

2023.07.04
Chapter 3. 機械学習
機会学習の定義と活用
Q:機械学習とは何ですか?
機械学習(Machine Learning)とは、人工知能の一部です。
入力されたデータから、コンピュータが学習するようにプログラムすることを指します。
この章ではまず、機械学習を分類する4つの方法のうち、2つについて説明していきます。
【 機械学習を分類する最初の方法 】
機械学習は「 地図学習、非地図学習、準地図学習、強化学習 」の4つに分類されます。
※ 今回は[地図学習]と[非地図学習]について解説していきます。
地図学習 とは
地図学習(Supervised Learning)とは、トレーニングデータにラベル(正解)がある学習方法である。
| 地図学習として代表的なもの |
| K-nearest neighbors(K-近接近隣) Linear regression(線形回帰) Logistic regression(ロジスティック回帰)、 Support vector machine(SVM、サポートベクターマシン) Decision tree(決定木) Random forest(ランダムフォレスト) Neural networks(ニューラルネットワーク) など |
下の図を例として挙げましょう。
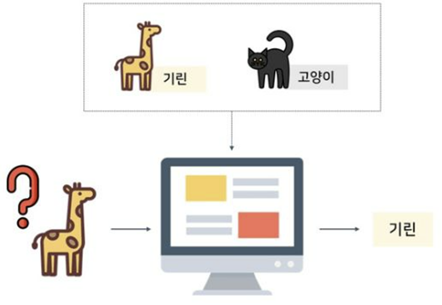
地図学習 [ソース] : http://itnovice1.blogspot.com/2019/05/ai-gan.html
キリン(正解)と猫(正解)の画像をよく学習したアルゴリズムは、キリン画像を見たときにはキリンと判断し
猫の画像を見たときには猫と正確に判断することができます。
非指導学習 とは
トレーニングデータにラベル(正解)がない学習方法で、大きく群集、次元縮小などがある。
その中でもクラスタリングは、非指導学習において広く使用されているアルゴリズムの1つです。
上記の例とは異なり、キリンと猫がラベル付けされていないデータから、非地図学習アルゴリズムはキリンまたは
猫の特性を抽出して分類します。
例えば、キリンの黄色、汚れ、首部分の長い特性を持っているアルゴリズムである場合、これが「キリン」であるかどうか?
は判別できないため、「黄色く汚れがあり、首が長い動物」として分類されます。
同じ概念で、非指導学習をしたアルゴリズムでも「猫」なのかはどうか?までは判別できないため、「尾が長く耳が尖った動物」
として分類されることになります。
これに関連して、次元縮小、主成分分析(Principal Component Analysis、PCA)、カーネルPCAなどがあります。
下の図を例として挙げましょう。
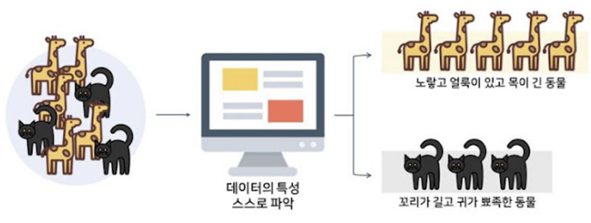
非地図学習 [ソース] : http://itnovice1.blogspot.com/2019/05/ai-gan.html
特定のアルゴリズムでは、一部だけがラベル付けされているデータも扱うことができます。
このような学習方法のことを「指導学習」といい、非指導学習のうち群集として使われる場合がある。
例えば、無数の動物の中で、ウサギとカメだけがラベル付けされたとしましょう。
その場合、アルゴリズムがウサギとカメが、動物園Aと動物園Bのどこに展示されているか?を自動的に認識します。
強化学習とは、あるエージェント(学習するシステム)が、環境(Environment)を観察し、行動(Action)を
実行し、その結果として報酬(Reward)を受けることである。
ここでの報酬は、肯定/否定的な形であり、否定的な報酬は罰点(Penalty)として表現されます。
この点においては、2017年5月にあった囲碁ロボット [アルファゴ] と人間の対決が代表的な例として挙げられます。
アルファゴは、世界チャンピオン(人間)と対決するまでに、事前に数多くの学習をして対決に挑んだ結果、人間にロボットが
勝利することになりました。
機械学習を別の方法で分類すると、オフライン学習 と オンライン学習 に分類できる
オフライン学習は、バッチ学習とも呼ばれています。
この学習方法を適用したシステムは、手順を踏んで順番に学習することができません。
学習が可能なデータを1度すべて学習した後、それを適用する形です。又、適用後はそれ以上の学習は行いません。
学習データが増えた場合には、適用されているデータ全体を再度すべて更新後、システムに変更を加えることができます。
例えば、時系列データからは毎分、あるいは毎日新しいデータが入るような場合には、バッチ学習は適していません。
また、データ量に応じて、CPU、メモリ、ディスク容量などの多くのコンピュータリソースが必要となる点が欠点です。
しかしそれとは対照的に、オンライン学習では、ミニバッチと呼ばれる小さなバンドル単位でデータを注入することができ
システムは、注入されてくるデータを順番に学習していきます。
データ量は1つからで、ミニバッチのサイズに応じてシステムに注入する形です。
この方法を使う場合、学習フェーズを素早くすることができるメリットがあります。
前述のバッチ学習とは異なり、少ないコンピュータリソースで学習ができるのも大きなメリットです。
そんなオンライン学習における重要なパラメータの1つに 「学習率」 が挙げられます。
- 学習率とは?
学習率はデータに適応する速度を定める指標である。
学習率が高いほど速く適応することができるが、以前のデータをすぐに忘れてしまう。
例えば、学習率が高い地図学習で、最近登録されたボイスフィッシング電話番号だけをフィルタリングする場合には、
学習率を下げる必要があります。
オンライン学習では、着信データを監視することが重要です。
監視中にアルゴリズムのパフォーマンスが低下した場合、悪いデータが注入されていることを意味します。
この場合には、すぐに学習を中止する必要があります。
ここで言う悪いデータは、理想値であると説明することができ、異常値検出アルゴリズムを使用してフィルタリングが可能です。
オフライン/オンライン学習に分類する方法に続いて、機械学習がどのように一般化されるか?という観点でも分類ができます。
一般化する学習法には、ケースベースの学習とモデルベースの学習がある。
ケースベースの学習(Instance-based learning)には、代表的にK-近接近隣(K-nearest neighbors)回帰方法がある。
K-近接近隣技術では、ユークリッド距離技術またはバイナリ属性で類似度指標を説明できます。
例えば、ある企業の株価予測をするために財務比率評価をするとしましょう。
この時、財務比率のうち株価純資産比率(PBR)、売上高純利益率(ROS)、株価補償率(PER)を反映させた後、
これら3つのデータを3次元の空間上に投影すると、正解を導き出すことができます。
これをユークリッド距離技法と呼びます。
もう1つ別の方法としては、バイナリデータを使用して類似度指標の精度を向上させることです。
データの特性が0、1、またはYES、NOで表現できる場合、予測性能を評価することができます。
モデルベースの学習(Model-based learning)では、アルゴリズムのモデルを作成して、予測(Prediction)を通して
一般化します。モデルの効用関数(Utility function)やコスト関数(Cost function)で性能を評価していきたいと思います。
- 効用関数(Utility function)とは?
適合度関数(Fitness function)とも定義されることがある。
モデルが、どれだけ提供されたデータに良いか(Fit)測定する関数である。
- コスト関数とは?
入力データに対する誤差を計算する関数をコスト関数と呼ぶ。
モデルがどれだけ提供されたデータに悪いかを測定する関数です。
ここでコスト関数と損失関数について理解を進める場上でとても混乱しやすいので注意してください。
損失関数(Loss function)は、入力データに対する予測値と実際値の誤差を計算する関数です。
従って、データセットに対する損失関数の平均として、我々はコスト関数を抽出することができます。
コスト関数は、損失関数よりも上の概念であることをきちんと理解しておきましょう。
ここまでは、機械学習を分類する方法を解説してきました。
機械学習のテクニックの詳細を学び、実践的な例を取り上げる前に、機械学習の後にディープラーニングモデルを
作成するときは、アルゴリズムのパフォーマンスが悪いのか、データが悪いのかを判断して進めていきましょう。
まず、データが悪い場合を見ていきましょう。
データが良くないと判断する基準には、十分でない訓練データの量、代表性のない訓練データがあります。
ここで、機械学習のアルゴリズムで子犬と猫を区別するとしましょう。
サンプルとなる子犬や猫の写真(データ)が足りない場合、アルゴリズムは子犬や猫を簡単に定義できません。
更に子犬の種類が20種類であると仮定した場合、1種類だけ学習したアルゴリズムでは、他の種類の子犬を子犬と
判断することができない可能性が極めて高いと言えます。
更に、データに代表性がない場合もデータが良くない(悪い)となります。
例えば、民主主義国をGDP(Gross Domestic Product)の順で並べた場合、共産主義国のみのデータセットで
GDPグラフを生成することはできません。
この場合には、各国をサンプルと表現することができ、この状況をサンプリングノイズとして説明することができます。
- サンプリングノイズとは?
サンプル数が少なければ少ないほど、サンプリングノイズが大きくなり、精度が低くなることを意味します。
(※ サンプル数が少なく、代表的なデータが存在していない場合も含まれる)
逆にサンプル数が多い場合、代表的データが存在しない時は サンプリングバイアスであると説明ができます。
機械学習やディープラーニングを勉強する際、多くの関連する用語が存在しているが、悪いアルゴリズムの例として
挙げられるのが、モデルの過大適合(Overfitting)と過小適合(Underfitting)である。
- 過大適合とは?(overfitting)
過大適合とは、少ないサンプルを使って学習した結果を一般化することである。
機械学習における過大適合は、モデルが多く存在しているものの、どれも一般的ではない状態のことを言う。
学習するデータが過剰適合の側面を示している場合には、モデルを単純化するために規制を適用するか、自由度を
アルゴリズムに付与するか?が選択肢となります。
規制と自由度の両方が学習アルゴリズムに与えられ、規制の量はハイパーパラメータによって決まります。
また、ハイパーパラメータの種類はアルゴリズムによって異なります。
これは学習アルゴリズムにおけるパラメータです。
ハイパーパラメータはモデルを指すものではないため、学習する前に予め指定しておく必要があります。
尚、学習している間は定数のままになります。
機械学習またはディープラーニングモデルを作成する場合、ハイパーパラメータの調整は非常に重要です。
- 過少適合とは?(underfitting)
過少適合とは、モデルがデータの構造を学習できないほど単純な場合に発生します。
過少適合に対処するためには、モデルの制約(規制ハイパーパラメータ)を減らすか?パラメータをより強力な
モデルに変換する必要があります。
モデルがどれだけのトレーニングデータセットに高精度で学習しているか?を判断する基準について解説しましたが、
モデルがテストデータセット、つまり将来モデルに入る新しいサンプルデータを一般化するかどうか?を判断するための
基準について説明していきます。
作成したモデルが新しいサンプルに適しているかどうか?を判断する基準には、RMSE、SMAPE、F1 SCOREなどがあります。
現在、私がXAIOpsのアルゴリズム性能(精度)を評価する際に、これらの基準をすべて利用しています。
例えば、XAIOpsでのRoot-Mean-Squared-Error(RMSE)は、交差検証区間の予測値と実際の値を比較して、予測アルゴリズムがどれだけ正確に予測したかを評価する際に使われています。
これらのパフォーマンス指標を確認するには、トレーニングデータをトレーニングセットとテストセットに分割が必要です。
まず全トレーニングデータから、通常30%程度をテストセットとして指定します。
これを検証セット(Validation set)といいます。
残りの70%のトレーニングデータから30%を予測後、30%の実際値と予測値を比較します。
これをクロス検証(Cross-validation)といいます。
ここで70%のデータセットでトレーニングを行う時、私たちは先に解説しているハイパーパラメータをチューニングして最もパフォーマンスの良いものを選ぶ必要があります。
クロス検証する方法には、K-Foldクロス検証という方法もあります。
これは、K個のFold(単位)を作って進める方法である。
下の図を参照してください
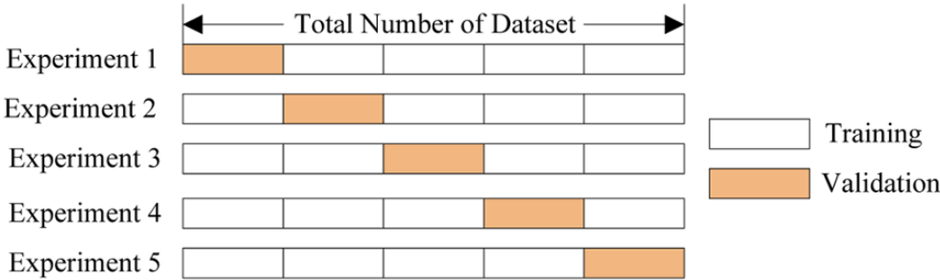
K-Foldクロス検証 [ソース] : https://nonmeyet.tistory.com/entry/KFold-Cross-Validation%EA%B5%90%EC%B0%A8%EA%B2%80%EC%A6%9D-%EC%A0%95%EC%9D%98-%EB%B0%8F-%EC%84%A4%EB%AA%85
既存の交差検証と同様に、トレーニングセットとテストセットを分ける。
上図では5つのFoldに分けたが、データサイズに応じてFoldの個数を決めればよい。
又、訓練セットの範囲を変えながらテストセットの範囲を変えて指定し、交差検証をK回繰り返せば良い。
この方法に1つ欠点があるとすれば、一般的な交差検証よりも時間がかかることです。
しかし、各Foldから導出されたエラー値の平均として、最適なハイパーパラメータを取得することで、
時間はかかるものの、最高のパフォーマンスを得るモデルを見つけ出すことができます。
まとめ
機械学習は何であるか?分類方法に応じたアルゴリズムの種類について調べた上で、アルゴリズムの性能を検証する方法までを
解説してきました。次の章では、アルゴリズムを訓練(学習)するときに重要ないくつかの概念について勉強していきましょう。
Chapter 3.機械学習 終


