
Oracle SQLチューニング Season2(第26回)第5章 Dynamic SQLチューニング方法 (1/2)
今回のSQLチューニングブログ 2nd Season(第26回)からは「Dynamic SQLチューニング方法」についてお送りします。
まずは「 DynamicSQLとは何か?(チューニングの進行方法) 」について解説していきます。
それでは早速、はじめていきましょう。
5.1 Dynamic SQL とは
Dynamic SQLとは、特定の検索条件によってSQLが柔軟に変更されるSQL作成方式を意味します。
例えば、画面からCUST_ID(顧客番号)で照会する場合のみCUST_ID検索条件が含まれ、照会しない場合はSQLにその条件が含まれない。これを簡単に言うのであれば、画面の照会条件によってSQLに条件を追加する方式だと考えてください。
このような方式は通常、WebプログラムでXMLを活用してSQLにDynamicに検索条件を追加する方式でよく使われます。
以下は、複数の照会条件を持つ画面をXMLファイルを活用して照会条件をDynamicに実装した例です。
XMLの内容を見ると、特定の条件値で検索する場合のみ、SQLのWhere節に追加されるように書かれています。
このように実装されたSQLをDynamic SQLと言います。
また、Dynamic SQLには多くの利点があります。
まず、様々な照会条件を持つ画面の照会SQLに柔軟に対応できる点です。
これは、特定の検索条件の追加や削除によるプログラムのメンテナンスの面で非常に効率的です。
次に、既存の実装方式に比べて性能面で優れている点です。
SQLに必要な検索条件だけが追加されるため、SQLの複雑度が減少し、オプティマイザが効率的な実行計画を策定する確率が高くなり、単一SQL処理に比べてWhere節の条件に加工を加える必要がないため、パフォーマンス問題の把握及び解決案をより簡単に導き出すことができます
以前のWebプログラム開発時には、様々な条件を持つ画面に対する処理については、XMLを活用する前に、単一のSQLでプログラムを作成(性能管理が容易ではない、改善方法としてUNION ALL形式でSQLを再作成する方法を多く使用)したり、複数のSQLで分離してプログラムを実装する(プログラムソースが長すぎる)、またはプログラムでIF構文を利用してWhere節に照会条件をAPPENDする方法(ソース管理が難しく、改善方法の適用をすることが難しい)などの手法を用いてプログラム開発が行われていました。ところが、数年前からは作成しやすく、プログラムソース管理も簡単なXMLファイルを使用しながらDynamic SQLで実装するようなプログラムが多くなってきています。
XMLを活用して作成されたDynamic SQLは、過去に開発したWebプログラムに比べて性能面やメンテナンス面で利点はありますが、性能問題が発生したときの改善策をDynamic SQLの特性に合わせて適用しないため、深刻な性能問題を引き起こす可能性があるという欠点があります。
それでは、Dynamic SQLが実際の業務において、どのような手順で性能改善が行われるのか?を見ていくことにしましょう。
その上で、性能改善時において注意すべき点についてを説明していきたいと思います。
5.2 Dynamic SQLチューニングの進行方法
以下の画面は、特定の顧客の ** 保険業務で使用しているWeb画面の一つです。
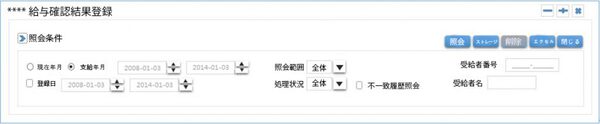
照会条件部分を見てみると、支給年月と現在年月はどちらか一つは必ず照会される基本条件となっており、照会範囲、処理状況、受給者住民番号、受給者名は、画面を照会するユーザー側が照会するかどうか?を決定するようになっています。このような場合では、Web画面でユーザーが照会するパターンによってWhere節の構成も違ってきます。
上記のような実装になっているため、初期画面ではすべての条件をWhere節にリストするためにCase[1]のようなSQLで作成しました。ところが、このように作成されたSQLは、オプティマイザが、どの条件が入力されるのかを分からない状況で実行計画を策定するため、性能を保証することができませんでした。また、オプティマイザーの立場から考える場合、最もコストが低い実行計画を策定しなければならず、条件の中で最も効率的な受給者住民番号条件でインデックススキャンを実行する実行計画を策定することになります。もし、受給者住民番号の条件が入力されない場合が多かった場合、Case[1] SQLは、DBサーバーに性能問題を引き起こす原因になる可能性があります。
このような場合、Dynamic SQL (必要条件だけAPPEND)で作成することが非効率を取り除くことができます。
Note: 通常、Web画面で様々な検索条件が必要な場合に作成するDynamic SQLはWhere節が違うので、それぞれ違うSQLとして認識し、Hard Parsingが多くなります。
図 [5-1] は今回のテーマで説明するWeb画面であり、下記のXML内容は画面で使われるSQLと動的に追加されるWhere節の条件が定義されている内容の一部です。
ここからは、この画面とXMLファイルの内容でDynamic SQLについて説明していきたいと思います。
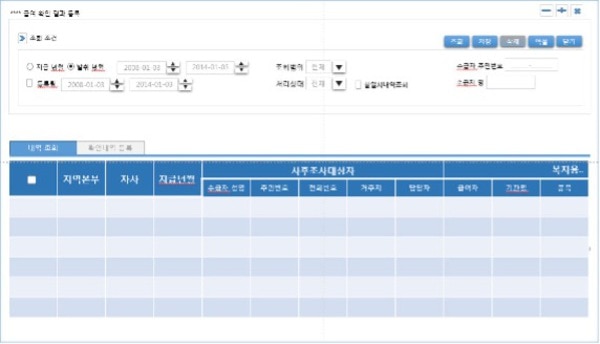
下のSQLは上の画面のSQLを定義したXMLファイルの一部内容です。
Dynamic SQLで実装された画面に対する性能改善は、通常、単一SQLで実装された場合とは異なります。
照会パターン別に性能分析を行った後、改善案を導出しなければならないため、単一SQLで実装された画面に比べて性能改善作業を進めることがかなり難しいと言えます。
なぜなら、組み合わせられる照会条件が多いと、分析自体が難しい場合が多く、特定の照会パターンに対する改善案を導出したとしても適用すること自体が難しいからです。
そこで今回のテーマでは、Dynamic SQLのチューニング作業の進行手順と各段階について詳しく説明します。
5.2.1 Step1. SQL照会条件の把握
5.2.2 Step2. SQL照会条件分析データ収集
5.2.3 Step3.照会条件別効率チェック(改善案の導出)
5.2.4 Step4. XMLソースの修正と適用
5.2.5 Step5.改善案適用後のモニタリング
5.2.1 Step1. SQL照会条件の把握
Dynamic SQLの性能改善時、最初に実行しなければならない作業は、SQL照会条件を詳しく把握することです。どのテーブルのカラムで照会がされるかを先に把握しなければ、各照会条件によって発生する可能性がある状況に適切に対処することができます。なぜなら、照会条件カラムによってSQLのAccess Pathが決定されるからです。 つまり、効率的な照会条件カラムを持つテーブルが先に実行されるようにし、先行テーブルから抽出されたデータと結合条件カラムを把握した後、結合方法とデータアクセス方法が決定されるため、SQL照会条件を詳しく把握する必要があります。
この作業は検索条件が多い場合には、照会条件間の関係を把握するのが難しく、エクセルファイルなどを活用するのが効率的です。
そして、各テーブル及びWhere節の照会条件を分かりやすく整理した上で、全てのSQL照会パターンを把握する必要があります。
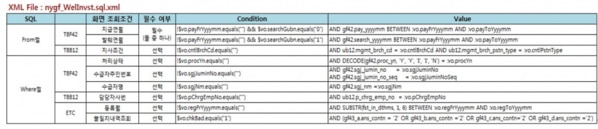
5.2.2 Step2. SQL照会条件分析データ収集
先にSQLの照会条件を整理した後、整理された文書を基に照会条件及びジョインカラムの効率性を確認するために必要なデータを調査します。各照会条件の効率を確認するために、インデックスの存在有無とそのインデックス及び検索条件、ジョインカラムのCardinalityやDistinct Valueなどを確認しなければなりません。 なぜなら、各照会条件の効率を確認できる情報を収集しなければDynamic SQLの性能改善案を導き出すことができないからです。この段階では下記のように基本的な情報を調べて整理しておきます。
5.2.3 Step3.照会条件別効率チェック(改善案の導出)
先にDynamic SQLの検索条件を把握し、該当テーブル及び検索条件の効率を判断できるデータを抽出し、そのデータを利用して各照会条件別の効率を分析し、改善案を導き出す作業を行います。ここで最も重要な部分は、すべての照会条件カラムの効率順を決めることです。
導出された順序がそのまま結合順序になります。
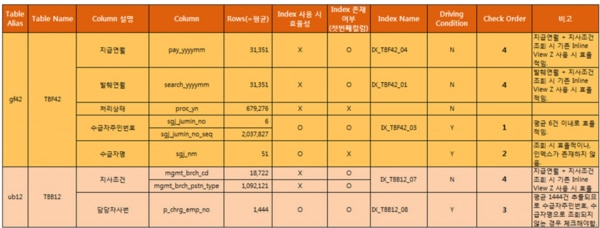
Note: 照会時に平均抽出されるデータ数を確認して、各照会条件の効率を判断します。
- 下記の式を利用して平均抽出されるデータ数を照会します。
内容をまとめると以下のような順序になります。
最も効率的な照会条件の順序
受給者住民番号 → 受給者名 → 担当者番号
→ 支給年月日+支社条件or抜粋年月日+支社条件
先に導出された照会条件の順番は、このように処理すれば良いのです。
受給者住民番号が照会される時は、無条件に受給者住民番号で先に実行させ、受給者住民番号が照会されない場合には、受給者名で照会されるかを確認した上、もし受給者名で照会された場合には、その条件下でSQLが先に実行されるようにします。又、先に整理したすべての照会条件をこのようにプログラムへ適用すれば良いのです。
ここで重要な点は、最も効率的な照会条件から実行されるようにSQLの実行計画を誘導すればいいという点です。
インデックスを新規作成する必要がある照会条件
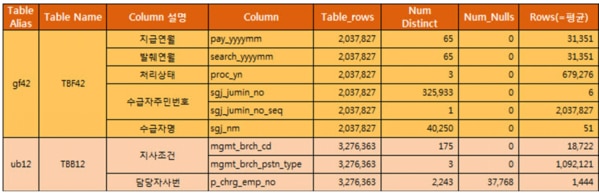
下の図 [5-5]はStep3で調査したすべてのデータを示しています。
整理したすべての情報を基に、効率的な照会が可能なカラムのうち、インデックスが存在しないカラムを選別します。
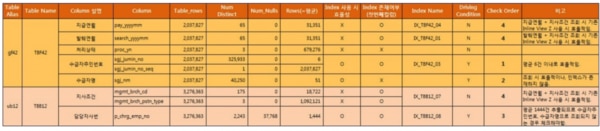
図を見てみると、受給者条件であるTBF42テーブルのsgj_nmカラムにインデックスが生成されていません。このカラムは=照会時に平均51件だけ抽出し、インデックス作成時に効率的な照会ができることが分かるので、追加的な改善案としてこのカラムにインデックス作成を検討します。
5.2.4 Step4. XMLソースの修正と適用
改善案が導き出されたら、次は適用する(XMLファイルに適用する)番です。Step3で説明したように、照会条件の効率順を守ってXMLファイルに反映すればよいです。Step3で分析した内容をXMLファイルに適用する時、以下の順序で改善案を適用するようにします。
XMLファイル適用時の条件確認手順
受給者住民番号 → 受給者名 → 担当者番号
→ 支給年月日+支社条件or抜粋年月日+支社条件
多くのタイプのXMLがあるので、コードを理解した後、プログラムに改善案を適用する必要があります。先に整理した内容をXMLファイルに適用する前に簡単に下記の構文の理解をしましょう。
それでは、条件確認順序に合わせてXMLファイルに導き出された改善案を適用してみましょう。
例えば、”支払年月日+支社条件”で照会されるパターンのSQLが性能問題がある場合、改善案を適用順序[4]のように適用していきましょう。
5.2.5 Step5.改善案適用後のモニタリング
性能改善案を反映したら、最後に改善及び反映がうまく行われたかモニタリングを行う必要があります。
Dynamic SQLの場合、改善案を導出する作業も重要ですが、改善案を正しく反映して、当該プログラムが問題なく実行されることを確認する作業が何より重要です。改善案を導出する作業時にまだ発見できなかった別の照会パターンがあったり、改善の余地が残っていて追加で改善作業を適用しなければならないケースが存在することがあるためです。

次回のSQLチューニングブログは・・・
SQLチューニングブログ 2nd Season(第4章)
「 Dynamic SQL チューニング適用時の注意事項・Dynamic SQLにヒントを適用する」

