
Index Split - 日本エクセム株式会社 Oracle 技術情報
目次[非表示]
- 1.概要
- 2.詳細
- 2.1.50:50 vs 90:10
- 2.2.Index Splitと統計値
- 2.3.Index Splitと待機イベント
- 2.4.SequenceとIndex Split
- 2.5.無分別なインデックスの作成
- 2.6.Index SplitとAutonomous Transaction
- 3.関連情報
- 4.外部参照
SQLチューニングのためには、そのSQLがどのように動いていて、データベースにどのように影響しているのか、を把握する必要があります。『MaxGauge』があれば簡単に状況が把握でき、適切なSQLチューニングができるようになります。
『MaxGauge』の資料はこちらから。
概要
オラクルのB-Treeインデックスのブロックがいっぱい(Full)になった場合、Splitを介して新たな空間を確保します。Index Splitの種類は、次のように分けられます。
Index Splitは、インデックスのサイズが成長する過程で必然的に発生する現象で、これを回避する方法はありません。しかし、同時に、多くのセッションがDMLを実行する過程で、Index Splitが発生すると、競合が発生して、全体的なパフォーマンスの低下が発生します。
詳細
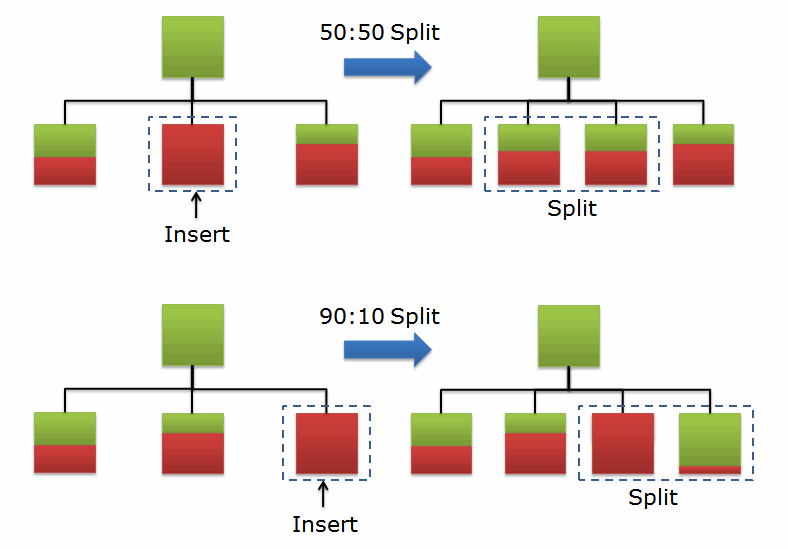
50:50 vs 90:10
一般的なLeaf Node Splitは50:50の割合で行われます。つまり、Leaf Blockがいっぱいになる新しいブロックを割り当てられた後、既存のブロックと新しいブロックに50:50にキーの値を再分配します。しかし、最も右端のLeaf Nodeで最大のキー値が挿入されることでSplitが発生した場合には、新たに割り当てられたブロックには、新たに追加されたキー値だけが追加されます。すなわち、従来のつまったブロックのキー値を再分配していません。このような理由のために90:10 Splitを99:1、または100:0 Splitと呼ぶこともあります。90:10 Splitは、インデックスキー値が一方向に増加し、キーの値が挿入される場合に発生します。
Index Splitと統計値
Index Splitに関するオラクル統計値は、以下の通りです。
Index Splitと待機イベント
SequenceとIndex Split
Sequenceを利用して、インデックスキーの値を生成する場合、Index Splitが過度に発生する主な原因の一つとなります。これは、常に最右ノードにのみInsertが集中され、Splitが頻繁に発生するためです。IndexによるOrderingが不要な場合には、Reverse Indexを使用することにより、このような現象を避けることができます。
無分別なインデックスの作成
不要なインデックスを無分別に作成し、不要なキー値をインデックスに追加することもIndex Splitが過度に発生する主な原因の一つとなります。インデックスは、必ず必要なカラムのみ生成し、重複インデックスは、できれば避けることが望まれます。
Index SplitとAutonomous Transaction
トランザクションの実行中にIndex Split作業が必要な場合は、OracleはAutonomous Transactionを利用してSplit処理を実行します。したがって、親トランザクションがロールバックされてもIndex Split処理はAutonomous Transactionによって永久的に記録されます。
関連情報
外部参照
SQLチューニングのためには、そのSQLがどのように動いていて、データベースにどのように影響しているのか、を把握する必要があります。『MaxGauge』があれば簡単に状況が把握でき、適切なSQLチューニングができるようになります。
『MaxGauge』の資料はこちらから。

