
Oracle SQLチューニング Season2(第20回)第4章 SQL TuningとHINTの関係 (3/8)
「 SQL TuningとHINTの関係 」の第3回目、「 データアクセスに関するヒント 」についてお送りしていきます。
今回は「HINTの種類と使い方」についての第2回目です。
4.2.3 データアクセスに関するヒント
データアクセス方式は、照会対象となるデータをどのような方法で抽出するかについての方法を指します。
データアクセス関連のヒントは、結合接続カラムを利用したIndex Scan、テーブル自体の定数条件を利用したIndex Scan、テーブル全体を読むTable Full Scan、インデックス全体を読むIndex Fast Full Scanなどを制御するときに使用するヒントです。
SQLの形態やテーブル間の関係、Where節の効率性などによって適切なデータアクセスタイプを決定する必要があります。
・FULL
使用バージョン:8.1.0〜。
使用方法: /+ FULL(T1) */ /+ Full(T1)
ヒント意味:T1テーブルのデータアクセスをTable Full Scanで誘導するヒント
Table Full Scanで実行する場合にFULLヒントを使いますが、通常下記のような場合に使います。
- ジョインカラムにインデックスがなく、定数条件もないHash Joinで実行する場合
- インデックススキャンの非効率が大きい場合
- Parallel QueryでIndex Fast Full Scanで実行できない場合
- ExadataのSmart Scanで行う場合
しかし、Table Full Scanで絶対に実行してはいけない状況もあります。
下記の場合はFULLヒントを適用してはいけません。
- SELECT COLUMN節にあるスカラーサブクエリ
- Nested Loops Joinで実行する後行テーブル
- Filter方式で実行されるサブクエリ
- 繰り返し実行するLOOP構文内のSQL
・INDEX
インデックス関連のヒントは、どのインデックスをどの処理方法で実行するかを決めることです。
インデックスの処理方法はいろいろありますが、状況によってどの処理方法を適用すれば性能を改善できるかを選択する必要があります。そのためには、インデックス処理方法の種類とその意味を知る必要があります。
以下でインデックスヒントの種類別の例と説明を通して詳しく説明します。
・INDEX(T1 IDX03_HINT_T3)
使用バージョン:8.0.0
使用方法: /*+ INDEX(T1 IDX03_HINT_T3) */ (Inverse: NO_INDEX)
ヒント意味:HINT_T3テーブルのIDX03_HINT_T3 Indexでデータアクセス
一般的にIndex Scanの中で最も多く使用される処理方式はIndex Range Scanで、その方式から説明します。

- Step1. C1 >= 5の条件を満たす最初のKey値を見つけるために、Index Root Block(#7)とBranch Block(#4)を探索します。
- Step2. C1 >= 5 の条件を満たす最初の Leaf Block(#4, #5, #6) を探索して、5と6のRowidでテーブルをRandom Accessして、テーブル Block の C2 値を返します。
- Step3. C1 <= 9という条件を満たすまでLeaf Blockはソートが保証されて値が入力されるので、Leaf BlockをSequentially読みながら条件を満たす最大値である9があるLeaf Block Entryのrowed値でテーブルRandom AccessしてColumn C2 値を返します。
- Step4.ただし、そのkey値が重複している可能性があるので、Index Key値が9を超える値までIndex Leaf Blockを探索し、9を超える値10に出会った瞬間、Index Range Scanを停止します。
Index Range Scanは、Index Keyの保存方法によって基本的にソートが保証されるという利点もあります。
しかし、上記の実行方法を見ると、欠点も明確に存在することが分かりますが、これはデータ処理範囲が広い場合、Table Random Accessの量が多くなり、むしろインデックスを経由する実行が性能に悪影響を与える可能性があるという点です。正確には、インデックスから必要なデータにアクセスするためにテーブルブロックを訪問する回数が多くなればなるほど、応答時間とI/Oの面で性能上不利になるからです。
Index Range Scan方式だけでなく、インデックスの実行方式で最適な性能を決定する要素は、結局、インデックスブロックだけでアクセスする場合を除いて、Table Random Accessの量をどれだけ減らすことができるかにかかっています。
基本的にIndex Range Scanを誘導する方法はヒントで制御しますが、INDEX(table_alias index_name)のような形で誘導することができ、Oracle 10g以上のバージョンからはINDEX_RS(table_alias index_name)のような形で直接処理方式まで決めることができます。
また、インデックスはデータがソートされており、DescendingあるいはAscendingの形でデータ処理が可能です。
・INDEX(T1(COL1 COL2))
使用バージョン:10g〜。
使用方法: /+ INDEX(T1(COL1 COL2))/ (Inverse: NO_INDEX)
ヒント意味:HINT_T3テーブルにCOL1、COL2カラム順に構成されたインデックスでデータアクセス
INDEX(T1(COL1 COL2)) ヒントは、T1 (Table Alias) テーブルに COL1 + COL2 の順に生成されている結合インデックスを使用してデータ処理を行います。
インデックス構成がCOL1 + COL2 [+ COL3 …] で生成されていても使用することができます。
開発DBで生成したインデックス名が運用DBに移行する時、インデックス名が変わることがあります。
開発時に性能改善のためにインデックスヒント(インデックス名でヒントを適用)を適用した場合、運用環境で当該SQLの性能を再確認する必要があります。なぜなら、運用DBにはないインデックス名のヒントはオプティマイザによって無視されるからです。
このような場合、インデックス構成カラムでインデックスを使用するように誘導できる INDEX(T1(COL1 COL2))
ヒントを使用すると、このような問題を未然に除去することができます。
・INDEX_DESC
使用バージョン:8.1.0〜。
使用方法: /*+ INDEX_DESC(T1 IDX01) */ (Inverse: NO_INDEX)
ヒント意味:T1テーブルのIDX01 IndexをDescendingソートを実行した後、Accessする。
T1テーブルのIDX1インデックスを降順ソートを処理して実行するように誘導するヒントです。
インデックスデータは基本的にソートが保証されるので、INDEX_DESC, INDEX_ASC のようなヒントを使用して降順、昇順でデータにアクセスすることができます。
通常、INDEX_DESCヒント、ORDER BY節、ROWNUM構文を一緒に使うSQLが多いですが、このような場合には、インデックスがUNUSABLEになったり、インデックスが削除されるとデータの整合性が崩れる可能性があるので避けた方が良いです。
下記の使用例のようにINDEX_DESCヒントとORDER BY節を同じにした後、ROWNUM処理をするようにSQLを作成する必要があります。
WHERE節とORDER BY節のカラムに合わせてインデックスが構成されている場合、下記の実行計画のように別途SORT ORDER BY操作なしでソートされたインデックスデータだけでデータを抽出することができるので、SQL性能とデータ整合性の両方を得ることができます。
・INDEX_FFS
使用バージョン:8.1.0〜。
使用方法: /*+ INDEX_FFS(T1 IDX01) */ 使用方法
ヒント意味:T1テーブルのIDX01インデックスをIndex Fast Full Scanで実行したいときに使用されるヒント。
Index Fast Full Scan方式は、インデックス全体のデータを探索する際に最も速い方法です。
Index Fast Full Scan の核心は Multi Block I/O を使用することです。
Multi Block I/O 方式で探索するため、ソートが保証されたScan方法ではありませんが、それだけ速い探索は可能です。
さらに、Parallel実行も可能です。
ただし、Index Fast Full Scanで実行するためには、SQLで使用される全てのカラムがインデックスカラムでなければならないという制約があります。
・INDEX_SS
使用バージョン:9.0.0
使用方法: /*+ INDEX_SS(T1 IDX01) */ (Inverse: NO_INDEX_SS)
ヒント意味:T1テーブルのIDX01インデックスをIndex Skip Scanで実行したいときに使用されるヒント。
インデックスの先頭カラムがWhere節で使用されていない場合、Oracle 8iまではインデックスの使用ができませんでした。しかし、Oracle 9i以降のバージョンからIndex Skip Scanという実行方式を提供し、インデックスの先頭カラムがWhere節に使用されていなくてもインデックスの使用が可能になりました。また、INDEX SKIP SCANはRootまたはBranch Blockから読み込んだ値を利用して、条件に適合する値を持つ可能性があるLeaf Blockだけを選択的にアクセスする方式で、Oracle 10gバージョンからは先頭カラムが=でない場合や先頭カラムは照会されるが、インデックスカラムのうち中間値は照会されない場合にも使用してSQLの性能改善に使用されます。
このような INDEX SKIP SCANは、インデックス先頭カラムのNDV(Number of Distinct Value)値が小さいほど、後続カラム(Where節で指定されたカラム)のNDV値が大きいほど有利です。
この部分は、インデックス先頭カラムが照会される場合と、照会されない場合の両方に適用される内容です。
下記の例を使用し、INDEX SKIP SCANについて詳しく説明します。
WHERE節の条件のうちYYYYMMに対するBETWEENは2011年1年間のデータで、テーブル生成データと同じ10万件です。
テストのため、上記のようにテーブル、インデックスを生成した後、CASE#1,2の例を使ってインデックスの実行方法をINDEX SKIP SCANに変更しなければならない場合について説明します。
SALES_SUM_IDX1インデックスに対するRANGE SCANを実行して合計8334件を抽出し、280ブロックをアクセスしました。通常、開発DBでテストを行う場合、運用環境での実行頻度やデータ量に対する正確な情報が乏しく、上記のようにテストを行った場合、SQLが持つ非効率を把握することは難しいのです。CASE#1の場合、0.15秒かかり、280ブロックを処理した後、実行が完了したため、性能が遅くないと判断できます。
しかし、CASE#1は非効率的な実行です。
- インデックス構成 : YYYYMM + GUBUN
- WHERE節の条件 : BETWEEN(YYYYMM), =(GUBUN)
- データ件数 : BETWEENデータ件数 -> 10万件、最終抽出件数 -> 8334件
インデックスアクセスカラムであるYYYYMMで10万件のデータをアクセスした後、GUBUN = ‘A’の条件でFilter処理後、最終的に8334件を抽出しました。上記の解釈で今後の運用環境で発生する可能性がある問題点として、YYYYMMで抽出されるデータ件数がテスト時のデータ件数に比べて多くなれば、インデックスで処理されるブロック数は多くなると予想されます。
また、実行回数が多いプログラムであれば、性能問題を引き起こす可能性があります。
したがって、CASE#1のINDEX RANGE SCANで発生したデータアクセスブロック数を減らす方法を模索しなければなりません。
INDEX RANGE SCANをINDEX SKIP SCANに変更して実行した結果、CASE#1に比べて約10倍のI/O改善効果が見られました。上記のようにインデックス先頭カラムが照会されない場合ではなくても、先頭カラムで抽出されるデータ件数が多く、後続カラムで多くのデータを減らす形であれば、INDEX SKIP SCANを使用する方が効率的な場合が多くあります。
さらに、INDEX SKIP SCANを実行するためには、”_optimizer_skip_scan_enabled”パラメータがTRUEに設定されている必要があります。
・INDEX_COMBINE
使用バージョン:8.1.0〜。
使用方法: /*+ INDEX_COMBINE(T1 IDX01 IDX02) */ 使用方法
ヒント意味:T1テーブルのIDX01とIDX02インデックスを利用して処理(Bitmap Index Conversion)後、データを抽出したい時に使用するヒント。
BTree Index Combination技法は今まで紹介したインデックス実行方式とは違う探索方法で動作します。先に紹介したインデックス実行方式は一つのテーブルに一つのインデックスを使ったものであるのに対し、これから紹介するBTree Index CombinationとIndex Join方式は一つのテーブルにN個のインデックスを使う方式だからです。
このうち、BTree Index CombinationはBTreeインデックスをBitmapインデックスのように使うことが特徴です。
下記のSQLを使って、なぜB*Tree Index Combinationを使う必要があるのか説明します。
上記のSQLはWHERE節の2つの条件にそれぞれインデックスが生成されており、各インデックスから抽出されるデータが10万件でCUSTテーブルのデータを抽出するために発生するRANDOM ACCESS I/Oが多すぎて性能遅延が発生しています。
“では、このような場合、どのような改善方法を選択するのでしょうか?”
最も簡単な改善方法として、性別+地域で結合インデックスを追加することです。性別や地域によって抽出されるデータはそれぞれ10件ですが、両方の条件を満たすデータ件数は100件で、結合インデックス作成時にインデックスから抽出されるデータは100件に大幅に減少するため、従来発生していたTABLE RANDOM ACCESS I/Oによる性能問題は解決が可能です。
“ところで、インデックスをすぐに生成することができません。 テーブルのサイズが大きすぎて、すぐに改善しなければならないのですが、他に良い方法はないでしょうか?”
このような場合にBTree Index Combinationの方法を使います。
Index CombinationはもともとBitmap Indexだけに適用された動作方式ですが、OLTP環境でBitmap Indexは深刻なDML Lockingを引き起こし、使うこと自体が難しいのです。 そこでOracleはOLTP環境で上記のような特殊な状況を解決するためにBTreeインデックスに対してIndex Combination方式を導入しました。
そして、BTreeインデックスに対するIndex Combinationに誘導するヒントがINDEX_COMBINEとなります。
BTree Index Combinationの動作方式は以下の通りです。
- Step1. Index ScanでB*Tree IndexのKeyとRowidの値を読み込みます。
- Step2. Key値とRowid値をBitmap値に変換します。
- Step3. Bit演算により目的の結果(Bitmap値)を導き出します。
- Step4. 算出されたBit値を再びRowidに変換して、目的のデータを抽出します。
・INDEX_JOIN
使用バージョン:8.1.0〜。
使用方法: /+ INDEX_JOIN(T1 IDX02 IDX03) */ /+ index_join
ヒント意味:T1テーブルのIDX01とIDX02インデックスを利用して処理後にデータを抽出するときに使用するヒント
INDEX JOINは、BTree Index Combinationと基本的に似た性質の探索方法を持っています。
BTree Index Combination機能がない時は、複数のインデックスを同時に使用できる唯一の方法がINDEX JOINです。
まず、INDEX JOINはどのような方法で行うのか見てみましょう。
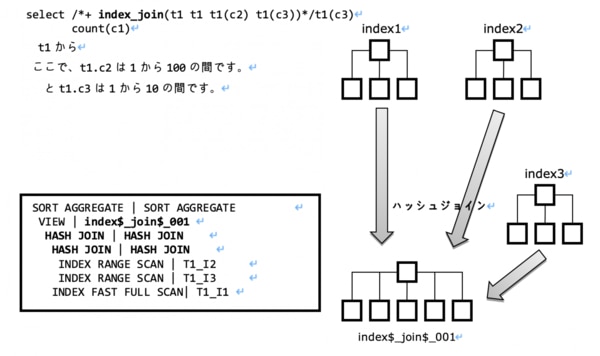
実行計画を説明すると、
- まず、T1_I2インデックスとT1_I3インデックスをそれぞれIndex Range Scanで読み込んでHash Joinを利用してJoinします。
- 上記で結合した結果を T1_I1 インデックスを Index Fast Full Scan で読み込みながら Hash Join を実行します。その結果は Index$_Join$_001 という Temporary Object に保存されます。
上の説明を見ると、一つ変わった点があるのですが、Table Access By Rowidというオペレーションが見当たらないということです。
もちろん、インデックスブロックだけを読んで処理が可能だと仮定することができますが、実際にINDEX JOINの場合、Table Random Accessが必要な場合にはINDEX JOINを実行することができません。
そのため、インデックスを実行した後、テーブルのデータにアクセスする場合はINDEX JOINを使うことができないので、使用自体が非常に制限的です。
・USE_INVISIBLE_INDEXES
使用バージョン:11.1.0.6〜。
使用方法: /*+ USE_INVISIBLE_INDEXES */ (Inverse: NO_USE_INVISIBLE_INDEXES)
ヒントの意味:IndexのVisible(使用可能)かどうかを決定するヒント
Oracle 11.1.0.6バージョンから、インデックス作成オプションにINVISIBLE節が追加されました。
INVISIBLE属性を指定すると、インデックスは生成されセグメントとして存在しますが、インデックスが存在しない(オプティマイザが知らない)ように設定され、プログラムでインデックスを使用することができません。
“ところで、生成されたが見えないように設定するInvisible Indexをなぜ追加したのでしょうか?”
理由は、インデックスを運用環境に反映する前にSQLの性能を事前に点検するためでしょう。
一般的にSQLの性能問題を解決する方法として最も多く使われる改善案がインデックスを再調整する場合が多いからです。
この時、DBサーバーの安定的な運営のためには、インデックスを新規作成したり、変更することで発生する可能性のある問題を事前に予測する必要があります。性能改善のために作成または変更したインデックスが、むしろ、DBサーバーの性能問題を発生させる原因となる問題を防ぐことができるからです。
ところが、実はOracleは8iにNo Segment Index (Virtual Index)を追加して、インデックスが物理的なデータを持っていないが、SQLの実行計画を確認できるような機能を提供しました。 しかし、実行計画は確認できますが、Clustering Factorによるコストは計算されないため、実際の処理量を正確に知ることができず、インデックスをDBサーバーに反映したときの影響を正確に判断することが事実上不可能だったのです。 したがって、このような理由からOracleは11gにInvisible Indexを追加したと判断されます。
このような場合、Invisible Indexを下記のように使用すれば、インデックス再調整による性能問題は回避できると期待されます。

次回のSQLチューニングブログは
SQLチューニングブログ 2nd Season(第4章)
「SQL Tuning と HINTの関係」(4/8) HINTの種類と使い方(第3回)

