
ORACLE EXADATA HCC圧縮方式を理解する - 日本エクセム株式会社 Oracle技術情報
目次[非表示]
概要
時間が経つにつれて、データは急速に増加していきます。
データが増加するにつれて、DBMSによって管理される情報も急速に増加していきます。
このため、ストレージスペースの不足によるハードウェアコストの増加とデータ処理性能に多くの問題点が現れてきます。
これらの問題を解決するために、ORACLEはEXADATAと呼ばれるシステムを使用してストレージスペースの不足とデータ処理のパフォーマンスを向上させたいと考えています。 EX大容量データベースのディスクストレージシステムからデータベースサーバーに多くのデータを移動させる際に発生する多くの非効率をハードウェアとソフトウェアの組み合わせで解決しようとしたものがEXADATAシステムと呼ばれていますが、HCC(HYBRID COLUMNAR COMPRESSION)という圧縮技術により、このような問題を解決することができます。
この章では、EXADATAシステムのHYBRID COLUMNAR COMPRESSION圧縮を中心に説明します。
データ圧縮の原理を調べて、ディスクスペースの節約とデータ照会のパフォーマンスにどのような影響を与えるかを比較してみます。
HCCとは何で、どのように動作するのかを見てみましょう
データを圧縮すると、ストレージスペースを節約できます。
さまざまな方法でデータを圧縮することができ、EXADATAシステムではHCCと呼ばれる圧縮方式を通じてより高度な方法で圧縮を行うことができます。
HCC以前の圧縮方式は、BLOCK内に重複した値を1つの値として持ち、その値を参照するアドレス値を介して冗長データにアクセスする方式であるROWデータに基づく圧縮方式です。
ROWベースの圧縮から進歩した形式の圧縮がHCC圧縮と呼ばれ、HCC圧縮方式はEXADATAでのみ使用できます。
HCC(HYBRID COLUMNAR COMPRESSION)とは、列ベースの圧縮方式で同じタイプのデータと同様の列属性を隣接して保存すれば、より効果的な圧縮を行ってストレージスペースを効率的に減らすことができまます。
カラムとROWの組み合わせでストレージスペースの効率性と良好な性能が期待できるHYBRID圧縮方式です。
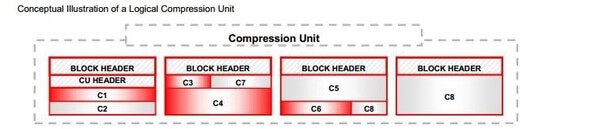
[図1] COMPRESSION UNITの配置構造
HCC圧縮方式は、ROW単位でデータを保存せずにCU(COMPRESSION UNIT)単位で保存されます。
図1に示すように、1つのCUは通常32Kまたは64Kで構成されています。
CUには複数のBLOCKがあり、CU内のデータはカラムに再編成されます。
このように構成されたCUの利点は、CUを一度だけ読み取るだけで、ROW全体を読むことができる利点がありますが、カラム全体を読むにはすべてのUNを読む必要があるため、完全なカラムベースの圧縮方式とは言えません。 完全なカラムベースで構成されている場合は、すべてのCUを読み取らずにすべてのカラムを読み取ったはずです。
しかし、HCC圧縮は、カラム型の圧縮のメリットであるディスクの節約と、ROW型の圧縮のメリットである照会性能をすべて満足させることができるHYBRID圧縮と言えます。
HCC圧縮にはどのような種類がありますか?
HCCスキームにはさまざまな種類があり、以下の表から各タイプの特徴を見ることができます。 以下の表を参照して、テストで圧縮タイプの特徴を具体的に調べてみましょう。
圧縮 タイプ |
説明 |
予想圧縮率 |
QUERY LOW |
HCCレベル1はLZO圧縮アルゴリズムを使用します。 このレベルは最も低い圧縮率を提供しますが、圧縮および解凍操作には最小限のCPUが必要です。 QUERYLOWアルゴリズムは圧縮よりも速度を最大化できるように最適化されました。 このアルゴリズムの解凍は非常に速いのです。 一部の文書では、このレベルをWAREHOUSE LOWと呼びます。 |
4X |
QUERY HIGH |
HCCレベル2はZLlB(gzip)圧縮アルゴリズムを使用します一部の文書では、このレベルをWAREHOUSE HIGHと呼びます。 |
6X |
ARCHIVE LOW |
HCCレベル3もZLlB(gzip)アルゴリズムを使用しますが。 QUERYHIGHより高い圧縮レベルです。 ただし、データによっては、圧縮率はQUERY HIGHより高くない場合があります. |
7X |
ARCHIVE HIGH |
HCCレベル4圧縮はBzip2圧縮を使用します。 これは利用可能な最高レベルの圧縮ですが、単に最もCPUを私します。 圧縮時間はしばしばレベル2と3よりも数倍ARCHIVE HIGHが遅いです。 しかし、ターゲットデータによっては、圧縮率はARCHIVELOWよりも高くない場合があります。 |
12X |
[표 1-1 ] 圧縮タイプ
表1-1で説明した圧縮タイプを使用して、各機能をテストで確認しましょう。
テストテーブル生成スクリプト
圧縮タイプによる試験結果
テーブル名 |
圧縮方法 |
圧縮率 |
読込時間 |
HCC_TEST_HCC1 |
QUERY LOW |
8 |
00:00:20 |
HCC_TEST_HCC2 |
QUERY HIGH |
15.4 |
00:00:40 |
HCC_TEST_HCC3 |
ARCHIVE LOW |
15.4 |
00:00:40 |
HCC_TEST_HCC4 |
ARCHIVE HIGH |
22.2 |
00:04:01 |
[표 2-1 ] 圧縮タイプテスト結果
表1圧縮タイプテスト結果を見ると、圧縮方法が高いほど圧縮率が高くなります。
つまり、圧縮レベルが高いほどストレージスペースを節約することができます。
QUERY HIGHを見ると、QUERY LOWに比べて圧縮率が7倍ほど良くなりましたが、読み込み時間も2倍程度かかっています。 ARCHIVE LOW 見れば QUERY HIGH とほとんど差がありません。
ARCHIVE HIGHを見ると、圧縮率がARCHIVE LOWに比べて7倍ほど良くなりましたが、時間は4倍ほど遅くなってます。
その結果、レベルのステップが高いほど圧縮率は良くなりますが、読み込みはより多くの時間を要しています。 また、圧縮中に時間がかかる場合は、システムリソースも長時間使用する必要があります。.
HCC圧縮とQUERYパフォーマンスとの関係
HCC圧縮とQUERYの性能を調べましょう。 ここで2つのテストをしましょう。 I/O 多用型QUERY パフォーマンステストと CPU多用型 QUERY パフォーマンステストをしてみましょう。
このようにテストする理由は、クエリに状況によってパフォーマンスに差があるためです。
I/O多用型QUERY
CPU多用型QUERY
HCC圧縮とQUERY性能テスト結果
テーブル名 |
I/O多用型 |
CPU多用型 |
HCC_TEST |
00:02:51 |
00:00:13 |
HCC_TEST_HCC1 |
00:01:31 |
00:00:16 |
HCC_TEST_HCC2 |
00:01:13 |
00:00:19 |
HCC_TEST_HCC3 |
00:01:14 |
00:00:19 |
HCC_TEST_HCC4 |
00:01:58 |
00:00:33 |
[표 2-2 ] HCC圧縮とQUERYパフォーマンステスト結果
表 2-2 を参照すると、I/O 多用型 QUERY と CPU 多用型 QUERY のパフォーマンスに違いがあります。 I/O多用型の場合は、HCC圧縮変換後を比較してみると、各HCC圧縮レベルごとに少しの差は見えますが、圧縮する前よりも良好な性能を示したものの、CPU多用型は圧縮する前よりもすべて悪い性能を示しました。
このように QUERY の形式 (I/O 多用型 QUERY と CPU 多用型 QUERY) によって実行結果が変わった理由は、I/O 多用型タスクは QUERY 照会時に解凍による CPU 使用より HCC 圧縮で読み取るべき BLOCK 数 の削減効率が良かったためであり、CPU多用型操作が圧縮前のデータよりも悪い性能を示した理由は、解凍に使用されたCPUリソースの使用と統計情報生成で使用したCPU使用リソースがHCC圧縮で読み取らなければならないBLOCK数 の減少効率より良くなかったからです。したがって、圧縮されたデータは、各QUERY状況によってパフォーマンスが異なります。
DML(INSERT、UPDATE)を使用する場合のHCC圧縮方法と注意点
INSERTでHCCを圧縮する
INSERTでデータ圧縮を行う場合、DIRECT PATH LOADの場合のみHCC形式で圧縮が行われます。
以下のテストで確認してみましょう。
— INSERT HCC 圧縮する
テーブルを作成した後、ALTER命令を使用してテーブル形式をARCHIVE LOW形式の圧縮形式にテーブルに変更しました。
テーブルは圧縮形式に変更されましたが、DIRECT PATH LOADは発生しません、
データロードと元のテーブルのSEGMENTの違いはほとんどありません。
しかし、DIRECT PATHLOADにより 発生したデータ読み込みは、HCC タイプである ARCHIVE LOW 形式の圧縮が行われます。
UPDATEでHCCを圧縮する
HCCが行われたデータに対してUPDATEが発生すると、圧縮は解除されます。
以下のテストを通して学びましょう。
UPDATE後のテスト結果を見ると、HCC圧縮前と比較して、SEGMENT値とブロック数が増加していることがわかりますが、圧縮前のデータと比較して、SEGMENT値とBLCOK数が減少していることがわかります。
それでは、なぜSEGMENT値とBLCOK数は圧縮前に戻っていないのでしょうか?
より正確には、既存のHCC圧縮形式からOLTP形式の圧縮へのダウングレードです。 OLTP圧縮形式は、DIRECT PATH LOADが発生しなくても圧縮可能であり、HCC操作方法で簡単に説明したROWベースのブロック単位圧縮方法です。 OLTPタイプの圧縮は、HCC圧縮タイプのテーブルでHCC圧縮を実行できない場合(非DIRECT PATH LOAD)のHCC圧縮の安全な圧縮方法です。
テストで詳細を学びましょう.
UPDATE後の表のROWID情報を見ると、ROWIDが変更および移行されていることがわかります。
UPDATEの前にROWIDを検索すると、移行されたROWIDと同じOBJECT_IDも存在します。 値は1つだけで、データのロード中に圧縮するのではなく、非圧縮データがロードされ、BLOCKにデータをロードするスペースがなくなると、圧縮が実行されます。 圧縮後、空のスペースがFREE LISTに戻され、圧縮されていないデータが再ロードされます。 BLOCKに再度ロードするスペースがない場合、非圧縮データは圧縮されます。 このプロセスでは、各行の値の一部が圧縮形式で読み込まれ、同じ行の一部のデータが非圧縮データとして存在するため、複数のROWIDが存在します。
つまり、HCC形式の圧縮空間でUPDATEが発生すると、OLTP圧縮にダウングレードされますが、ROWに対してUPDATEされ、変更された値は非圧縮形式で存在するようになります。
高 UPDATE が発生しない ROW は圧縮された形で存在することになり、ROWID が 1 つ以上存在します。
現在、私がサポートしているお客様から、既存のDB2システムで統計関連の一部業務をEXADATAシステムで構築しましたが、HCC圧縮を希望する対象にテーブルに対してUPDATE業務をすべて
DELETE後INSERT業務に変更しました。
HCC圧縮時の注意
システムの初期には多くのデータがありません。 時間の経過とともにデータが増加し、変更されていない履歴の性質を持つテーブルは、HCC圧縮でストレージスペースを節約できます。 しかし、トランザクションが多くのオンライン時間にHCC圧縮を行うと、HCC圧縮を行う間、DMLトランザクションはテーブルLOCK(enq:TM – contention)が発生し、システムに悪影響を及ぼすからです。
上記の状況をテストで確認してみましょう。
— SESSION 1
しかし、HCC圧縮したい大容量テーブルは、日付に基づいて月または日ごとの圧縮を試みます。 もしそうなら、過去の月に対してHCC圧縮をするならば、上記のような問題は発生しないと考えられますが、まだHCC圧縮をするには多くの困難が存在します。
過去のパーティションに対してALTER MOVE命令でHCC圧縮を行うと、ROWID値が変更され、既存のインデックスが使用できなくなります。
HCC圧縮後にINDEX REBUILDを行う必要があります。
インデックスのREBUILD時間中、HCCは1つのパーティションがFULL SCANになり、それによって多くのシステムに負荷がかかります。
これらの問題を解決するために、パーティションEXCHANGEを使用してHCC圧縮を適用できます。
ただし、変更が発生しない過去のパーティションテーブルでのみ可能です。
テストを通して学びましょう。
— テストデータの生成
— ALTER MOVE 命令によるHCCの一部のパーティションの圧縮
— インデックス UNUSABLE 状態
— パーティションTEMPテーブルの作成
— パーティション EXCHANGE
結論
時間が経つにつれて、データがますます増えてきているため、DBMSシステムの照会パフォーマンスの問題とストレージスペースの増大に多くのコストが発生しています。
これらの問題を解決するための代替案の1つは、すぐにデータを圧縮することです。
特にEXADATAシステムでは、HCCと呼ばれる進化した圧縮方法でストレージ節約と照会性能を最適化することができます。
しかし、これらの圧縮方法をよく理解しておらず、使用すると、システムにはいくつかの問題が発生する可能性があります。
また、圧縮したい対象もよく選別しなければならない。 更新が多いテーブルにHCC圧縮を適用すると、ストレージスペースの節約に最大の効果は見られません。
したがって、更新があまり起こらないデータを圧縮対象に選定するのが良いです。
頻繁に更新されるデータ以外の変化が少ないデータに対してHCC圧縮技術を使用する場合、BIG DATA時代にハードウェアコストの削減とデータ処理性能に対して様々なシナジー効果を得ることができます。


