

2023.01.06
IBM JVM GC
IBM JVM GC
(株)エクセムコンサルティング本部/APMチームキム・ジョンテ
概要
この文書は、IBM JVMのメモリー構造とGarbage Collectionの動作原理に関するものです。 本文の内容を通じて、Garbage CollectionによるSuspend現象とApplication Thread、Garbage Collection Threadとの競合を理解し、さらに特定の環境に適したGarbage Collectorを選択できる知識を提供する目的で作成されています。
1. IBM JVM の Heap Memory 構造
Hotspot JVM は Generational Heap 構造で、各世代別 (New, Old, Permanent) で Memory
領域が分離されています。 つまり、生成されたObjectが若いものはNew、古いものはOld、Objectがインスタンス化されるために参照されるクラスメタ情報は、Permanent Areaに割り当てられます。
さらに、Garbage Collectorは、これらの領域ごとに異なる方法でGarbage Collectionを実行します。
一方、IBM JVMは基本的にOne Heap構造であり、Java 1.5バージョンからはHotspot JVMのようにGeneral Heap構造を使用することもできます。
1 .1 IBM JVM Heap ゾーン固有の説明 (Java 1.4 以下)

One Heap構造では、Heapbase(Heap Memoryの最初のアドレス)からHeaptopまで拡張可能で、HeaplimitはHeapの最小サイズを意味します。
Heapbase ~ Heaptop までは -Xmx オプションで設定される値であり、-Xms オプションで初期 JVM の Heap Size を設定できます。
そして、Heaplimitは-Xmsに設定された値を下回ることはできません。
1.1.1 K Cluster, P Cluster
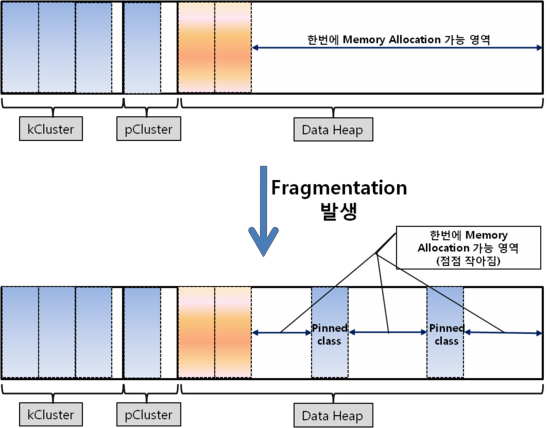
Pinned Class Object(K Cluster)、Pinned Object(P Cluster)が割り当てられるところで、Default 1280個のClass Entriesが保存可能で、Hotspot JVMのPermanent Areaと同様の役割を果たします。
K ClusterがいっぱいになるとP Clusterに割り当てられ、P Clusterがいっぱいになると2kbyteの新しいP ClusterがHeapの領域に任意に生成され、これによりHeap Fragmentationが発生することもあります。
1.1.2 Heap
生成されたObjectが割り当てられる領域です。
1.1.3 Cache
Cache Allocation のための THL (Thread Local Heap) と 512byte 以下の小さな Object を割り当てるために使用される領域です。 THLはヒープロックを回避するために使用されます。THLの詳細については後で説明します。
1.1.4 Wilderness OR LOA
Large Objectの割り当てを効果的にするための空間で、主に64kbyteのObject割り当てに使用されます。
常に64kbyte以上のObjectが割り当てられるのではなく、Heap Fragmentationなどの理由でHeap領域にObject割り当てが不可能な場合、64kbyteより小さい一般Objectが割り当てられることもあります。
1.2 Java 1.5バージョンから変更されたヒープ構造

Java 1.5バージョンでは、上記のようにPinned Cluster Area(K Cluster、P Cluster)がなくなっています。
これに変わった理由は、Pinned ObjectによるHeap Fragmentationの問題によるものです。 Pinned Objectとは固定されたObjectと呼ばれ、原則としてJavaにおいて、すべてのObjectはGarbage Collectorを介してヒープ内で移動できるようになっています。
ただし、一部の特殊なケースでは、Garbage Collectorが移動できないObjectがあります。 たとえば、JNI(Java Native Interface)で使用されるObjectは、JNIから直接Unpinnedされるまで固定されます。
また、Classのメタ情報も固定領域として指定されます。
そうすると、実際のPinned ObjectsはGCによるCompaction作業は不可能です。
このため、Pinned clusterという領域を置き、その領域にPinned Objectを別々に保存します。
問題は、これらのPinned cluster領域よりも多くのPinned Objectが発生すると、Pinned Objectを格納するためにHeap領域にPinned Objectのためのスペースを任意に割り当てることです。
そのような空間は一時的に存在しても、恒久的な空間であっても良い空間となります。
このような現象が発生すると、ヒープに一度に割り当てることができる一連のメモリがますます減るようになり、後にはあまり大きくないオブジェクトを割り当てようとすると、Allocation failure(以下AF)が発生することになります。 Java 1.5バージョンでは、これらの問題を解決するためにPinned Objectの保存をJVM HeapではなくSystem Heapに保存するように変更します。
IBMが提供するDiagnostic 1.4文書を見ると、「Avoid Fragmentation」パーツを通じてフラグメンテーションの部分を扱っていますが、1.5文書ではその内容が削除されてます。
これにより、暗黙的にIBM JVMでFragmentation問題を解決したことがわかります。 ちなみに、1.4バージョンで発生するHeap Fragmentationの問題は、K ClusterとP Clusterのサイズを適切に調整(-Xk、-Xpオプションを使用)することで解決できます。
1.3 Heap Allocation
IBM JVM は、生成される Object に Heap を割り当てられたときの Memory Corruption 防止のためデフォルトではHeap Lockを使用します。
もっと正確に話しますと、512バイト以上のオブジェクトHeap に割り当てるときは Heap 全体に Lock をかけた後 Free List を探索します。
以降、フリーチャンクを獲得したらヒープロックを解除、フリーチャンク が見つからなければGCを実行した後、再びフリーチャンク獲得を試みます。
この時、Free Chunkを見つける方法はFirst fit方式です。
つまり Free List で見つかったFree Chunk が Object のサイズより大きくても、一度割り当てて Object だけ使用され、残りの部分 Free List で返します。
残りのスペースが512Bytes以下であれば返却を行わず、このスペースをDark matterといい、GC中のCompaction段階で除去されることになります。
Objectサイズが512 Bytesの場合、Heap cache(=Thread local Heap(以下TLH))領域に割り当てます。 TLHはHotspot JVMのTLAB と同じ機能で、各 Thread に排他的空間を割り当てて高速な Allocation を可能にする機能です。
このため、512Mbyte以上のObjectを割り当てるときにもCache領域に割り当ててTLHを利用することもあり、TLHを利用すればHeap Lockは使用します。
さらに、IBM JVMはGCで高速MarkにAllocbits、Mark bitsを使用します。
Allocbitsは割り当てを表示するBit vectorと呼ばれることがありますが、TLHを使用したときにAllocbitsに書き込まれるのは、TLHがFullになるか、GC発生直前にThreadにTLHを割り当てる時ではないのです。
Allocbits、Mark bitsは後で詳しく説明します。
2. IBM JVM Garbage Collection
IBM JVMのメモリ構造とオブジェクト割り当ての基本的な内容を見ていきます。
本格的にIBM JVM Garbage Collectionについて話しましょう。
IBM JVMが提供するCollectorは基本的にYoung / Old Generationの区別を使用しないため、Minor GC(Copy)、Major GC(mark and sweep)などの区別も存在しません。
代わりに、メモリを整理する一連のプロセスをMark and Sweep + Compactionに分けます。 Mark and Sweepのステップは、「第1四半期のホワイトペーパー:Sun JVM GCドキュメント」ですでに述べています。
いわゆる Stop the World ジョブで Application Thread を停止した状態で Alive Object を Mark して (Dead Object を探して) Collection する作業を行います。
しかし、IBM JVMはMark and Sweepステップを非常に「軽い」作業と見なします。
ただし、このステップはSun JVMのMajor GCと同様の属性を持っていますが、Major GCと比較して単純な作業で実装されています。
Sun JVMのMajor GCと同様の作業は、Compactionフェーズで発生します。
Mark and Sweep で Memory の整理を行った後でも Object 割り当てに必要な余裕 Memory が見つからないと、 Compaction、つまり高コストの圧縮作業が発生します。
Mark and Sweep 作業は単に Dead Object を整理する作業であるのに対し、 Compaction 作業は散在した Free Memory を合わせる作業をするため、Mark and Sweep ステップに比べて多くの時間を要します。
幸いなことに、一般的にCompaction操作はまれです。
Mark and Sweep ステップを経たにもかかわらず、Object 割り当てに必要な Memory が見つからない理由は断片化 (Fragmentation) にあります。
IBM JVM の Mark and Sweep は Compaction 作業をしないため、Free Memory があちこちに散らばる現象が生じるようになります。
この場合、合計1MのFree Memoryが存在しますが、20Kの連続したMemoryは割り当てられません。
このような場合には、Compactionジョブがさらに発生することになります。
Hotspot JVMではMajor GCを最適化するのがHeapチューニングの代表的な手法のように、IBM JVMではCompactionを減らすのがHeapチューニングの代表的な手法です。
ちなみに、IBMが提示するHeapチューニング技術の1つが長さの長いArrayを使用しないことです。
この技法の根拠がまさにヒープの断片化にあります。
アプリケーションが一定時間動作すると、必然的に断片化が発生します。
このようなときに長さが長い Array を使用すると、連続した一連の Memory スペースが割り当てられず、 Compaction ジョブが発生することになります。
したがって、効果的なデータ構造を使用して、小さなサイズのArrayを複数使用することをお勧めします。
2.1 Global GC와とScavenger GC
IBM JVMでは、Minor GCとMajor GCという分類法はありません。
- Garbage Collectionステップ
代わりにGlobal GCとScavenger GCという分類法が存在します。
スループット最適化コレクタとレスポンスタイム最適化コレクタが実行するGCは、無条件のGlobal GCです。
つまり、Sun JVMの観点から見ると、常にMajor GCを実行しているわけです。
しかし、Compactionが起こるときだけ真の意味でMajor GCと同じだと言えます。
IBM JDK 1.5で追加されたGeneral Concurrent Collectorでは、Scavenger GCがMinor GCの役割を果たし、Global GCがMajor GCの役割を果たします。
Scavenger GCはMark and Sweep方式ではなくCopy方式(Alive ObjectをAllocate SpaceからSurvivor Spaceにコピーすることを意味)を使用し、Global GCではMark and Sweep + Compactionを使用します。
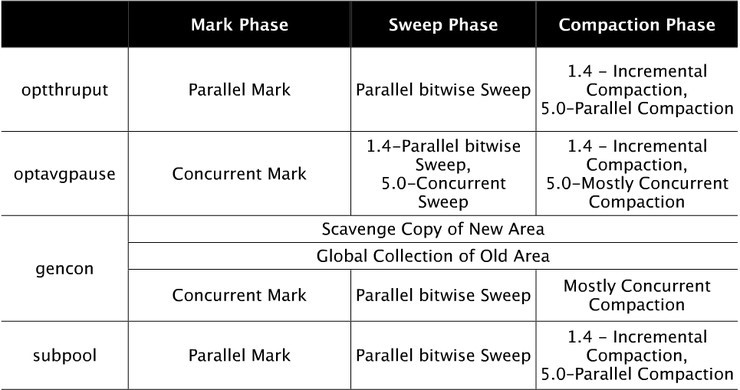
IBM JVMが提供する各Collectorの特徴を調べる前に、Mark、Sweep、Compactionのステップについて具体的に調べてみましょう。
3.1 Markステップ
Martkステップは、すべてのLive Objectに対してMarkを操作するためのステップで、参照係数(Reference count)が1以上のObjectはMarkとして、残りはGarbageと見なされます。
MarkされたLive Objectは、Markbit vectorにアドレスが格納されます。
Parallel Mark機能を使用でき、複数のスレッドがMarkステップを実行するために起動されます。 このように Parallel Mark を利用するには -Xgcthreads オプションを使用すれば良いです。
3.2 Sweepステップ
Markステップで、Live ObjectのアドレスストアであるMarkbit vectorとすべてのAllocation Objectのメイン小リポジトリであるAllocbit vectorと大小比較してLive ObjecとGarbage Objectを削除する作業を行います。
これにより、Parallel Bitwise Sweep機能を使用することができ、Parallel Markなどの複数のスレッドがSweepステップを実行するために起動できます。
これらのParallel sweep Threadの数は-Xgcthreadsオプションで設定できます。
3.2 Compaction ステップ
Sweep 段階で Garbage Object が削除された後、 Compaction 段階では Heap 上の削
除されたGarbage Objectのスペースに対して並べ替え操作を実行します。 このようなCompaction作業を行うことで、連続したFree Memory空間を確保することができます。 Compaction ジョブは Object が Heap Memory 上で移動が発生し、この場合すべての Reference の変更が発生することがあり、数行時間が長くかかります。
Compaction操作は、-Xnocompactgcが設定されておらず、次のような状況で発生する可能性があります。
Compaction ジョブが発生した場合
「-Xcompactgc」が設定されている場合
Sweepフェーズ後にObjectを割り当てるためのFree spaceが十分でない場合
-Xcompactexplicitgc オプションが設定された状況で System.gc() が呼び出された場合
少なくとも以前に利用可能なメモリの半分がTLH Allocationに使用され、平均THLサイズ
1024byteを下回る場合
利用可能なヒープが5%以下の場合
利用可能なヒープが128kb以下の場合
4. IBM JVM Collector
本格的にIBM JVMのCollectorについて取り上げましょう。
Throughputの最適化Collector(optthruput)は文字通りMark and Sweep + Compaction技術を使用します。 定期的にMark and Sweepが発生し、必要に応じてCompactionを介してMemoryをマージしようとします。
この一連のGCタスクはApplication Threadを完全に停止した状態で進行するため、GCタスク自体は最適化されています。
それだけスループットは高くなりますが、Pause Timeが長くなり、ApplicationのResponse Timeが長くなるという欠点があります。
Response Time Optimization Collector(optavgpause)は、Mark and Sweep + Compaction技術にいくつかの変更を加えます。
Mark and Sweepステップができるようになったら、Application Threadを停止しない状態でConcurrentに進みます。
つまり、Concurrent MarkステップとConcurrent Sweepステップを追加してMark and SweepによるPause Timeを最小化します。 Concurrent MarkとConcurrent SweepステップはApplication Threadのように動作し、それだけApplication ThreadのCPUリソースを消費します。
したがって、Throughput最適化コレクタと比較してThroughputが多少落ちる可能性があります。
Generational Concurrent Collector(gencon) は Hotspot JVM のように Heap を Generational Heap で分離して管理します。
これにより、Throughput最適化コレクタとレスポンスタイム最適化コレクタの両方の特徴が存在します。
後で詳しく見てみましょう。
Subpool Collector(subpool)は、16個以上のCPUを保有するSMP(Symmetric Multiprocessing) Machineに適しています。
この Collector は Collector として特定よりもHeap layout の効率性が強調されます。
4.1 IBM JVMの基本的なGC関連オプション
| オプション | 説明 |
| -Xgcpolicy:<optthruput | optavgpaus e | gencon | subpool> | Garbage Collectorを選択するオプションとして、Defaultはoptthru putです。 optavgpause は Response Time 最適化コレクタ、gencon は Generational Concurrent Collector、subpool は Subpool Collector を意味します. |
| -Xdisableexplicitgc | system.gc() を実行できないように無視するオプションです。. |
| -Xverbosegclog:<path to file><filena me>[X,Y] | GCログをファイルとして記録するオプションで、xはファイル数、yはGC回数を意味します。. |
| -verbose:gc | 画面にGC情報を出力 |
| -Xcompactexlicitgc | system.gc()を実行するたびにCompaction操作を実行します。 反対のオプションは-Xnocompactexplicitgcです。 |
| –Xcompactgc | すべてのGCでCompaction操作を実行します。 反対のオプションは-Xnocompactgcです。 |
| -Xclassgc | GC発生するたびにClass ObjectをCollection対象に含め、 オプションの使用はデフォルトで、逆のオプションは-Xnoclassgcです。 |
| -Xenableexcessivegc | GCの実行が長い場合、AllocationジョブにOOMEが発生させます。 OOME発生の必要条件は、最大ヒープサイズだけヒープが拡張され、さらに拡張でず、GCの実行時間が全体に対して95%を超える場合です。 Defaultオプション |
4.2 Throughput 最適化 Collector
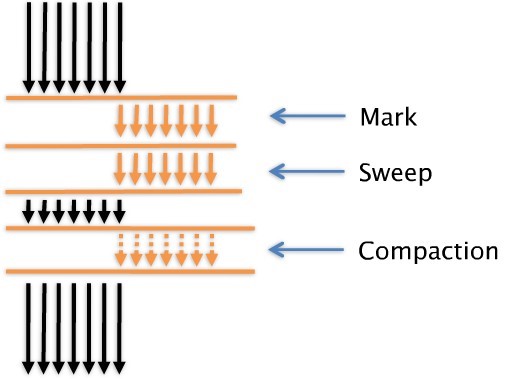
デフォルトでは、HeapへのObject割り当て操作が失敗するとGCが発生し、すべてのプロセスはParallelで、すべてのプロセスはSuspend状態でGCを実行します。
Compaction操作は、AFが発生したときにのみ実行されます。
MarkステップでGarbage Objectを区別し、SweepステップでMarkされたObjectをSweep後に割り当てに失敗したObjectに対して再割り当て試みます。
しかし、Free ChunkよりObjectがカーソルに割り当てられていない場合(断片化によるAF発生)、Object割り当てを保留した後にCompaction操作を続けます。 Markステップの後、Sweepステップは連続して実行されます。
これはすべてのIBM JVMのCollectorで同じです。 重要なのは、AF発生時にCompactionステップを実行することです。
4.2.1 Throughputの最適化Collectorのオプション
| オプション | 説明 |
| -Xgcthreads<value> | GC実行中にParallel操作に使用されるHelper Threadの数を指定します。 設定値より1少ない数でスレッド数が決まります。 Default は CPU 個数-1 最低値は 1、最大数は CPU 数でです。 値1の場合、Helper ThreadなしでMutator ThreadだけでGCを実行します。 |
| -Xgcworkpackets<value> | Work Packet 数の設定、Default は Heap size の最大数で演算を通じて適切な値を設定します。 |
4.3 Response Time 最適化 Collector
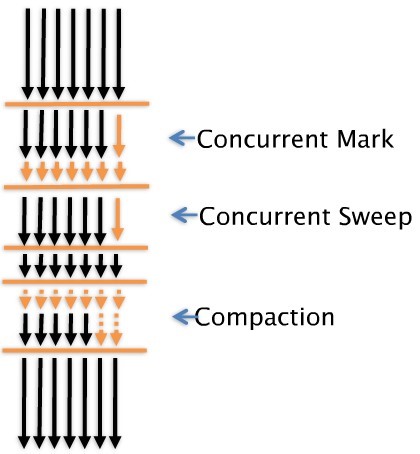
1つ以上のBackground ThreadがGCを実行します。
アプリケーションの実行中にConcurrent Mark、Concurrent Sweepを実行します。
Pause timeを減らすためにConcurrent Markを実行しますが、Stop-the-world Markも同様に実行します。
しかし、Concurrent中にGarbageになってしまうFloating Garbageの問題は残っています。 (Floating Garbageは次のGCから消えます。Floating Garbageの詳細については、第1四半期のHotspot JVM GCドキュメントを参照してください。) Thread全体がSuspendされる場合は、Stop-the-world MarkステップとAFが発生したとき、そしてsystem.gc()が呼び出されたときです。
4.3.1 Response Time 最適化 Collector のオプション
| オプション | 説明 |
| -XConcurrentbackground<val ue> | Concurrent Mark 段階で GC を実行する Background Thread (Coll ector Thread) 数の指定, Default 1 |
| -XConcurrentlevel<value> | Concurrent Mark 段階で Mark 時間を短縮するための Mutator Thre ad が Mark を担当する Object Allocation `tax` rate 指定 割り当てられた全体ヒープに対するMutator Threadが負担するヒープのサイズに対する割合を意味します。 Default 8% |
| -Xconmeter:<soa:loa:dynamic > | Concurrent Markステップ中にAllocation taxの対象となる領域を選択します。 Dynamicに設定すると、Garbage Collectorがsoaとloaのうち最初に枯渇する領域を動的に判別して指定します。 Defaultはsoaです。 |
- Generational Concurrent Collector
Generational Concurrent Collector を選択すると、既存の Heap 構造で以下のように
Generational Heap構造に変更されます。

Nursery Areaのうち、Allocation SpaceはObjectが割り当てられる空間ですが、この空間でAFが発生するとScavenge Copyが発生します。
Scavenge Copyは、Garbageの間でLive Objectを見つけて、Survivor SpaceにObjectを移動する作業を指します。 Scavenge Copy 時に時間が経過した Object があれば Tenured Area に昇格されます。
Hotspotのように、GCはNurseryとTenuredのそれぞれ別々に進行します。
Nursery では Scavenge Copy が短く繰り返し実行され、Tenured AreaGarbage Objectのみを選んで処理するGC方式が使用されます。
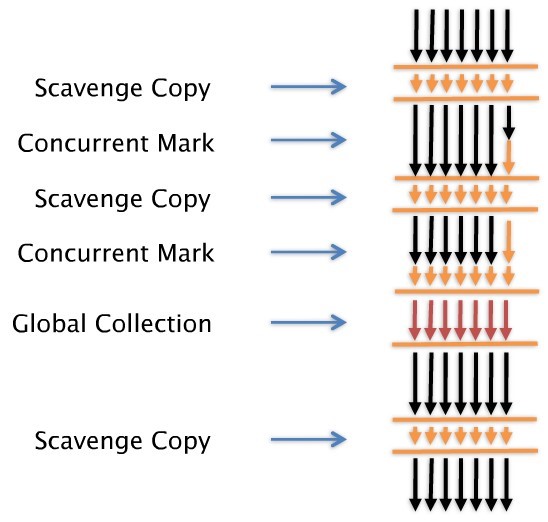
Scavenge Copy は Nursery Area の Heap Suspend 状態で非常に短く頻繁に実行され、Concurrent Mark は Response Time 最適化 Collector の Concurrent Mark 方式と同じです。
上の図は、Scavenge Copy完了後のある時点からConcurrent Markが行われるのに、その間に再びScavenge Copyが行われることを表しています。
しかし、Concurrent Markは完了しないので、ずっとMark作業を行います。 その後、Concurrent Markが完了すると、Global Collectionが実行されます。
Global Collectionは通常、Sweep操作のみを実行する場合、Compactionも実行されます。
Scavengeステップでは、Nurrsery領域のAllocate spaceとSurvivor spaceを用いてGCを行います。
その方法は、Allocate spaceがいっぱいになるとGCが発生し、Allocate spaceの
Garbageは削除され、Live ObjectはSurvivor spaceにコピーされます。 これらの手順を何度も実行すると、Live ObjectはTenured spaceに移動されます。
SunシリーズのMinor GCと非常によく似ていることがわかります。
しかし、Sunシリーズのオプションである-XX:MaxTenuringThresholdなどのオプションについては、技術文書にはありません。
JVMがLogicを処理している間、新しいObjectは当然Nursery領域に発生します。 新しいオブジェクトが割り当てられるのに必要な連続したメモリ領域が不足すると、オブジェクトはTenured領域に移動されます。
また、Garbage collection発生時に移されることもあります。 Nursery領域はAllocate SpaceとSurvivor Spaceに分けられます。 Object は最初 Allocate Space に発生することになります。 スペースが不足すると、Allocation Failureが発生した場合、Garbage Collectorが起動し、Scavengeが起動します。
Scavengeが進行中Reference が有効なObject は Survivor Space に移動され、このとき Reference がないオブジェクトは触れないです。
Reference が有効な Object の移動作業が終わるとAllocate SpaceとSurvivor Spaceはその役割を瞬間的に変えることになります。
この時の参照がないオブジェクトは瞬時に空になります。
そして次のScavengeが発生するまでは、Survivor SpaceがObjectのためのAllocate空間業務を実行することになります。
4.4.1 Nursery Area 의 Collection : Scavenge Copy Garbage Collection
AFが発生すると、すべてのスレッドは作業が停止します。 そしてAllocation AreaでLive Objectを見つけて、これをSurvivor Areaに複製します。 そして、Scavenge Copyの時に14 AgingされるObjectはTenured Areaに昇格します。(ちなみにHotspotはAge最大値が31、IBMは14である。) Agingは一度のScavenge Copyで生き残る度に1ずつ増加します。 以後Allocation Spaceより
Survivor Spaceになり、Survivor SpaceはAllocation Spaceになります。(Flipと表現します。)

もっと詳しく見ると、Nursery Areaの割り当て作業の最適化のために内部的にTilting技術が適用されます。
Tilting技術とは、Scavenge Copyを介して移動するReachable Objectの量でSurvivor、Allocation Areaのサイズが自動的に決定される技術を言います。
最初はAllocation AreaとSurvivor Areaのような大きさだが、Scavenge Copy以降Survivor Objectの量が足りないことを認識した後、比率が80%に増加した様子を確認することができます。
4.4.2 Tenured Area の Collection : Concurrent Mark と Global Collection
Tenured AreaにGCが発生すると、Concurrent Mark操作が実行されます。
この時はPause Time CollectorのようにConcurrent Mark、Stop-the-world Mark段階に進みます。 アプリケーションを実行しながらBackgroundでMarking操作を実行し、完了したら
Generational Concurrent Collectorは、すべてのApplication操作を停止し、Remark、Sweep操作を実行します。
その後、Global Collectionを実行するのは通常Sweepだけですが、場合によってはCompactionタスクも実行します。
Sweep ジョブは Pause time Collector のように Concurrent Sweep ではなく Parallel bitwise Sweep 方式を使用します。
4.4.3 Generational Concurrent Collector のオプション
| オプション | 説明 |
| -Xmn<size> | Nursery領域絶対サイズを意味し、対応するオプションを設定すると、最初のサイズと最大サイズが等しくなります。 |
| -Xmns<size> | Nursery領域の最初のサイズで必要ならば-Xmnxまで拡張、Default値はシステム性能によって設定されます。 |
| -Xmnx<size> | Nursery領域を拡張する最大サイズ設定オプションで、Default値はシステム性能に応じて設定されます。 |
| -Xmo<size> | Tenured領域の絶対サイズ指定オプションで指定すると、最初のサイズ、最大サイズが設定値に等しくなります。 ちなみに、-Xmos、-Xmoxオプションのように使用することはできません。 |
| -Xmos<size> | Tenured領域の最初のサイズ設定オプションで、必要に応じて-Xmoxまで拡張可能です。 デフォルトはシステムによって異なります。 |
| -Xmox<size> | Tenured領域を拡張する最大サイズを意味し、DefaultはSystemによって異なります。 |
| -Xmoi<size> | Heapが拡張されるサイズ設定オプションで0の場合、拡張しないことを意味します。 Default は -Xmine, -Xminf 演算で決定されます。 |
| -Xmr<size> | Remember set サイズ設定オプションです。 (Remember set は Nursery 領域の Object を参照している Tenured Area の Object のリストで、Mark フェーズで時間を節約するデバイスとして Default 16kBytes) |
- Generational Concurrent Collectorの長所と短所とオプションを適用する際の注意事項
Generational Concurrent Collectorの利点は、アプリケーションの全体的な応答速度(Response Time)が向上する効果をもたらすことができます。
欠点は、ConcurrentしたThread起動によって実際のApplication実行におけるThroughputが減少することです。 また、デフォルトのCollectorよりもCPU使用率が多少高い場合があります。
Generational Concurrent Collector は前述したように Java 1.5 以降から適用が可能です。
そして何よりNurseryの2つの領域のうちの1つは常に空になっているので、OOMEが頻繁なJVMであれば、JVMメモリサイズをもう少し大きく設定する必要があります。
4.5Sub Pool Collector
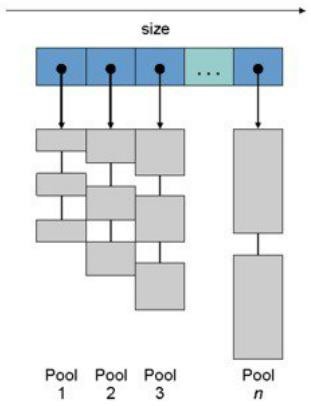
16以上のCPUを搭載したSMP(Symmetric Multiprocessing)マシンに適しています。 この
Collector は Collector として特定より Heap layout 自己効率性が浮き彫りになっています。
Sub Pool は保存される Object size を基準に Free List をそれぞれ構成し、同様のサイズの Free Chunk の Pool で Heap を編成します。
そのため、Allocation の過程で Heap ロックが分散され、割り当てがより速いのです。 また、同様のサイズのObjectが作成、削除されるため、Large ObjectによるAF現象も減るようになります。
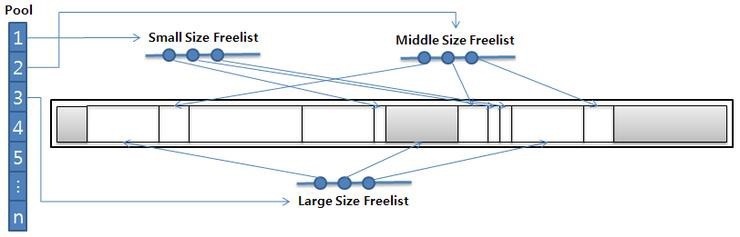
Heap自体はOne Heapに固執するが、Poolという資料構造を活用してFree Listが複数個生成されます。 Pool は、Free Chunk のサイズに応じて構成された Free List を昇順で指します。
Free ListはOne HeapでFree Chunkのアドレスを保持します。
GCはOptimize for throughput Collectorと同じ方法を使用します。
つまり、MarkステージではParallel Mark、SweepステージではParallel bitwise Sweep、CompactionステップではParallel Compactionを使用します。
Sub Pool Collector を選択しても、JVM 起動直後から最初から Free List が分離された Sub Pool 構造が作られるわけではありません。
1つのFree Listでタスクを実行し、最初のGCが実行されてSweepステップが完了すると、Sub Poolの機能が表示され始めます。
Compaction操作が実行されるとSub Pool構造が解体され、1つのFree Listに回帰し、Sweepステップが実行されると、再びFree Chunkのサイズ別Free Listが生成されます。
Sub PoolがSweepステップで再構成される理由は、Sweepステップの結果がFree Chunkをターゲットに作成されたFree Listであるためです。
Compaction段階では、Free Chunkが解体され、Free Listをサイズ別に並べ替えるよりも、最初から始める方が性能上有利だと言います。
- Sub Pool Collectorのオプション
| オプション | 説明 |
| -Xtlhs<size> | SubPoolを使用するときにTLH(トレッドローカルヒープ)最小サイズを設定、512バイト~ 8kBytes Default サイズは 768Bytes、値を入力すると基本的に Byte 単位であり、Kbyte 単位は k を付けなければならない。 |
4.5.1 SMPとは
複数のプロセッサが1つの共有メモリを使用するマルチプロセッサコンピュータアーキテクチャであり、現在使用されているほとんどのマルチプロセッサシステムはSMPアーキテクチャに従います。
今後のSMPは、NUMA(Non-Uniform Memory Access)技術に発展します。
IBM JVM環境で発生する可能性があるメモリーリークの一般的なタイプ
まず、GCのアルゴリズムをもう一度思い出してみましょう。
GC が Trigging されると、Garbage Collector は Heap 空間全体を Scan して現在「使用中」または「生きている」オブジェクトを表示 (Mark) します。
これらはReachable Objectsと呼ばれ、逆に使用済みまたはReferenceが壊れたオブジェクトをUnreachable Objectsと表現します。
もちろん、それらはGCによって収集される対象です。 ここで、Reachable Objectsのうち以下の場合を考えてみましょう。
A というオブジェクトが B というオブジェクトを呼び出したり生成して Reference を作成します。
その後、Aオブジェクトは何もしなくてもUnreachable ObjectsではなくReachable Objectsに分類されるという点です。
この観点から、一般的なメモリリーク要素になることができる事項は次のとおりです。
・ハッシュテーブルに格納されているオブジェクトは、明示的に削除されない限り、GCの対象にはならないです。
Hashed Object は常に Reachable Objects に分類されるからです。
・Static Class Dataは通常のオブジェクトとは無関係に存在します。 より詳細に説明すると、Static ClassとStatic VariableはPermanent Areaに存在します。
・ JNI Reference は使用後に明示的に削除しなければなりません。
lFinalize Methodを持つオブジェクトは、Finalizer Threadが起動したときにのみGCされます。 しかし、Finalizer Threadはいつ実行されるかもしれず、一度も実行されないかもしれないという特徴があります。
したがって、特別な場合でなければ、Objectクラスが持つFinalize Methodをオーバーライドして使用しないようにします。
6. 結論
IBM JVM GCの利点について考えてみましょう。
スループット最適化コレクタ、レスポンスタイム最適化コレクタの利点は安定したGCパターンです。 Hotspot JVMが提供するGeneration技術がはるかにインテリジェントで効果的であることは否定できない事実です。
特にチューニングでMajor GCを最小化し、Minor GCを最適化すれば、GCによる性能低下現象をほとんど避けることができます。
しかし、Major GCによるSpike現象(突然GC Pause Timeが急増する現象)は、常に高質な問題として残っています。
Minor GC時には安定したパターンを示していても、Major GCが発生したときに数秒から数十秒までGC Pauseが発生した場合、性能への影響は致命的になることがあります.
一方、IBM JVMでは比較的コンパクションの発生頻度が高くないため、全体的に安定したパターンを見せます。
この言葉は逆説的にIBM JVMでCompactionが最適化され、Sun JVMでMajor GCが最適化されれば、両者の間に大きな性能差がないことを示唆することもあります。
IBM JVM GCの欠点は次のとおりです。
Sun JVM が New/Old Generation のサイズ、Survivor Ratio などの調整により細かいチューニングが可能ですが、IBM JVM の Throughput 最適化 Collector や Response Time 最適化 Collector を使用する場合には、チューニングでの細かさが不足した方がJDK 1.5 で提供する Generational Concurrent Collector を使う場合には Sun JVM とほぼ同様の設定が可能です。 しかし、チューニング可能なオプションの数は比較的小さい方です。
しかし、逆説的にチューニングオプションが少ないということは、より自動化されて便利だという意味でもあります。
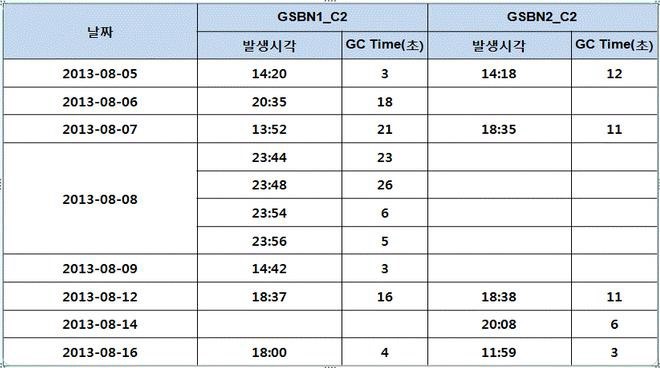
上記の表は、GC Optionを使用していないオペレーティング環境で(Throughput Optimization Collectorを使用)2週間に3秒以上行われたGCの実行履歴を抽出した結果です。
上記のデータからわかるように、Throughput Optimization Collectorを使用している環境では、GC Timeが途方もなく長いSpike現象が発生することがよくあります。
これは、GC中に発生したCompaction操作が原因です。
このような現象は、リアルタイムで継続的にサービスにならなければならない環境(例えば、MES)で障害と見ても構いません。
GC Time Spike現象を解消するためにGeneral Concurrent Collectorを使用するようにJavaオプションを変更し、2週間のGC推移を見守りました。
その結果、驚くべきことに、すべてのGC時間が1秒以下で行われています。
Scavenger GCによってGCの実行自体はより多く発生しましたが、GC Time Spike現象がなかったため、サービスに支障をきたす状況は発生しなかったです。
最近IBMでリリースされたWebsphere V8の場合、DefaultとしてGeneral Concurrent Collectorを使用するようになっています。
これはWebsphere V8のマニュアルでも確認できます。
結局、IBMはHotspot JVMでDefaultとして使用するGeneral Heap構造の効率を認めたと解釈されます。
付録 1 : JVM Memory Sizing
Heap base から Heap limit まで利用可能なサイズが足りないと判断された場合、最大 Heap top まで Heapを拡張し、逆にFree Heapが多い場合は縮小します。
拡張する場合
- GCを実行してもAllocationの要件を満たしていない場合
- Free Space が全下限線(-Xmaxf)より低い場合
•下限まで拡張、ただし最大ヒープ拡張サイズ(-Xmaxe)を超えない、超えれば-Xmaxeだけ拡張(extend)
•下限が1MBytes(-Xmine)より小さい場合は、1MBytesまで拡張、つまり最小、最大extend値があります。
3) GC時間がしきい値(-Xmaxt)を超えた場合
縮小する場合
1) Free Spaceが下限線(-Xmaxf)よりもあふれる場合、縮小量は下限線までする。 ダン –
Xms(Heap最小サイズ)より大きくなければならない。
ただし、以下の場合は縮小しない。
• GCが終了しましたが、Objectが割り当てるサイズを取得できない場合
• Free Spaceの下限を100%に設定した場合
• system.GC() 実行時 Free Space の量が下限線下回るとき
• 最近3回のGCを実行した後にヒープが拡張されたことがある場合
(拡張サイズ、縮小サイズは32bitメモリで512Bytes単位、64bitでは1024Bytes単位に増えます)
付録 2: IBM JVM の Heap size 関連オプション
| オプション | 説明 |
| -Xmx<value> | 最大ヒープサイズ、明示的に設定しないと自動設定 |
| -Xms<value> | 初期ヒープサイズ、最小サイズ、設定しないと自動設定 |
| -Xmaxf<value> | 0~1の間、パーセンテージとして認識、Default 0.6、空きスペースが60%超過するとHeap削減、GC以降のフリースペース上限 |
| -Xminf<value> | 0~1、パーセント、Default は 0.3、GC 以降 Free Space 下限ライン |
| -Xloa | LOA (Large Object Area) を割り当て、Large Object は LOA に割り当てられます |
| -Xloainitial<value> | LOA の初期サイズ、0~0.95、パーセント、Default 0.05、全体 Heap 対比 5%の空間を意味 |
| -Xloamaximun<value> | LOA の最大サイズ、0~0.95、パーセント、Default 0.5、全体ヒープに対して50%の空間を意味 |
| -Xmaxe<value> | Garbage Collector が Heap を拡張する最大サイズ設定、10M に設定すると拡張するとき 10M 以上にならないということ、Default 0 |
| -Xmine<value> | Garbage Collector が Heap を拡張する最小サイズ、Default 1MBytes |
| -Xp<initial>,<overflow> | P Cluster のサイズ調整オプション、初期値と、初期値が使い果たされたときに追加されるサイズ、2 番目はオプション、Default 2kBytes |



