
Oracle SQLチューニング Season2(第28回)第6章 大量のデータ処理性能改善方法 (1/5)
今回のSQLチューニング 2nd Season(第28回)は「第6章 大量のデータ処理性能改善方法」と題しまして計5回シリーズで解説していきますが、今回はその第1回目となります。
では、早速始めましょう。
ITパラダイムの変化するスピードは、私たちが考えているよりもずうっと早いです。
例えば、DBの業務処理1つにおいても、慣れ親しんだ方式であるOLTP、DWなどで正確に区分されるのではなく、業務自体の区分が曖昧になっており、同時処理量の大量化現象が目立ってきています。大量のデータ読み取り、演算、ソートをして目的の情報を抽出する業務が主流となっています。このように抽出されたデータは、各企業の新たな利益創出や生産コスト削減などの意思決定に活用されたり、政府傘下である機関の政策の妥当性についての検査に用いられており、様々な機関や企業での様々な方法による分析や統計作業をより簡単に提供できるようになりました。
このようなパラダイムの変化によって、DBシステムに与える影響もかなり大きいものがあります。大量のデータ処理に伴う負荷の増加はおそらく避けられないのが現実ではあるものの、同時に最大限に克服しなければならない課題でもあります。
大量のデータを扱わなければならないという不変の前提条件を持つ環境で発生する性能の問題を、果たしてどの程度改善できるのでしょうか。そのためにはまず、認識の転換が必要となってきます。
これまで持っていた偏見をすべて打ち破り、理論だけで知っていた知識を活用することができれば、大量のデータを扱う業務のパフォーマンス改善は、もはや難題にとどまらず、希望するレベルでの改善を実現できるのではないか?と考えます。
今回のテーマを通じて、大量のデータ処理におけるパフォーマンスの向上に貢献できる要素について紹介していきます。しかし、ここから紹介する内容は、まるで数学の公式のようにすべての状況で当てはめることはできません。業務の特性に合わせて積極的に考慮できる部分はありますが、逆にそうでない場合もあります。
本テーマでは、性能改善のための各要素の原理についてのテストを通じて、理解を深めることに焦点を当てています。
大量のデータ処理に関連する性能問題を抱えていたり、この部分に関心のある読者がいれば、性能改善要素の理解と業務の理解を伴って、その解決策を見つけることに貢献できるきっかけになってもらえたら幸いです。
6.1 積極的なPartitioning戦略
大量のデータを保存した一般テーブルを照会するためのSQLにおける照会のパターンを調査してみると、一般的に日付期間条件のように共通的に見られる照会条件が存在します。これは、V$SQL_PLANビューなどを通じて、Access Patternを抽出する方法での情報抽出が可能ですが、共通分母があった場合には、一般テーブルのPartitionテーブルへの積極的な転換を考慮しなければなりません。

[図6-1] Partitioningの理由
[図6-1]は、PARTITION_TESTというテーブルのSizeが50GBであると仮定した状況です。
しかし、そのテーブルを照会するパターンを調べてみると、月単位の照会が行われていた場合、PARTITION_TESTテーブルが持つ構造的な非効率が存在します。必要なデータは、1ヶ月に該当するデータに過ぎないのに、もしTable Full Scanが実行された場合、不必要に50GBに該当する全データについてのI/Oをしなければならないと言った非効率な処理が発生することになるでしょう。そして、照会条件としてIndex Scanを実行したとしても、1ヶ月に相当する数十あるいは数百万件のデータだけTable Random Accessが発生すると言った非効率な処理が発生することが予測されます。
パフォーマンスの観点から見た場合の最も効率的な方法としては、テーブルを月単位でPartitioningした上で、該当する特定のPartition Table一つだけをTable Full Scan (Partition Range Single)で読むことこそが、I/Oや応答時間の面においての最も効率的な方法と言えるでしょう。このような場合、業務的にPartition Tableへの移行が可能な場合と、そうでない場合に分けて実際の性能を比較するテストを行って、その結果について詳しく説明したいと思います。
6.1.1 パーティションの切り替えが可能な場合
6.1.1.1 Non Partition TableをPartition Tableに変換する
上のスクリプトを実行することで、同じデータをパーティションテーブル(Partition_test)と一般テーブル(Partition_test2)の2つを生成し、月単位の照会条件で実行されるSQLの性能をそれぞれで比較してみましょう。
一般テーブルvs.Partitionテーブルの性能比較テスト :
まず、Non Partition Tableの場合を見てみましょう。
全データをTable Full Scanして欲しいデータ(1ヶ月に相当するデータ)だけをFilteringしました。その結果、データを抽出するSQLは8.31秒の応答時間と約510,000 Block以上をDisk I/Oで処理したことが分かりました。
性能面から見ると、明らかな非効率が存在していることがわかります。
上記のテスト結果からわかった非効率を改善するために考えられる一般的な方法が Indexの生成 です。そこで、TIME_IDカラムにIndexを生成してIndex Scanを誘導してみることにしました。
その結果として、7.62秒の応答時間と合計320,000 BlockほどのI/Oが発生しました。
この過程においてのDisk I/Oは、約39,000 Block程度が含まれていることが分かり、このDisk I/OはIndexからPARTITION_TEST2テーブルへのTable Random Accessを実行する部分で誘発されたことが分かります。
Index Scanは、Single Block I/O 方式で処理していますが、Disk I/O の量が多くなる分だけ、応答時間の面においては大きな非効率が発生してしまうのが特徴です。したがって、39,000 Block以上の Disk I/O が発生した場合には、応答速度は上記の結果より更にかかってしまう可能性があります。
次にPartition Tableのテスト結果を見てみましょう。
Partitioningの基準は、テーブル生成スクリプトで紹介したようにTIME_IDカラムの月単位で構成されています。 上のSQLのTIME_ID期間条件は、1ヶ月に該当するデータが入力されます。
まず、実行計画を見てみると、PARTITION RANGE ITERATORというオペレーションが目立っています。
このオペレーションは、Rang Partition KeyとなるTIME_ID条件に入力されるバインド変数によって、該当するPartition Tableだけを選択的にAccessするという意味を含んでいます。
つまり、該当バインド変数の期間が1ヶ月であることに該当するため、PARTITION_TESTテーブルの特定のPartition Table一つだけにAccessする結果が予想されるのです。
実行結果を見ると、9,216 BlockをDisk I/OでTable Full Scanを実行し、この過程における所要の応答時間は0.08秒に過ぎず、データを抽出してGroupingを実行するのに約0.2秒が追加でかかり、合計0.29秒程度でNon Partition Tableに比べて性能面で優れた結果を確認することができます。
下記の記事(上記の実行計画上の9216ブロックは、下記のように実際のパーティションサイズであることが確認できます。そのため、複数のパーティションを生成して、バインド変数の値に該当するパーティションだけアクセスするテストを作ってPartition Pruningを説明する必要があるようです)
Partition TableのI/O SizeとPARTITION_TESTテーブルの特定のPartition Table Sizeの比較 :
上記の結果から、PARTITION_TESTテーブルの特定のPartition Table一つだけに正確にAccessしたことを推測することができます。
このように、抽出対象のデータが入った特定のPartition Tableだけを選択的にAccessすることをPartition Pruning効果といいます。
つまり、Partition Pruning効果が、Non Partition TableとPartition Table間の性能差の原因として作用したことを意味します。 業務的にPartition Tableへの移行が可能であれば、積極的に移行を検討することで、Partition Pruning効果によるI/O及び応答時間の効率を最大化することができます。
6.1.1.2 Composite Partition戦略
Partition Tableの必要性を性能的な側面から理解した皆様は今、そのサイズをさらに分割して分割がどの程度までできるのか?についての余地について考えるようになることでしょう。
まさにこの考えを可能にする方法はありますが、すでに広く知られているComposite Partitioning の技法です。
例えば、すでに月単位のPartition Tableで運営しているテーブルに対する業務の性質と、Access Patternを調査してみると、常に曜日条件が追加で入力されることを確認したと仮定しましょう。
この場合、各月別のPartition Tableを曜日別のデータでPartitionを追加で重複適用してComposite Partition Tableを構成すると、最終的に所望のデータをAccessするPartition TableのSize自体が従来に比べて約1/7程度より減少する効果を見ることができるでしょう。
(ただし、曜日別にデータの分布度が一定であるという前提条件がある場合を想定した状況である)
以下のテストを見てみましょう。
テストテーブルとデータ生成スクリプト :
単一のPartition Tableで構成した場合、結果として8,860 BlockのI/Oが発生しました。
これは、Partition Keyとして活用されたTime_id条件でのみAccessした結果です。
条件が追加されたDay_nameカラムもPartition Keyで構成した場合、その性能差はどうなるでしょうか?
既存のMain Partition KeyであるTime_idにSub Partition KeyでDay_nameを追加したRange-List Partition Tableを生成したスクリプトです。今、Range_List Partition Tableで構成したComposite_partitionテーブルを対象に同じSQLを実行した場合、どんな結果が出るのか?について見てみましょう。
結論から言うと、単一Partition Tableを照会する場合に比べてComposite Partition Table(Range – List)で構成した場合、約1/7程度のI/Oが減少することが分かりました。つまり、従来までは1つの条件だけでAccessしていたものを、2つの条件でAccessしたことで必要なPartition Tableだけを読み込むようになり、性能改善効果が得られたのです。
Oracle 11gバージョンを基準として Composite Partition はさらに多様化しました。
これらの性質を把握すると同時に、Access Pattern分析を実行して適用可能なテーブルがあれば、単一PartitionよりComposite Partition構成を積極的に検討する価値が大いにあります。
6.1.1.3 Partition Splitを活用したSizeストック
積極的Partitioningに関連するもう一つの焦点は、すでにPartitioningされたテーブルがどれだけよく管理されているかです。Partition Tableには、Default Partitionを指定する場合が最も一般的です。
これは、入力しようとするデータが現在分割されているどのPartition Tableにも属さない場合、Default Partition Tableを指定すると、そのデータはDefault Partition Tableに入力されます。
つまり、データ入力時に発生するエラーを最小化するためにDefault Partition Tableを指定するということです。
しかし、Default Partition Tableを指定した状況下で、そのPartition Tableに対する細心の管理が行われない場合には、Default Partition Tableが他のPartition Tableに比べて飛躍的にSizeが増加し、パフォーマンス問題につながる場合もあります。
この状況を例に挙げて説明していきます。
Default Partition Tableの管理が必要なケース :
必要なPartition Tableを生成した上でデータ入力をしてみました。
今、各Partition別にデータがどれくらい保存されたのか?についてSizeを照会してみることにしましょう。
PARTITION_TEST3テーブルは、月単位のRange Partitionで1998年1月から2001年1月までのPartition Tableを構成しており、これ以降のデータはMaxvalueで指定されてDefault Partition Tableに入力されるように構成されています。
データ入力後、Partition別Sizeを比較してみると、他のPartition Tableと比較してDefault Partition TableのSizeが圧倒的に大きいことを確認することができます。つまりこの結果から、2001年1月以降については当該テーブルに対するPartitioningが行われなかったことを意味しており、時間が経つにつれて、Default Partition Tableのサイズはさらに増加したことがわかりました。
これにより、2001年1月以降のデータを照会する業務では、約1ヶ月の期間に該当するデータだけを照会した場合においても、約2.4GBに相当する量のI/Oが必然的に伴うのです。
このような状況を招くのは、そのほとんどの場合において、管理の怠慢によるDefault Partition Tableのサイズが増加が主要因となりますが、Partition Split技法を活用することで、サイズが飛躍的に大きくなったDefault Partition Tableを再び簡単に月単位のPartition Tableに分割することができます。
Partition Split実行と結果確認 :
上記の結果を見てみましょう。
Split作業を通じて、異常なDefault Partition TableのSize増加による非効率が解消されたことを確認することができます。参考までに、下記のようにOracle 12C New Featureでは複数のPartitionに対するSplit作業を一度に実行できるようにしました。
Partition Tableをあらかじめ十分に生成しておいたり、Procedureなどを通じたPartition Tableの自動管理技法などを活用することで、このような非効率の発生を未然に防ぐことができます。
6.1.2 パーティションの切り替えができない場合
大量のデータを処理するSQLの性能改善戦略の中で最初に挙げたのは、積極的なPartitioningです。しかし、すべてのテーブルに対して適用できる事項ではありません。
特定のテーブルにアクセスするSQLのAccess Patternを調査した結果、常に共通的に入力される条件が存在しないか、現実的にPartition作業を遂行することが難しい業務環境である場合もあるだろうという理由からです。
この場合、広い範囲処理によるIndex ScanあるいはTable Full Scanでの非効率が発生することは自明なのです。
この時、テーブルのPartition切り替えをしなくても同じ性能効果を出すことができる案がGlobal Partitioned Indexの存在です。
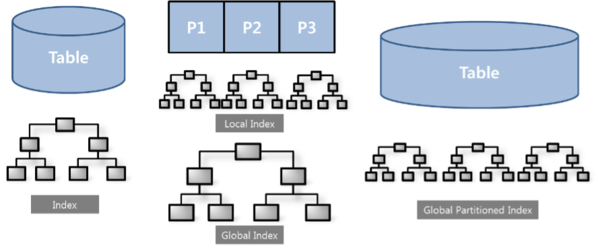
図[6-2]左の図にある Index は、一般テーブルに生成された一般的なIndex構造です。
そして、真ん中の図が、Partition Tableの Local Index と Global Index を図式化したもの、右の図では、Global Partitioned Indexが図式化されています。
Global Partitioned Index は、図にあるようにテーブルはPartition Tableではなく、一般テーブルです。
そして、Indexは Partition Table の Local Index と構造的に同じであることが特徴です。
これは、テーブルの Partition転換 が不可能な場合、IndexだけをPartitionの概念を適用して生成すると、特定の業務に限っては、あたかもPartitioningを通じた性能改善効果が見られるように適用することができます。
以下のテストで詳しく調べてみましょう。
Global Partitioned Indexの性能改善効果テスト :
下記のSQL実行結果を確認してみると、約51万BlockをI/Oし、8秒以上かかった結果が出ました。
また、全体の31万件を抽出した後に、Groupingを通じて31件が最終的に抽出されました。
Global Partitioned Indexを生成する以前では、Index Scanが可能なIndexも存在せず、Indexが存在しても31万件のTable Random Accessを避けることができないので、非効率が発生する可能性が高くなります。 そのため、Table Full Scanを実行するのですが、これもTable全体をScanしなければならない負担があります。
この時、Global Partitioned Indexを生成すると、入力されるTIME_ID条件に該当するPartition Inde セグメントのみAccessするため、まるでPartition Tableに切り替えたのと同じ効果を見ることができます。
また、Global Partitioned Index生成スクリプトで確認できるように、SQLに必要なカラムだけを記述したので、I/O対象セグメントのサイズがPartition Tableに切り替えたよりも小さい量をScanすることになります。
このように、Global Partitioned Indexの生成を適用することができれば、特定の業務ではPartition Tableに切り替えた場合よりも、より良い性能改善効果を見ることができるでしょう。
ただし、この点にフォーカスして言うと、Global Partitioned Indexの限界も明らかになってきます。つまり、Global Partitioned Indexを生成して効率を見ることができる業務は限られているということです。
ここで、上のSQLを例にして考えてみましょう。
業務が変更されて抽出されるカラムが変わる場合はどうなるでしょうか?
Where節のTIME_ID条件が削除されなければ、Global Partitioned Indexをそのまま使うことができます。しかし、Index Scanの方法は、従来のようにIndex Fast Full Scanで実行することはできなくなります。
Note. Index Fast Full Scanの動作方式は、Table Random Accessが必要な場合は、当該Scan方式を使用できないという特徴があります。
したがって、Index Fast Full Scan方式からIndex Range Scan方式に変更して実行すると同時に、31万件に相当する件数分だけGLOBAL_PARTITON_IDX_TESTテーブルをTable Random Accessするオペレーションが必然的に追加されることになります。こうなると、Global Partitioned Indexを生成して性能改善を図った本来の趣旨は無意味になってしまいます。作成意図を振り返ってみると、必要なデータだけの該当IndexセグメントだけをAccessするためだったためです。結局、SQLの変更が発生すると、変更されるカラムでGlobal Partitioned Indexを再作成しなければ、本来の趣旨に沿った改善効果を見ることができます。しかし、業務が変更されるたびにGlobal Partitioned Indexを再作成することは現実的に不可能であるため、結局、Global Partitioned Indexを適用できる業務環境がかなり制約的であるという欠点があります。
Global Partitioned Indexを適用する場合、Partition Tableへの移行が難しい場合において、特定の業務に限定して適用することができる改善策の1つに過ぎないと言う事を理解した上で適用を検討する必要があります。
6.1.3 Partition Tableの切り替え方法
先に紹介した方法の適用することが可能であるならば、大量のデータを扱う作業に対する性能改善 Processを取ることができるでしょう。しかしその一方で、もう一つの克服すべき難関がまだ待っています。
その克服すべき難関とは、Partition Tableへの変更が必要な部分に該当するものであり、膨大な量のデータを保存している既存のテーブルをPartition Tableに変更する作業が非常に大変であると言うことです。
一定時間Offlineが可能であれば、変更作業を試みることもできますが、常にサービス状態でなければならない環境において、Partition Tableを変更しなければならないとするならば、性能的な面においては、選択肢の1つとして正しいと言えるかもしれないものの、実務を担当するDBAにとっては、大きな戸惑いを与える結果を生む可能性があります。 しかし、この難解な問題も克服できる方法があります。
その方法はPartition Exchange(以下PE)機能です。
PE機能は文字通り、一般テーブルをPartition Tableに変更できることを意味します。
また、この作業による追加スペースも不要で、とても効率的な方法でPartition Tableへの転換を実現することができます。
以下のテストでは、PE機能を活用して一般テーブルをPartition Tableへ簡単に変換できることを証明しています。
上記のテスト結果から、既存のテーブルを簡単にPartition Tableに変更できることが分かります。ただ一点だけ注意するとすれば、既存の一般テーブルで持っていた制約条件(Primary Key)やIndex構成は、その全てを同じように作成しなければ、正常なPEを実行することができないので注意してください。
Partitioning技法は、大量データを扱う業務における性能改善のための前提条件です。
Partitioningが不可能な状況での性能改善には、様々な制約事項が存在するため、容易ではありません。
業務への十分な理解と、Access Pattern調査などの実行結果を踏まえて、性能改善が可能と判断した場合においてPartition Tableへの転換が必要となってくるのです。

次回のSQLチューニングブログは・・・
SQLチューニングブログ 2nd Season(第29回)
第6章「大量のデータ変更作業の性能改善戦略」
※ 次回は全5回シリーズの2回目をお送りしていきます。

