにします。
セッションがコネクション・プールのような中間層の永続接続で過剰にlog file sync待機が発生する場合は、多数のユーザーへサービスを実行しているからです。
可能であれば、該当セッションに10046イベント・トレースを設定し、アプリケーションをチェックします。
トレース・ファイルでlog file sync待機イベントを確認すると、コミットの発生率がわかります。
他の方法としては、LogMinerユーティリティを利用し、REDOログ・ファイルを確認します。
このユーティリティで、システム・レベルのコミット発生の状況は確認できます。
I/Oシステムの性能とlog file sync待機イベント
REDOログ・ファイルを配置しているI/Oシステムの性能が遅い場合は、LGWRがコミット済みのREDOエントリをREDOログ・ファイルへ書き出す時間が増え、log file sync待機イベントの待機時間も増加します。
この場合、サーバー・プロセスがlog file sync待機イベントで待機する間、LGWRはlog file parallel write待機イベントで待機します。V$SYSTEM_EVENTビューで、LGWRの平均待機時間、つまり、log file parallel write待機イベントの待機時間を確認します。平均待機時間が10ms(1cs)以下であれば、問題ありません。
コミット数に問題はなく、アプリケーションの性格上にもコミット数を減らせない状況で、log file sync待機イベントが多く発生するのであれば、I/Oシステムの性能を改善する検討が必要です。システムのI/O処理能力が高いほど、log file sync待機イベントとlog file parallel write待機イベントの平均待機時間は短くなります。
しかし、アプリケーションの設計に問題があったり、頻繁にコミットを繰り返すのであれば、アプリケーションを修正しない限り、問題は解決されません。
一般的に、LGWRのlog file parallel write待機イベントで待機する平均時間が長い場合や全体システムの待機時間に比べ、待機する時間の割合が高いのであれば、REDOログ・ファイルのI/Oシステムの性能に問題があると考えられます。
このような問題を解決するためには、様々な方法が考えられます。
- SAN上にあるデータベースをファイバー・チャネルで接続する
- NAS上のデータベースをギガビット・イーサネットもしくはインフィニバンドで接続する
- また、DAS上のデータベースをワイド・ウルトラ・スカジー(wide ultra SCSI)または、ファイバーチャネルで接続しプライベート・ネットワーク、高速なスイッチ、専用I/Oコントローラ、非同期I/Oを使用する
- ログ・ファイルをRAWデバイス上に配置し、RAID5の代わりにRAID0または、RAID0+1でLUNを認識させる
一般的な推奨方法としては、REDOログ・ファイルをもっとも早いデバイスに配置することです。同時にディスク競合を避けるためグループごとにREDOログ・ファイルを複数のディスクに分散します。REDOログ・ファイルをデータ・ファイルや制御ファイルと異なるディスクに分散することも有効です。
REDOデータ量とlog file sync待機イベント
コミット実行時のREDOログ・ファイルに書き出すデータ量を減らすと、log file sync待機の時間も減ります。
特に長いトランザクションでREDOデータ量を減らすとLGWRのバックグラウンド・プロセスの書き込み作業時間が減り、REDOログ関連の待機も減ります。ERPまたはDSSのようにデータを作成する作業が多いシステムの場合LGWRのバックグラウンド・プロセスの書込み作業が実行され、これによってユーザー・セッションはlog file sync待機イベントを、LGWRはlog file parallel write待機イベントを長時間待機する可能性があります。LGWRの性能低下はそのままシステム全体の性能低下に繋がります。
- REDOデータ生成を最小限にする方法は多くあります。大量データを生成する作業を行う場合は、常に下記のような方法を活用できるかを検討する必要があります。
- NOLOGGINGオプションを使用します。NOLOGGINGオプションを使うと、REDOログを劇的に減らせます。
- ダイレクト・ロード機能とCREATEコマンドやALTERコマンドでの作業はNOLOGGINGオプションを提供します。これらの機能を活用することによってREDOログを減らせます。
- SQL*Loaderで大量のデータをロードする時は、ダイレクト・パス・ロードを利用します。
- 一時作業が必要な時は可能であれば、一時表を使います。
一時表を使えば、UNDOによるREDOは生成されるものの、データに対するREDOは発生しません。これにより、REDOデータの量が全般的に減る効果があります。 - 索引がある表に対してダイレクト・ロード作業を実行する時は、索引をUNUSABLE状態に変更してから、データを生成、そして索引をNOLOGGINGモードで再構成するような順番で作業を進めます。このような手順によって、索引によるREDOの発生を最小限にします。
- LOB型データの場合、大きいデータほどできるだけNOLOGGINGオプションを使います。
REDOバッファ・サイズとlog file sync待機イベント
一般的にREDOバッファが過度に大きい場合に、log file sync待機が増加する傾向があります。
大きなREDOバッファはBackground writes回数を減少させ、LGWRプロセスによる書込みの頻度を少なくさせ、結果的にREDOバッファには大量のREDOエントリが生成されます。
プロセスがコミットを実行すると、LGWRプロセスはさらに大量のREDOエントリをディスクに記録しなければならないため、sync writeにかかる時間はさらに長くなります。REDOバッファのサイズが小さすぎる場合は、セッションはlog buffer space待機イベントで待機し、大きすぎる場合は、log file sync待機イベントで待機することになります。
一方、REDOの発生が多すぎる場合(例えば、ログ・スイッチ直後)は、REDOバッファに対する要求を受け入れるために大きなREDOバッファが必要です。
しかし、background writes回数を増加させ、log file sync待機イベントの待機時間を減らすためには適切なREDOバッファが必要です。
実際、適切なREDOバッファの大きさに正確な基準はありません。
過去には、1MB程度のバッファも大きいと思われていましたが、最近では5MB以上のREDOバッファでもシステムに影響を与えることなく使われています。
一般的な推奨では、実際にREDOバッファ・サイズが1~5MBであるシステムをモニタリングすることです。
log file sync待機イベントが増加する傾向があれば、REDOバッファ・サイズを小さくした方が望ましいですし、log buffer space待機イベントが増加するのであれば、REDOバッファ・サイズを大きくすることが一般的な解決策です。
大量のREDOを発生させる少ないトランザクションと、短いが頻繁にコミットを実行する多数のトランザクションが行われるシステムの場合では、上記の2つの待機イベントが同時に発生することが多いです。
豆知識
REDO
REDOはデータベースに適用されたすべての変更内容に対する履歴を保存しています。
ここに含まれる情報はDML、DDL、再帰的SQLによって変更された全てのデータの履歴など、DDLの場合はSQL文も保存します。
しかし、NOLOGGINGオプションを設定した状態では、データの更新履歴とDMLのSQL文は保存されません。
REDOログ・ファイルはREDOバッファの内容をそのまま保存しますが、
この作業はLGWRが担当しています。REDOバッファの内容がREDOログ・ファイルに書込まれるタイミングは、4つあります。
- 3秒ごとに自動的に書込まれます。
- _LOG_IO_SIZE隠しパラメータの設定値に達した時、書込まれます。
この隠しパラメータはREDOバッファのサイズによって自動に設定されますが、LOG_BUFFERの1/3または1MBと設定されます。
- ユーザーのコミットまたはロールバックという明示的なコマンドの実行によって強制的に記録されます。
この場合、該当トランザクションと関係したすべてのREDO情報をログ・ファイルに保存してからコミットが完了することになります。
- DBWRによってシグナルを受けた場合に、書込まれます。DBWRがデータ・バッファ・ブロックをディスクに書込む前には、必ずREDOバッファ・ログを先に書込む必要があるためです。
sync writes
ユーザーが実行したコミットまたはロールバックによって発生した書込みをsync writesといいます。
その以外の場合は、background writesといいます。
長時間のトランザクションを実行し、大量のREDOエントリを発生させるユーザー・プロセスはREDOバッファを割当られるためLGWRを呼び出し、background writesを実行します。
この場合ユーザー・プロセスはbackground writesが完了するまで待たないため、性能へ影響はありません。
しかし、頻繁なコミットによるsync writesが行われる場合、システム全体の性能に悪影響を与えるため、Oracle内部動作では、可能なかぎりコミットコマンドに対し、一括でまとめてsync writesを実行します。これをグループ・コミットと言います。
PL/SQLブロックで繰り返してコミットを実行したり、再帰的SQLによってコミットが実行される場合、複数のセッションで同時にコミット要求をしている場合に、グループ・コミット機能が使用されます。
グループ・コミットが使用される場合には、user commits統計値は、コミットコマンドが呼び出された回数と同じように増加しますが、log file sync待機イベントは1回のみ増加します。
下記のテスト結果には、グループ・コミットにより、users commitsは3回に増加していますが、
redo synch writesの回数とlog file sync待機イベントで待機した回数は1回だけ増加していることが確認できます。
コミット
コミットはトランザクションを区分けし、データベースで発生した変更内容の保存するかしないかを定義します。
もし、コミットが正常に実行されない場合は、PMONなどによってロールバック処理が行われます。
コミットは3つの種類で分けることができます。
最も分かりやすい例はユーザーが直接コミットコマンドを実行した場合です。
その他には、自働コミットとグループ・コミットがあります。
自働コミットというのは、DDLもしくはGRANT、REVOKEのようなDCL文を実行する場合や、SQL*PLUSでEXITコマンドで正常終了した場合に行われるコミットになります。
自動でトランザクションを終了されると、内部的にはコミットコマンドが実行されます。
しかし、異常終了の場合は、自働的にロールバックが実行されます。
グループ・コミットは、コミット要求がある場合に、sync writesを実行するのではなく、1回にまとめて実行します。sync writesに関しては、前項のsync writesで確認できます。
Oracle10gR2からは、COMMIT_WRITEパラメータにより、REDOバッファをREDOログ・ファイルに書込む方法をユーザーが選択できます。
ALTER SESSION SET COMMIT_WRITEまたは、ALTER SYSTEM SET COMMIT_WRITEコマンドを利用すると、待機可否や書込み方などを設定できます。
ユーザーがコミットコマンドを実行すると、トランザクション表に該当のトランザクションに対してコミットを行ってから、コミット・メッセージをREDOバッファに記録します。
その後、REDOバッファの内容をディスクに記録した段階で、関連した全てのロック情報を解除します。
ここで、注意すべきことは、REDOバッファの内容が全てREDOログ・ファイルに書込まれてしまうことです。
例えば、あるシステムにセッション1とセッション2があると仮定します。
セッション1とセッション2がそれぞれ異なるオブジェクトに対してDMLを実行するとします。
セッション1が行1の値を2に更新すると、REDOバッファにはBefore 1、After 2と記録されます。
そして、セッション2が行5の値を6に更新すると、REDOバッファにはセッション1の作業内容のその後ろにBefore 5、After 6と記録します。
その後、セッション1がコミットを実行すると、REDOバッファにコミット・メッセージが記録され、Before 1、After 2という内容だけでなく、Before 5、After 6、コミットしたという記録が全てREDOログ・ファイルに書込まれてからロックを解除し、コミット完了になります。
コミットが発生すると、一般的にデータ・ブロックに対してクリーン・アウトが行われます。
クリーン・アウトというのは、トランザクション情報を更新して該当行に対するロックを解除することを意味します。
しかし、大量のブロックを更新し、コミットした場合、この変更内容を記録するために一部ブロックだけクリーン・アウトし、残りは他のセッションが再度それらのブロックにアクセスするまでそのまま置いておきます。
これをファースト・コミットと言います。
データ・ブロックを変更する度に、ブロック・ヘッダーは、変更情報を記録したUNDOセグメント・ポインターを持ちます。コミットが実行される時、クリーン・アウトされないブロックは、UNDOセグメント・ヘッダーにコミット済みという表示を残し、作業を完了します。
このように、ファースト・コミットによってクリーン・アウトされず残されたデータ・ブロックは、次回、ブロックを読込にくるセッションによってクリーン・アウトされます。
シーケンスとlog file sync待機イベント
シーケンスを生成する時、NOCACHEオプションを設定する場合があります。
NOCACHEのシーケンスは多くの性能問題を引き起こしますが、代表的な場合はrow cache lock待機が増加することです。
NOCACHEオプションはlog file sync待機イベントを発生させる原因にもなりますが、その理由は、NOCACHEのシーケンスにSEQUENCE.NEXTVALを使うと、その度にディクショナリー表の情報を更新した後コミット行われるためです。シーケンスを使う時はトランザクション量を考慮し、適切なCACHEを与えなければなりません。
PROCESSESパラメータとlog file sync待機イベント
PROCESSESパラメーター値を大きく設定する場合、log file sync待機が増加することになります。
すべての同期化作業では、LGWRはどのセッションがこの待機イベントで待機していてるか、どのセッションのREDOエントリをディスクに書込めなければならないのか確認するため、プロセスのデータ構造をスキャンしなければなりません。
従って、PROCESSESパラメーターを小さく設定する場合、log file syncの待機を減少させられます。
適切な値を調べるためには、V$RESOURCE_LIMITビューを使います。しかし、このような問題はOracle9iR2から解決されました。
分析事例
同時接続急増によるlog file sync待機イベント多発
プロセスの接続が一瞬で急増する場合、接続時に必要なリソース確保および内部コミット発行による突発的な性能遅延が発生します。
OLTPおよびWEB環境では、このような瞬間的なサービス障害でシステムの可用性を低下してしまいます。ここでは、過度な同時接続によって発生した性能低下問題の原因を探ってみます。
性能低下区間の分析
CPU使用率には明確な変化がないように見えますが、16時47分にはアクティブ・セッションが急増しており、16時46分には待機時間も急増していることが確認できます。
■CPU使用率の推移グラフ

■アクティブ・セッションの推移グラフ

■待機時間の推移グラフ

待機イベントの確認と分析
アクティブ・セッション急増による性能が劣化した原因を調査するため、問題時点(16時46分および16時47分)の待機イベントの発生内容を確認します。
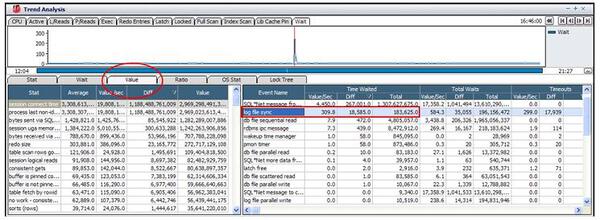
「Value」タブで同じ時点の上位待機イベントを確認した結果、アイドル・イベント(= SQL*Net message from client)以外の上位待機イベントは、log file sync待機イベントであり、16時46分にlog file sync待機イベントの待ち時間が最も長い(秒当たり309秒)です。
しかし、アクティブ・セッションのピークである16時47分を機に、log file sync待機イベントの待ち時間が減少(秒当たり18秒)しています。
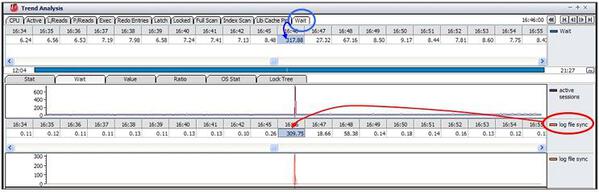
アクティブ・セッションの急増に対するlog file sync待機イベントの関連性を定義するため、待機イベントとのその発生パターンを比較してみた結果、アクティブ・セッションの発生推移と非常に似ており、問題時点に発生した待機イベント(待機時間)の約97%(全体317.88秒中で、307.75秒)を占めています。
つまり、アクティブ・セッションの急増はlog file sync待機イベントの発生と関連していることが推測できます。
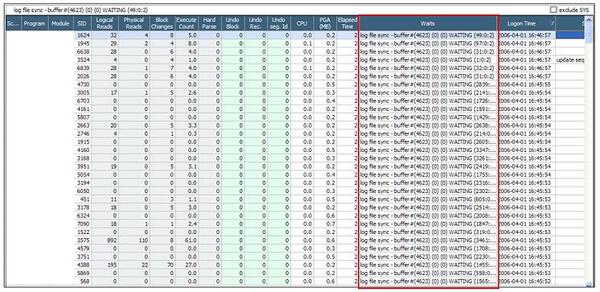
実際に、同じ時点の「セッション・リスト」 を確認しても、log file sync待機イベントが多く発生しており、セッションの接続もほとんど同じ時間帯に発生しています。
log file sync待機イベントの発生原因調査
log file sync待機イベントは一般的にユーザーのコミットまたはロールバック時に実行されるLGWRのsync writeによって発生し、主に過度なコミット発行またはLGWRのI/O処理速度の問題によって発生します。
従って、まずはコミットおよびLGWRと関連した統計、user commits、redo write time、redo synch time、redo entriesの推移を確認します。
log file sync待機イベントの待ち時間が急増した時点でuser commits統計値は1秒当たり259回になっており、他の時間帯と比べ、変わりはありません。
また、REDO発生回数を示すredo entries統計値も他の時間帯に比べ、変わりはありません。
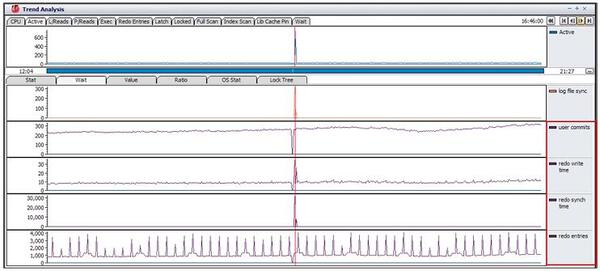
しかし、この時点にユーザーのコミットによって発生するredo synch writes統計値に対する処理時間redo synch timeは31727cs(317秒)で、LGWRがログ・バッファのREDOレコードをREDOログ・ファイルに記録するために必要な時間を示すredo write timeは35cs(0.35秒)であることから、この待ち時間は長くない->LGWRのI/O性能による問題というよりはredo synch writesに対する処理時間が長くなっていることが最大の原因であることが分かります。
セッションの詳細データを確認した結果、接続時間がほとんど同じ時間帯であることから、ログオンと関係があるlogons current、logons cumulative統計値とactive sessions、log file sync統計値を比較分析することにします。
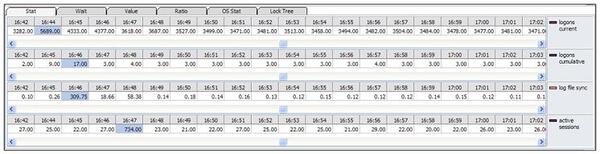
推移グラフの分析結果を時間順で整理すれば次のようです。
時間 | 説明 |
16:44 | 同時接続ユーザー数を表すlogons current統計値が5689で、ピークになっている |
16:46 | 1秒あたり接続ユーザー数を表すlogons cumulative統計値が17で、ピークになっている(この時点でlog file sync統計値もピークである) |
16:47 | アクティブ・セッションがピークになっている |
セッションおよびSQL分析
log file sync待機イベントで待機が目立っていた16時46分~16時47分でlog file syncを待機した
セッションを検索した所、ユーザープログラムでログオン処理のためにSYSスキーマで再帰的SQL(SEQ$ Update)を実行していることを確認できます。
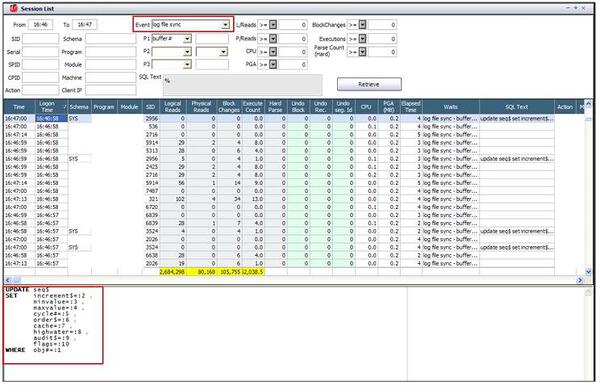
ログオン時にはV$SESSION.AUDSIDカラムの値を設定するため、SYS.AUDSES$シーケンスの値を取得しなければなりません。
もし、このシーケンスのCACHEサイズが小さすぎて、ディクショナリー・キャッシ(DBA_SEQUENCES.LAST_NUMBER)を変更する場合には、SYS.SEQ$を更新する再帰的SQLが実行され、内部的なコミットが発生します。
このようなコミットはユーザーが実行したコミットではないため、user commits統計値の数値に反映されません。
結論および解決策
同時接続が多い時、log file sync待機によるアクティブ・セッションの急増→
SYS.AUDSES$シーケンスのCACHEサイズが小さくてSYS.SEQ$を更新する内部SQL実行およびコミット多発→
SYS.AUDSES$シーケンスのCACHE値を大きく調整して解決
SQL> ALTER SEQUENCE SYS.AUDSES$ CACHE 10000;
REDOログ・ファイルの配置問題によるボトル・ネック発生
Oracleはほとんどの場合、DMLによるすべての変更事項に対してREDOデータを生成します。
DMLを実行すると、その変更内容はバッファ・キャッシュに保存される前にまずREDOバッファに保存されます。
また、バッファ・キャッシュの使用済バッファをデータ・ファイルに記録する前に、該当するREDOデータをREDOバッファからREDOログ・ファイルに書込みます。
このように書込みが頻繁に起きるREDOログ・ファイルは、性能のいいシステムが求められます。
ここでの事例は、REDOログ・ファイルと一時ファイルを同じディスクに配置して、I/O処理が遅くなった例です。
下記のグラフを参照すると、アクティブ・セッションが急上昇する区間が発生しています。
そしてアクティブ・セッションのグラフ推移はdirect path read/write、log file sync、db file scattered read、db file parallel write待機イベントの推移とも一致しています。
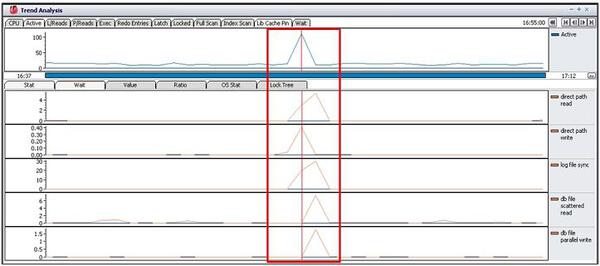
direct path read、direct path write待機イベントは一時ファイルのI/Oと関係したイベントであり、ソート作業やHASH JOINを行うSQL実行時に発生します。
log file sync待機イベントは、REDOログエントリをREDOログ・ファイルに書込みが完了するまで、サーバー・プロセスが待たされている時に発生するイベントです。
db file parallel write待機イベントはDBWRが使用済みバッファをデータ・ファイルに書込む時、
発生するイベントです。
性能が低下した流れは、下記のとおりです。
ピーク時のセッション状況を確認すると、全体的に論理読取り/物理読取りが0の場合がほとんどであり、I/Oは発生していません。
①LGWRはlog file parallel write待機イベントで待機しています。
これは、書込みしなければならないREDO量が多い場合、REDOログ・ファイルが配置しているディスクのI/Oが遅い場合や、、REDOバッファが大きい場合によく発生します。この事例で取り扱っているシステムはログ・バッファが1MBになっており、これは一般的なサイズだと言えます。
②log file sync待機イベントで待機するセッションはDMLを実行しています。
DBWRはdb file parallel write待機イベントで待機しており、このイベントは、チェック・ポイントが発生した時バッファ・キャッシュから使用済みバッファをファイルに書込む間に発生します。
③direct path read/write待機イベントで待機するセッションはソート作業により発生しています。

上記の事例は、全体的にI/Oの速度が遅いため発生した問題です。
このような場合、アプリケーションつまり、SQLチューニングを考慮する必要があります。
また、システムI/Oについても検討が必要です。
それぞれのファイルの位置はv$datafile、v$logfile、v$tempfileビューで確認できます。
とくにREDOログ・ファイルは書込みが頻繁に発生するので、最も速いデバイスに配置します。また、ディスクの競合を避けるため、それぞれのREDOログ・ファイルは全て異なるグループのディスクに分散します。また、このREDOログ・ファイルは他のデータ・ファイルや一時ファイル、システム・ファイルとも異なるディスクに配置します。
「 log file sync 」など待機イベントは、Oracleデータベースのボトルネックを調べるのに非常に有効です。
Oracleの性能状況把握のために押さえておくべき指標をまとめた「Oracle Wait Event Cheetsheet」をこちらから入手できます。主要な待機イベントの種類と、発生した場合の原因・改善策案などがわかります。


