

2022.12.02
Runtime Data Areas
Runtime Data Areas
(株)エクセムコンサルティング本部/APMチームイム・デホ
Runtime Data Area構造
Runtime Data Areaは、JVMがプログラムを実行するために割り当てられるメモリ領域と呼ばれることがあります。
実際のWASパフォーマンス問題に直面したとき、ほとんどの問題点はRuntime Data Areaで発生することが多くあります。
Memory LeakやGarbage Collectionの場合がその例です。
これらのパフォーマンスの問題が発生した場合、この問題がなぜ発生したのか、どこで発生したのかを確認するのは簡単ではないのです。
そのような場合、Runtime Data Areaのアーキテクチャを学習することは問題を分析するのに大きな助けになります。
Runtime Data Areaは大きく5つの領域に分けられます。
それはPC Register、Java Virtual Machine Stacks、Native Method Stacks、Method Area、Heapです。
各 Thread 別に生じる領域は PC Register、Java Virtual Machine Stacks、Native Method Stacks であり、すべての Thread が共有する領域は Method Area と Heap です。

PC Register
JavaのPC Registerは、CPU内の記憶装置であるレジスタとは異なる動作をします。 Register-BaseではなくStack-Baseで動作します。
PC Register は各 Thread ごとに 1 つずつ存在し、現在実行中の Java Virtual Machine Instruction のアドレスを持つようになります。
Native Methodを実行すると、PC RegisterはUndefined状態になります。
このPC Registerに格納されているInstructionのアドレスはNative Pointerでも、Method Bytecodeでもよいです。
Native Methodを実行するときは、JVMを介さずにAPIを介してすぐに実行されます。
これは、JavaがPlatformに依存しないことを示しています。
Java Virtual Machine Stacks
Java virtual Machine Stacks は Thread の実行情報を Frame を通じて保存することになります。
Java Virtual Machine Stacks は Thread の起動時に生成され、各 Thread ごとに生成されるため、他の Thread にはアクセスできないです。
代表的に Local variable を持ちます。
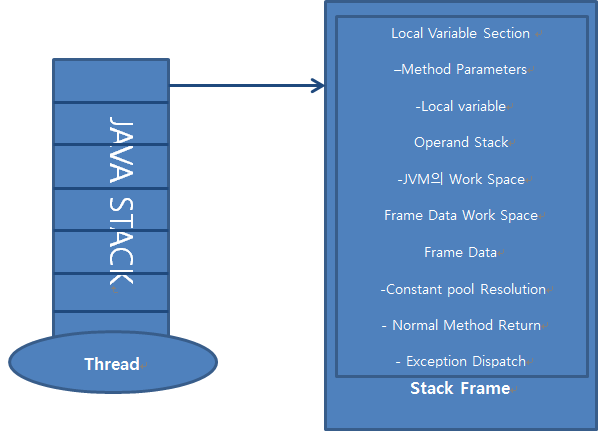
Java Virtual Machine Stacks で現在実行している Frame のCurrent Frame です。
Stack Frame には Method の Parameter variable, Local variable と演算結果を格納することになります。
Stack Frame
Stack Frame は Thread が実行しているメソッド単位を記録する場所です。
Method の状態情報を保存する Stack Frame は大きく 3 つの領域に分けられます。
それはLocal Variable Section、Operand Stack、Frame Dataです。
Stack Frame のサイズはコンパイル時に決定されます。
Local Variable Section
Local Variable Sectionは、MethodのParameter ValueとLocal Variableを格納します。
Variable Section は 0 から始まる array 型インデックスを持つが、parameter value から割り当てられます。
Local Variable は順序が決まっていません。
また、使用されていない場合は割り当てられない可能性があります。
Parameter ValueとLocal VariableがPrimitive Typeの場合(ex int型)は固定サイズに割り当てられます。
しかし String や Array のようなオブジェクトは可変サイズなので Reference を持ちます。
Java source
class Test {
public int testMethod (int a, char b, long c, float d, object e, double f, String g, byte h, short I, Boolean j) {return 0; }

testMethodには10個のパラメータ変数があります。
Local Variable Section では図 6 のように割り当てられます。
ここで注目すべきことは、long型とdouble型の場合はarrayを2つずつ使用するということです。
char、byte、short、boolean 型で宣言したのは、Local Variable Section にはすべて int 型で割り当てられるということです。
変数を宣言する場合、Inteager型とint型のどちらがパフォーマンスに優れていますか?
int型がパフォーマンスに優れている理由は、int型はJava Virtual Machine Stackに格納されていますが、Inteager型はHeapに格納されるため(参照)
0 番 Entry の hidden this は宣言したことのない変数であるにもかかわらず、0 番 Entry に格納されています。
Hidden this は Heap の Class の Instance に対する reference です。
Operand Stack
Operand StackはJVMのワークスペースです。
その理由は、JVMが演算に必要なデータとの演算結果をOperand Stackに入れて処理するからです。
動作方式は 1 つの Instruction が演算のために Operand Stack に値を入れると次の Instruction ではこの値を引いて使用することになります。
演算の結果もOperand Stackに保存されます。
Operand StackもArrayで構成されており、Stackの構造でPush、Pop作業を行います。
Frame Data
Stack Frame を構成している領域です。
ここでは、Constant Pool ResolutionについてMethod が正常終了したときの情報または異常終了をしたときに発生する Exception 情報を格納しています。
Resolutionとは、Symbolic ReferenceをJVMから実際にアクセスできるDirect Referenceに変更することをいいます。
Symbolic Reference は Method Area の Constant Pool に保存されます。
Frame Dataに保存されているConstant Pool Resolutionは、Method AreaのConstant PoolのPointerです。
JVMは必要に応じてPointerでConstant Poolにアクセスします。
通常、定数だけでなく他のクラスを参照するか、メソッドにアクセスする場合でもConstant Poolを参照する必要があります。
これはJavaのすべてのReferenceとSymbolic Referenceであることに関連しています。
Method が実行され、終了する時点で Java Virtual Machine Stack で該当 Stack Frame が Pop されて消えます。
この時点で以前にメソッドを探す必要がありますが、Frame Dataには以前に自分を呼び出したStack FrameのInstruction Pointerが含まれています。
Method が exception を発生させた場合、その exception をハンドリングしてくれなければならないのですが、exception情報がFrame Dataに保存されます。
Native Method Stacks
JVM は Native Method のために Native Method Stack というメモリ空間を持ちます。 Application で Native Method を呼び出すと、Native Method Stack に新しい Stack Frame を生成して Push します。
これはJNIを使用してJVM内部に影響を与えないためです。
Native Method の実行が終わったら、その Method を呼び出した Stack Frame ではなく、新しい Stack Frame を 1 つ作成してタスクを実行します。
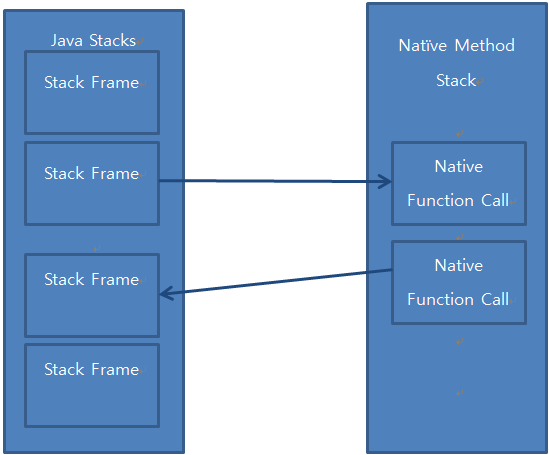
私たちがよく使うHotspot JVMやIBM JVMでは、2つのStackゾーンを区別しません。
すべてNative Stackで統合されていますが、これはJVMで使用するThreadがNative Threadであることと関係が深いのです。
Hotspot JVMでStack Sizeを調整するオプションは-Xssと-Xossの2つです。
-XssはNative Stack Sizeを調整するオプション、-XossはStack Sizeを調整するオプションです。 Hotspot JVMでは、Stack Sizeの調整は-Xssだけで行われます。
Method Area
Method Area はすべての Thread が共有するメモリ領域です。
Method Area は Class と Interface の Bytecode およびメタデータが格納されます。
これはGabage Collectionの対象となり、Hotspot JVMの場合はPermenent Areaという名前で使用されます。
IBM JVMなどの場合は、Heap内にClass Objectの形式で格納されます。
Constant Pool
Constant Poolは、JVMで最も重要な役割を果たす場所であり、よく使われる場所でもあります。 Constant Pool には Literal Constant はもちろん Filed(Member Variable, Class Variable), Method へのすべての Symbolic Reference まで持ちます。
Symbolic Referenceの役割を果たしているのがConstant Poolです。
Field Information
Field Information にはすべての Field の情報があります。
- フィールド名
- フィールドのデータ型、宣言順
- public, private のような Field の Modifier
Method Information
メソッド情報にはすべてのメソッド情報があります。
- メソッド名、メソッド戻り値のData Typeとvoid
- Method parameter の数と Data Type、宣言順、Method の Modifier
Method が native や abstract でない場合、次の情報が追加されます。
- Method の Bytecode
- Method Stack Frame の Operand Stack および Local Variable Section のサイズ
- Exception Table
Class Variable
Class Variable は static として宣言した変数であり、Method Area に格納されます。
この変数はすべてのインスタンスでアクセス可能であるため、同期問題が発生する可能性があります。
Class Variableをfinalとして宣言すると、これはConstant PoolにLiteral Constantとして保存されます。
Method Table
Method Area に格納される情報は Heap に Object を生成する際に使用されることもありますが、Reference のための Data としての役割も重要です。
Javaでは、Referenceでオブジェクトを探索することは速度の点で非常に重要です。
Method Table は Class の Method に対する Direct Reference を持つと見ればいいです。
Method Table を利用して Super Class から継承された Method の Reference まで確認が可能です。
Java Heap
Java Heapで多くのパフォーマンス問題が発生しています。
Gabage Collectionによるのが代表的なものです。
Java Heapは、InstanceとArrayオブジェクトの2種類が格納される空間です。
Java HeapはすべてのThreadによって共有されると述べましたが、それによって同期の問題が発生する可能性があります。 Java Heap は Gabage Collection とは Mechanism によってメモリ解放作業は必要ないです。
実際に多く使用しているHotspot JVMとIBM JVMのObjectの構造を見てみましょう。
Object構造
Heap に格納される Object と Array オブジェクトは Head と Data に分けられます。
Hotspot Object構造
Hotspot JVMのObjectの場合は2つのHeaderを持ち、Arrayオブジェクトの場合は3つ
Header を持ちます。
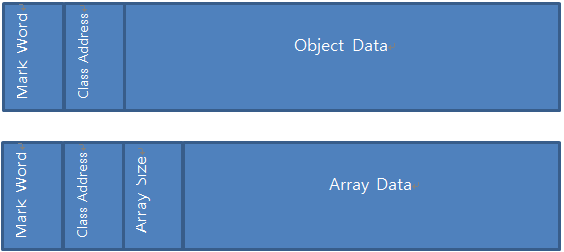
First header は Mark Word と呼ばれ、Gabage Collection と Syncronization 作業に使用します。
2番目のHeaderには、Method AreaのClass情報を指すReference情報が格納されます。 Arrayの場合、3番目のHeaderが存在しますが、Array Size情報を持つためのスペースがあります。
IBM Object構造
IBM JVMはJava 5のケースを見てみましょう。
Object の場合 2 つの Header を持ち Array の場合 Array Size 情報を含んでいる Header を含めて合計 3 つの Header を持つことになります。

VtableにはObject Information用のVtable Pointerがあり、これは主にGarbage Collectorによって使用されます。
2番目のヘッダーは、ロックワードを使用してオブジェクトのロック取得の有無を確認するために使用されます。
Heapの構造
Hotspot JVM Heap構造
Hotspot Heapの最大の特徴は、Young GenerationとOld Generationに分かれているということです。
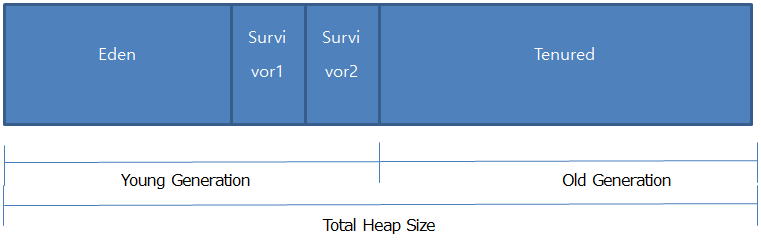
Young Generation は Eden と Survivor 領域で構成され、最初の Heap にオブジェクトが割り当てられます。
その後、Object参照かどうかを確認し、参照されている状態であればSurvivor領域に渡し、長く生き残ったらOld領域に移動させられます。
これをPromotionと言います。 ちなみに Young Generation で起こる GC を Minor GC といい、Old Generation で起きる GC を Major GC といいます。
IBM JVM Heap構造
IBM JVM Heapはバージョンによって異なる姿を見せていいます。 まず、IBM JVM 1.4を見てみましょう。
そうです。 1.4バージョンの代表的な特徴はOne-Heapという点です。
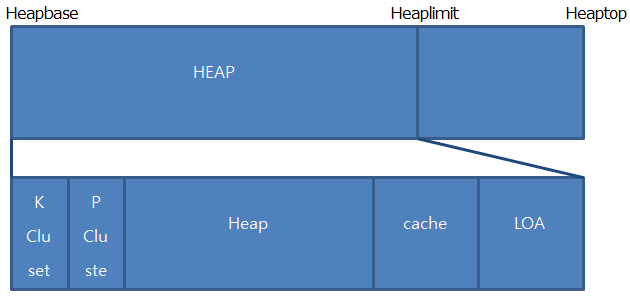
K ClusterとP Clusterは、Hotspot JVMのPermanent Areaと同じ役割を果たしていると見てください。
K ClusterがMethod Areaの情報を持っているClass Objectを格納する空間であるのに対し、P ClusterはPinned状態のArrayや一般Ojbectを保存します。
Cache領域は、ThreadごとにLockなしで割り当てられるスペースです。
LOAはLarge Objectのためのスペースです。
このヒープはGarbage Collectionとオブジェクトに素早く割り当てるためにAllocbitsとMarkbitsというBit VectorとFreelistを持っています。
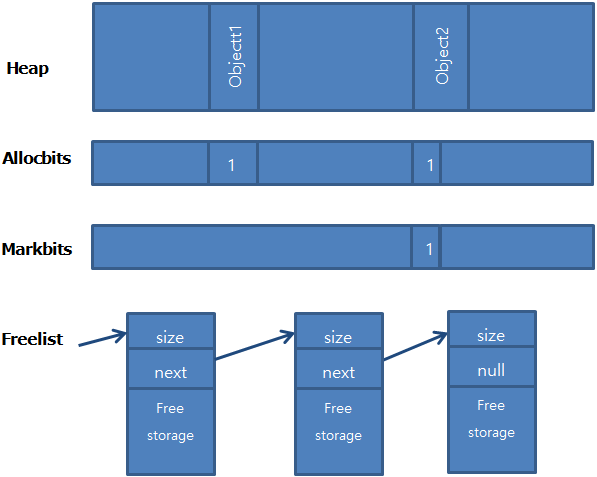
Allocbits は Object の始点にのBit が On になります。 Allocbitsは単に割り当てられたかどうかを知ることができ、Garbage Collectionの対象であるかどうかは判断できません。
ObjectのLiveはMarkbitsを通して知ることができます。
Cache Alloction を使用して Thread が Object を割り当てる場合は、Thread に割り当てられた Heap(TLH) をすべて使用した後でも Allocbits に On と表示されます。 そしてGarbage CollectionによってFree spaceになると再びOffになります。
Freelist は Object のために Heap 空間を割り当てるためのデータ構造として見ればよいです。
このFreelistはlinked List構造になっており、最後のChunkのNext FiledはNullです。
Object に Heap を割り当てるために Freelist を探索し、正しい Chunk がない場合は、次の Free Chunk が見つかるまで Jump を繰り返します。
この時使用して残ったChunkもFreelistとして登録され、もしChunkのSizeが512 Byte未満であればこれはCompactionの対象となります。
このように小さなFree ChunkをDark Matterと言います。
1.4バージョンからサブプールを提供していますが、これは、Freelistをサイズ別にさまざまに提供する利点があります。
既存の方法がFirst Fitだった場合、sub pool方式はBest Fitを追求します。
IBM JAVA 5 Heap構造
JAVA 5では、以前のバージョンとは異なり、2つの変更があります。 1つはSystem Heapを含みません
もう一つはHotspot JVMのようにGeneration Heapを使用できるということです。
ただし、オプションを適用する場合にのみ使用可能です。 オプションは次のとおりです。
-Xgcpolicy:gencon
Hotspot JVMでは、Young GenerationはNursery Generation、Old Generationは
Tenured Generation です
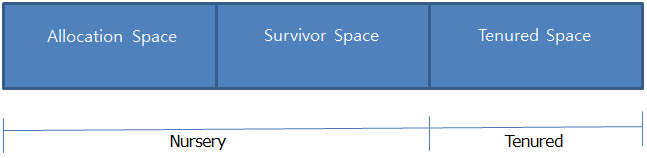
Nursery Area は Allocation Space と Survivor Space に分けられます。
Allocation Space は Object が最初に割り当てられる場所であり、Survivor Space は Allocation Space がいっぱいになったり Allocation Failure が発生すると移動される場所です。
Tenured Space は Nersery Generation の成熟した Object が Promotion するところです。
結論
Runtime Data Areas はオブジェクトの生成と消滅が繰り返される場所です。
そのため、性能問題が頻繁に発生する場所でもあります。
今までRuntime Data Areasについて学びましたが、これはパフォーマンス分析の基礎になると思います。
前述のように、参照のためにJava Stack、Method Area、Heapのすべての部分にJump操作を実行することがわかります。
不要なReferenceの乱発は性能を落とす結果を生み出します。
また、不必要にMethodのDepthも深くなり、Java StackではStack Frameをより多く生成しなければならず、それに応じてプッシュ、ポップ作業が頻繁になります。
このようにStack Frameが多くなることも、すべてResourceの無駄につながるようになります。
オブジェクトとPrimitive Typeの違いは良い例です。
今後、Runtime Data Areasの知識をもとに勉強していけば、WAS性能の専門家の道もそれほど遠くはないでしょう。


