
latch: library cache - 日本エクセム株式会社 Oracle待機イベント情報
目次[非表示]
- 1.基本情報
- 2.待機パラメータと待機時間
- 3.チェックポイントとソリューション
- 4.豆知識
- 4.1.ライブラリ・キャッシュの構造
- 4.2.SQL実行時の内部動作
- 5.分析事例
- 5.1.OS空きメモリー枯渇による性能低下現象分析
- 5.1.1.性能低下区間の確認
- 5.1.2.性能低下区間の詳細分析
- 5.1.3.待機イベントの検出および分析
- 5.1.4.解析およびSQL実行に関する性能情報分析
- 5.1.5.OS性能情報およびセッション分析による問題原因究明
- 5.1.6.Oracleパラメータ確認
- 5.1.7.結論
- 5.1.8.解決方法
- 5.2.過度な実行回数による性能低下現象
- 5.3.過度な実行回数による解析遅延およびロック待機現象
- 5.4.ファンクション使用による実行回数増加現象
- 5.4.1.解決策
「 latch: library cache 」など待機イベントは、Oracleデータベースのボトルネックを調べるのに非常に有効です。
Oracleの性能状況把握のために押さえておくべき指標をまとめた「Oracle Wait Event Cheetsheet」をこちらから入手できます。主要な待機イベントの種類と、発生した場合の原因・改善策案などがわかります。
基本情報
共有プール・ラッチが空き領域を探すために空きリストをスキャンして適切なチャンクを割り当てる作業を保護するなら、ライブラリ・キャッシュ・ラッチはSQLを実行するためにライブラリ・キャッシュメモリー領域を探索して管理する全ての作業を保護します。ライブラリ・キャッシュ・ラッチはCPUカウントより大きい素数中一番小さい数だけ子ラッチを持ちます。
ライブラリ・キャッシュ・ラッチを獲得する中で競合が発生すると、latch: library cache待機イベントを待機します。ライブラリ・キャッシュ・ラッチ競合は主に次のような場合に発生します。
ハード解析やソフト解析が多すぎる場合
共有プール・ラッチ競合が主にハード解析による空きリストの探索によって発生するように、ライブラリ・キャッシュ・ラッチ競合の最も重要な原因もハード解析にあります。ハード解析がたくさん発生すると、以下のような理由でライブラリ・キャッシュ・ラッチ競合が発生するようになります。
ライブラリ・キャッシュ・ラッチ競合はハード解析だけではなくソフト解析、すなわちパインド変数をよく使っている場合にも発生します。ソフト解析はハード解析に比べて、コストが非常に低いが、構文検査/意味検査/ライブラリ・キャッシュ探索などの過程は避けられません。ライブラリ・キャッシュを探索する間は、ライブラリ・キャッシュ・ラッチを獲得しなければならないためです。従って、多くのセッションが同時にソフト解析を実行する場合、ライブラリ・キャッシュ・ラッチ競合による性能低下現象が発生することになります。
バージョン・カウントが高い場合
それぞれ違う3人のユーザーが次のように同じSQL文を実行したと想定してみましょう。
上記3つのSQL文はテキストが完全に同じなので同じハッシュ値を持ちます。 従って、同じハッシュ・チェーンの同じハンドルに割り当てられます。しかし、上記のemp表は全て異なるスキーマの表であるため実際には別のSQL文です。 この場合、Oracleはテキストに該当する親ライブラリ・キャッシュ・オブジェクト(Library Cache Object、以下LCO)とその下に3つの子LCOを作って、個別SQL情報を管理します。 3つの子LCOは別のリストに保存されます。そのため、V$SQLAREAビューのVERSION_COUNTカラム値が子LCOの数と同じく3になります。バージョン・カウントが高いということは、子LCO探索する回数が増え、結果的にライブラリ・キャッシュを探索する時間もそれだけ増えるということを意味します。これによってライブラリ・キャッシュ・ラッチ競合が増えることになります。もし、特定SQLでライブラリ・キャッシュ・ラッチ競合が多く発生するなら、該当SQLのバージョン・カウントの値を確認してみる必要があります。
SGA領域のページ・アウトが発生する場合
共有プールがディスクへページ・アウトされた該当領域に対してスキャンが発生する時、再びディスクの内容がメモリーにページ・インされるまで、待機しなければならないのでライブラリ・キャッシュ・ラッチに対する待ち時間が増えます。もし、latch:library cache待機イベントが高い時に、OSでスワップ現象が発生する場合は、ページ・アウトによる性能低下である可能性が高いです。
待機パラメータと待機時間
待機パラメータ
待機時間
待機時間は、指数的に増加します。
チェックポイントとソリューション
解析回数を減らす
ライブラリ・キャッシュ・ラッチの競合を減らす最も良い方法は、1回の解析で複数回実行することです。解析回数を減らせばそれだけライブラリ・キャッシュ・ラッチ競合を減らすことができます。 たとえば、Java環境の場合は、PreparedStatementオブジェクトを利用して、解析を1回だけ実行してcloseを実行しないで、executeを繰り返し実行することによって解析回数を減らすことができます。しかし、常にこの方法を使えるわけではありません。 なぜならアプリケーションで多くの修正が必要になるためです。また、業務ロジックによってはこのような方法を使うことが不可能な場合もありえます。特定のWebアプリケーションサーバーの場合は、ステートメント・キャッシュ機能を提供していますが、この機能を使うことによって同じ効果を得ることができます。
PL/SQLの動的SQLを使う時はライブラリ・キャッシュ・ラッチ競合が増える可能性があることに注意しなければなりません。動的SQLを使うと、PL/SQLのメリットの一つであるカーソル再利用(1回の解析で複数回も実行)機能が使えないため、ソフト解析が増えます。その結果、ライブラリ・キャッシュ・ラッチ競合が増えるようになります。従って、できる限り静的SQLを使うことを推奨します。
SESSION_CACHED_CURSORSパラメータを利用する
SESSION_CACHED_CURSORSパラメータ値が設定されていれば、Oracleは3回以上実行されたSQLカーソルに対する情報をPGA内に保管します。ユーザーがSQL実行を要求する時、OracleはPGA内にキャッシュされた情報があるかを確認して、情報があればその情報を利用します。これによって、ライブラリ・キャッシュ領域を探索する時間が減り、ライブラリ・キャッシュ・ラッチを保有する時間が減ることになります。SESSION_CACHED_CURSORSパラメータのデフォルト値はバージョンごとに異なります。デフォルト値が小さければ、できるだけ50以上の値を設定することが望ましいです。
豆知識
ライブラリ・キャッシュの構造
共有プールで最も重要な部分の一つであるライブラリ・キャッシュ領域はSQLの実行と関連したすべての情報を管理する領域です。ライブラリ・キャッシュは[ハッシュ表->バケット->チェーン->ハンドル->オブジェクト]という仕組みになっています。
下図にはライブラリ・キャッシュの構造が説明されています。
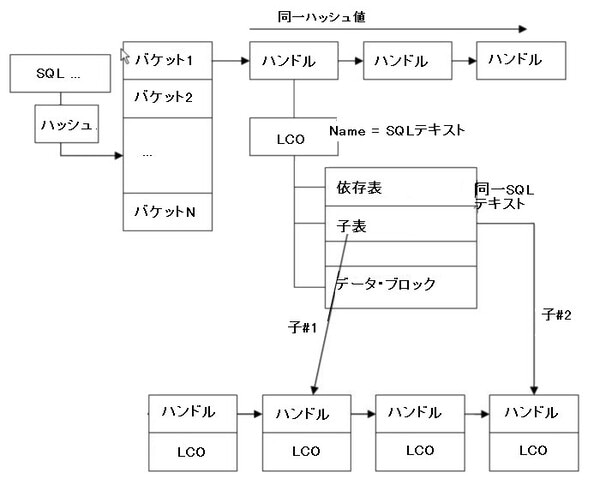
Oracleはオブジェクト名(たとえばSQLテキスト)にハッシュ関数を適用して生成されたハッシュ値を利用し、適切なハッシュ・バケットを割り当てます。この時、同じハッシュ値を持つオブジェクトはチェーン(リスト)で管理されます。一つのライブラリ・キャッシュ・ハンドル(以下ハンドル)は一つのLCOを管理します。ハンドルはLCOに対するメタ情報およびポインタ役割をしており、LCOが実情報を含んでいます。 LCOが含む情報の中で、主なものは次のとおりです。
ライブラリ・キャッシュのダンプをとれば、ライブラリ・キャッシュの構造が物理的にどのように構成されているのか確認できます。
上記のライブラリ・キャッシュ・ダンプで確認できるように、LCOのデータ・ブロック領域ではヒープ領域に対するポインタ(c000000099ad4480)情報を持っています。
ヒープ・ダンプ・ファイルでこのアドレスを問い合わせてみると、次のような値を得られます。
上記の情報はアドレス値に該当するサブ・ヒープ領域を指し、サブ・ヒープ・ダンプを利用して正確なサブ・ヒープとチャンクの位置を確認することができます。
ライブラリ・キャッシュ領域を探索しようとするすべてのプロセスは、必ず該当ハッシュ・バケットを保護するライブラリ・キャッシュ・ラッチを獲得しなければなりません。ライブラリ・キャッシュ・ラッチはCPU数より大きい素数の中一番小さい数だけ使われます。たとえば、CPU数が4つのステムでは5つのライブラリ・キャッシュ・ラッチを使います。ライブラリ・キャッシュにアクセスする過程でライブラリ・キャッシュ・ラッチ競合が発生する場合、プロセスはlatch: library cache待機イベントで待機します。
ライブラリ・キャッシュ・ラッチがライブラリ・キャッシュ領域に対する探索を同期化するために使われるのに対して、library cache lockとlibrary cache pinという2つのロックはハンドルとLCOを保護する役割をします。たとえば、ALTER TABLEコマンドで、表を変更しようとするプロセスは表情報を保存するLCOに対してlibrary cache lockを排他ロック・モードに獲得しなければなりません。library cache lockとlibrary cache pinを獲得する過程で競合が発生すると、それぞれlibrary cache lock待機イベントとlibrary cache pin待機イベントで待機します。
SQL実行時の内部動作
ユーザーがSQL文の実行を要求すると、Oracleはライブラリ・キャッシュのメモリー領域とラッチを利用して必要な作業を行います。
これを時系列でまとめると次のようになります。
解析フェーズで使われたCPU時間と解析を行うためにかかった時間は、parse time cpu統計値とparse time elapsed統計値に記録されます。解析を行う間、ラッチやロックを獲得するために待機する時間が長くなると、parse time elapsed統計値がparse time cpu統計値に比べて、非常に大きくなる場合があります。 特に同時に複数のセッションがハード解析を実行する場合に、parse time elapsed統計値が大幅に増加する現象が起きますが、このほとんどがライブラリ・キャッシュ・ラッチや共有プール・ラッチを獲得する途中で競合が発生し、待ち時間が増加したためです。いくら多くの空きチャンクが存在しても要求されたSQL文が入れる最適な大きさ以上の空きチャンクが見つからなかったら、それ以上の作業は進まないということに注意しなければならなりません。 共有プールに空きメモリーが十分にあるのにももかかわらず、ORA-4031(unable to allocate %s bytes of shared memory)エラーが発生する理由はこのためです。このような現象は、多くの場合過度なハード解析によって、空きチャンクドが小さく分割されている時に発生します。
このような共有プールの断片化は共有プール・ラッチ競合にも大きい影響を与えます。 共有プールが断片化されると、空きリストには多数の空きチャンクドが含まれることになります。空きチャンクを割当られるために空きリストを探索する時は、共有プール・ラッチを獲得しなければなりませんが、空きチャンクが多数に分割されていると、空きリスト探索に時間がかかり、その分共有プール・ラッチを保有する時間も長くなります。
ORA-4031エラーが発生した場合、緊急対応としてALTER SYSTEM FLUSH SHARED_POOLコマンドを使うことになります。なぜなら、共有プールをフラッシュすると連続した空きチャンクを結合するため、次回にSQL文実行を要求した時、適当な大きさの空きチャンクが見つかる可能性が高くなるからです。しかし、これは共有プールをフラッシュすることがORA-4031エラーの解決策であるという意味ではありません。フラッシュをすることによって、他の性能問題が引き起こされる可能性があることには十分注意すべきです。ライブラリ・キャッシュ・ラッチは解析が発生する度に獲得しなければならないため、競合が発生する確率が非常に高いです。ライブラリ・キャッシュ・ラッチ競合はシステムの性能に直結する待機イベントのため、Oracleではライブラリ・キャッシュ・ラッチの競合を減らすために様々な方法を提供しています。 ここでは、2つの方法をご紹介します。
分析事例
OS空きメモリー枯渇による性能低下現象分析
OracleにアクセスしたプロセスはSQL実行のため解析を行う時、SGA領域の一つである共有プール領域を使うことになります。もし、共有プール領域がOSの空きメモリー不足によりスワップ・アウトされた場合は、深刻な性能低下現象が発生します。OSの空きメモリー枯渇によって発生する性能低下現象を、Oracle DBMSの性能診断/分析ツールのMaxGaugeを活用して分析してみます。
性能低下区間の確認
性能問題が発生したインスタンスで収集された稼動ログから推移グラフをみると、12時13分から12時25分間、「CPU」使用率、「Active」および「Wait」が連動して急増したことを簡単に確認することができます。
■ 「CPU」使用率の推移グラフ

■ 「Active」セッション数の推移グラフ

■ 「Wait」の推移グラフ(待機時間)

性能低下区間の詳細分析
問題の区間だけを簡単に確認するために、12時00分~13時00分のデータを拡大して確認してみましょう。
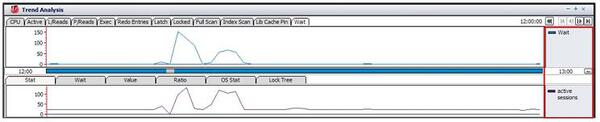
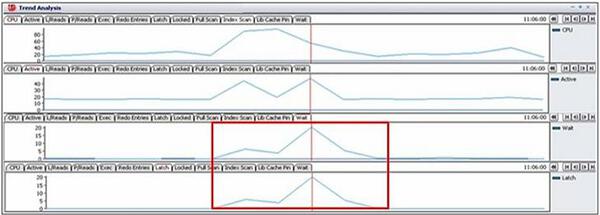
■「Active sessions」推移と「Wait」推移の比較
■「Active sessions」推移と「CPU」推移の比較
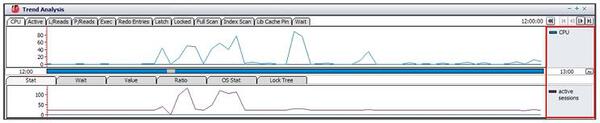
拡大した問題区間のグラフを確認した結果、「Active sessions」推移は「Wait」 推移とは一致しますが、「Active sessions」推移と「CPU」 推移とは若干異なることが分かります。すなわち、「CPU」使用率と「Active sessions」の増加とは直接的には関係しないことが考えられます。
待機イベントの検出および分析
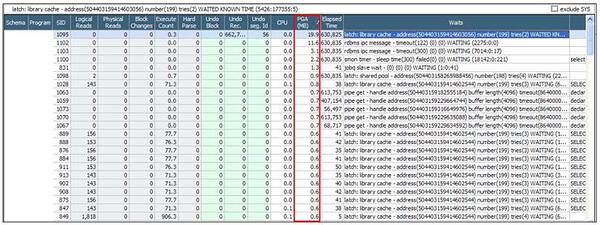
アクティブ・セッションの急増による性能低下の原因を究明するために、問題時点の待機イベントの発生内容を確認してみます。「Value」タプで同じ時点のトップ待機イベントを確認した結果、アイドル・イベント(SQL*Net message from client)を除いたトップ待機イベントは、latch: librery cache待機イベントということが分かります。
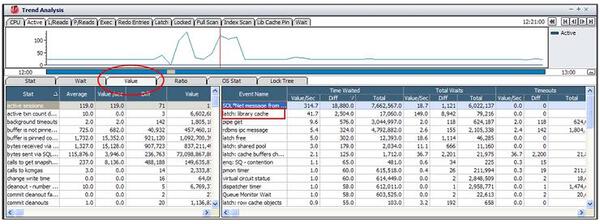
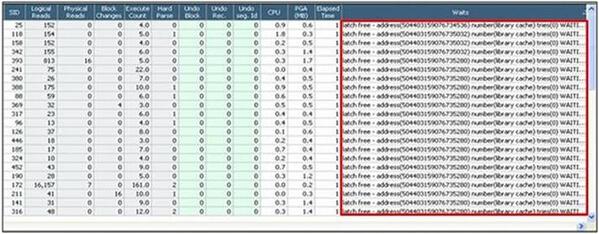
下図の「セッション・リスト」 画面で同時点のセッションの待機イベントを確認してみると、全てのセッションが同じSELECT文を実行中であることが分かりました。また、latch: library cache待機イベントを待機するセッションは全て同じアドレス(504403159414602544)で待機しています。 latch: library cache待機イベントの原因を分析するため、性能情報の推移を確認してみます。
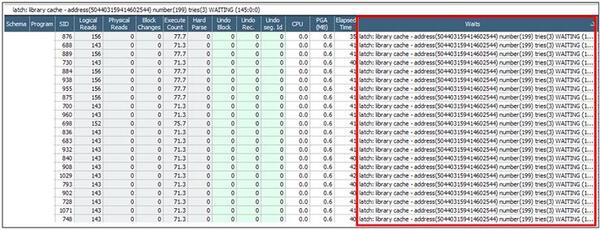
解析およびSQL実行に関する性能情報分析
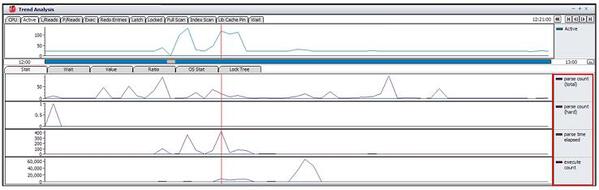
解析と関連した指標のparse count(total)、parse count(hard)、parse time elapsed統計値と、SQL実行と関連した指標のexecute count統計値の推移を確認してみましょう。
下図のグラフでは、性能低下区間にparse time elapsed統計値が高くなっていますが、この区間にparse count(total)、parse count(hard)、execute count統計値は他の区間に比べて、それほど高い値ではありません。 すなわち、解析に必要とされた時間は長かったが、この時点に発生した解析はそれほど多くないことが分かります。parse time elapsed統計値が高いのはその前の区間にハード解析が実行されており、それによる共有プールの断片化が発生された可能性もあります。
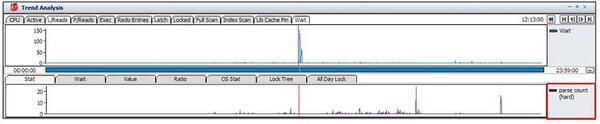
そこで、24時間内で発生したハード解析の推移を確認してみます。
下図のグラフを確認すると、性能低下区間の前にハード解析が多く発生した区間はないことが分かります。分析結果から推論すると、parse time elapsed統計値が高いのはハード解析およびSQL実行回数が多過ぎることとは関連がないことが分かります。次に考えられる原因としては、OSの空きメモリー不足により共有プールのスワップ・アウトによる可能性があります。
そこで、OS性能情報を分析してみることにします。
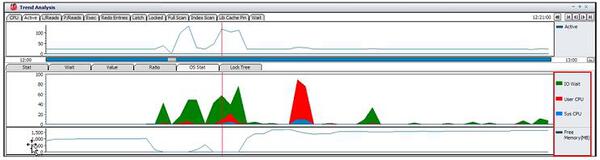
OS性能情報およびセッション分析による問題原因究明
「OS Stat」タブで「IO Wait CPU」、「User CPU」、「Sys CPU」、「Free Memory(MB)」の推移を確認してみます。
下図の推移を確認した結果、性能低下区間に空きメモリーが枯渇するのに伴ってスワップ・アウトが発生し、その結果アクティブ・セッションが急増する現象が発生しています。すなわち、メモリー枯渇によって共有プールがスワップ・アウトされ、これによって解析およびSQL実行をしようとするセッションは共有プールの情報を得るためにスワップ・アウトされたメモリーを再度ロードする作業が必要だったため、latch:library cache待機イベントで長時間待たされたということになります。
該当時点に「セッション・リスト」のPGA(MB)情報を見ると、メモリーを過度に使うセッションは存在していません。つまり、問題の原因はOracleのプロセスではなく他のプロセスがメモリーを過剰に使っていることが考えられます。
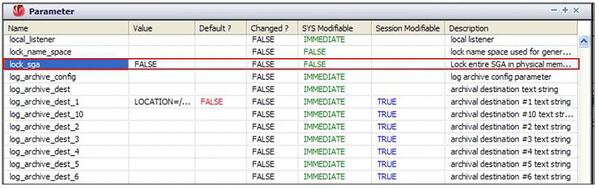
Oracleパラメータ確認
MaxGaugeの「パラメータ」機能で、データベースのパラメータを確認してみた結果、LOCK_SGAパラメータの設定値がFALSEでした。SunOSやLinuxはISM (Intimate Shared Memory)方式を使うのでLOCK_SGA値と関係なく共有メモリーが物理メモリーに固定されますが、HP-UXやAIXの場合にはLOCK_SGA=FALSEの場合SGAがスワップ・アウトされる場合がありますので、このパラメータの値はTRUEに設定することを推奨します。
結論
latch: library cache待機イベントの急増によるアクティブ・セッションの急増
↓
OSのFree Memory枯渇による共有プールのスワップ・アウトとそれに伴う問題発生
解決方法
過度な実行回数による性能低下現象
問題が発生したインスタンスのセッションとSQLの実行履歴をMaxGaugeのログ・データで確認した結果、多くのセッションがlatch:library cache待機イベントで待機しています。 ラッチを待機することによって各セッションのCPU使用率も高くなり、最大70%以上まで使っていることを確認することができます。
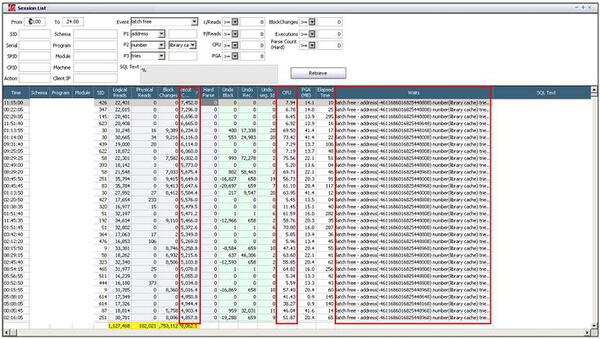
latch: library cache待機イベントはSQLの解析と関係があり、同時にlatch: shared pool待機イベントの待機が発生しないため、ソフト解析が原因であることが考えられます。すなわち、ソフト解析と関連があるSQLの実行回数を確認してみると、セッションのSQL実行回数が4000回以上の非常に高い数値になっていることが分かります。
結論
ライブラリ・キャッシュ・ラッチの原因は過度な解析(高い実行回数)であるため、このラッチが発生した場合は解析回数を減らさなければなりません。
解決策
解析回数を減らす方法としては、下記の3つがあります。
過度な実行回数による解析遅延およびロック待機現象
問題が発生したインスタンスのログを調査すると、多数のセッションでロック競合による遅延が発生していることを確認できます。
ツリー構造でロックを保持しているセッションと待機セッションの関係を調査したのが下図になります。ロックを保持したセッションはges group parent latch待機イベントを待機しています。ges group parent latch待機イベントは共有プールのエンキュー・リソースを保護するラッチです。ロックを保持したセッションがラッチ待機イベントを待機中であるため、作業が進まずロック待機現象が発生しています。
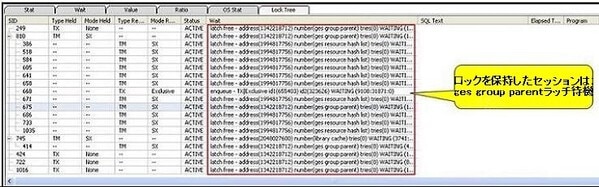
下図の「セッション・リスト」では、同一時点にロック待機セッション以外のセッションはlatch: library cache待機イベントを待機していることが確認できます。
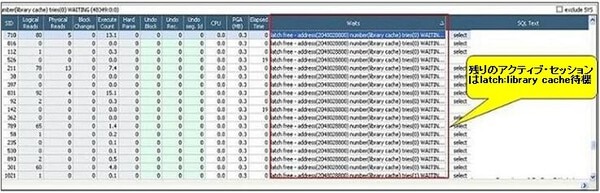
Oracle内部的には、ライブラリ・キャッシュとエンキュー・リソース構造体は全て共有プールに存在するので、多くのセッションが共有プールにアクセスしており、リソースの獲得に時間がかかっていたことが考えられます。
今までの分析した結果をまとめると、下記のようになります。
latch free待機イベントの発生後に、解析回数が増加しているので、解析においてラッチ競合が発生したことが考えられます。
ファンクション使用による実行回数増加現象
開発では、ファンクションを使う場合があります。ここでは、このような場合に発生した性能低下の事例を紹介します。
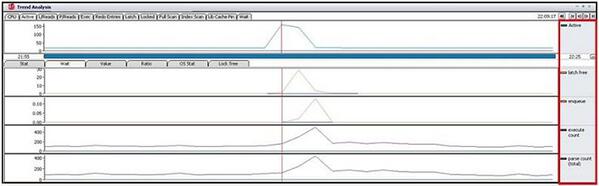
性能問題が発生したインスタンスで収集されたログから推移グラフを見ると、「Active」と「CPU」、「Wait」のグラフが急増しています。
「Wait」グラフの推移はlatch free待機イベントと一致します。
下図の「セッション・リスト」を確認してみると、ほとんどのセッションでlatch free(library cache)待機イベントが発生しています。
待機するアクティブ・セッションが実行しているSQL文は次のとおりです。
このSQLはget_deptというファンクションを使用しており、このファンクションは次のようなコードで構成されています。
このようなファンクションを使う場合、多数の解析によってexecute count統計値が増加します。従って、このファンクションの代わりに他の方法を使ってライブラリ・キャッシュ・ラッチを獲得するためのセッション待機を減らさなければなりません。
ファンクションの結果セットが多くない場合、スカラ・サブクエリやOUTER JOINに変更してファンクションを使わずexecute count統計値を減らす方法を推奨します。
解決策
1)スカラ・サブクエリに変更
2)OUTER JOINに変更
単純に一つの結果を求める場合、上記の方法に変えることによってファンクション実行時のexecute count統計値を減らせることができます。これによってライブラリ・キャッシュ・ラッチを待機するセッション数が減ります。
「 latch: library cache 」など待機イベントは、Oracleデータベースのボトルネックを調べるのに非常に有効です。
Oracleの性能状況把握のために押さえておくべき指標をまとめた「Oracle Wait Event Cheetsheet」をこちらから入手できます。主要な待機イベントの種類と、発生した場合の原因・改善策案などがわかります。

