
latch: cache buffers chains - 日本エクセム株式会社 Oracle待機イベント情報
目次[非表示]
- 1.基本情報
- 2.待機パラメータと待機時間
- 3.チェックポイントとソリューション
- 3.1.非効率なSQLのチューニング
- 3.2.ホット・ブロックの分散
- 4.豆知識
- 4.1.バッファ・キャッシュの構造
- 5.分析事例
- 5.1.不適切な索引カラムによる待機
- 5.2.過度な論理読取りによる待機
- 5.2.1.性能低下区間の確認
- 5.2.2.待機イベントの検出および分析
- 5.2.3.待機イベント発生原因
- 5.2.4.セッションおよびSQLの分析
- 5.2.5.結論
- 5.3.非効率な索引の選択による待機Ⅰ
- 5.4.非効率な索引の選択による待機Ⅱ
「 latch: cache buffers chains 」など待機イベントは、Oracleデータベースのボトルネックを調べるのに非常に有効です。
Oracleの性能状況把握のために押さえておくべき指標をまとめた「Oracle Wait Event Cheetsheet」をこちらから入手できます。主要な待機イベントの種類と、発生した場合の原因・改善策案などがわかります。
基本情報
バッファ・キャッシュを使うためハッシュ・チェーンを探索したり変更を加えようとするセッションは、必ずそのチェーンを管理しているcache buffers chainsラッチ(以降、CBCラッチ)を獲得しなければなりません。このラッチを獲得する時に、競合が発生するとlatch: cache buffers chains待機イベントで待機します。
Oracle9i以降からは読み取り専用を保護するため、チェーンを探索する場合にはCBCラッチを
共有モードで獲得し、競合を減らせるようになっています。これには一つ注意すべきことがあります。理論的にはSELECT文が同時に発行された場合は、CBCラッチを共有できるため、CBCラッチ競合が発生してはいけませんが、実際テストをしてみるとラッチ競合は相変らず発生します。その理由は、バッファ・ロックと関連があります。読み取り専用で作業を行うために共有モードでラッチを獲得した場合、バッファをスキャンする時はバッファ・ロックを共有モードで獲得しますが、バッファ・ヘッダーの情報を一部変更するため、バッファ・ロックを獲得する時と解除する時には、ラッチを排他モードに変更する必要があります。この過程で競合が発生し、これによっlatch: cache buffers chains待機イベントで待機します。
CBCラッチ競合が発生する代表的なケースは2つあります。
非効率なSQL
非効率なSQLは、CBCラッチ競合を引き起こす最も重要な原因です。例えば、同時に複数のセッションが広い範囲の索引や広い範囲の表に対してスキャンする場合、CBCラッチ競合が多く発生します。
CBCラッチ競合が発生した場合、正確な競合の原因を調べることが大事です。ラッチの競合がホット・ブロックで発生しているのか、それとも非効率なSQLによって発生しているのかを判断するための、最も確実な根拠はSQLそのものにあります。従って、効率が悪いSQLが作成されていると判断できる根拠がある場合は、SQLをチューニングすることで問題を解決することができます。
もし、SQLに対する情報がない場合は、ホット・ブロックによる問題なのか、非効率なSQLによる問題なのかを判断できる別の方法があります。まずは、V$LATCH_CHILDRENビューで子CBCラッチに該当するCHILD#とGETS、SLEEPS値を比較して、ある特定の子ラッチに使用回数と競合が集中していないかを確認する方法です。下記のコマンドでSLEEPSの回数が多い子ラッチを確認します。
もし、ある子ラッチのGETS、SLEEPS値が他の子ラッチに比べて非常に高いと、該当ラッチが管理するチェーンにホット・ブロックがあることが推測できます。上記のテストを実行した結果、ある特定のラッチに重なる現象は見られないためホット・ブロックによる問題はないと判断します。
ホット・ブロック発生を判断するもう一つの方法は、V$SESSION_WAITビューからラッチのアドレスを確認して比較することです。CBCラッチの場合V$SESSION_WAIT.P1RAWが子ラッチのアドレスに該当します。万一V$SESSION_WAITビューで同じラッチのアドレスが過度に発生しているようであれば、ホット・ブロックによる競合と解釈することができます。
ホット・ブロック
SQLが適切にチューニングされたにもかかわらず、CBCラッチの競合が解消しない場合があります。SQLが少数の特定ブロックを何回もスキャンする形で作成されたアプリケーションでは、様々なセッションで同時にこのSQLを実行する場合、ホット・ブロックによるCBCラッチ競合が発生します。
V$LATCH_CHILDRENビューで、ある特定の子ラッチだけ重なって使用されていることを確認すれば、ホット・ブロックによるラッチ競合が発生していたと判断できます。または、V$SESSION_WAITビューのP1RAWカラムの値をラッチのアドレスとして検索時に利用しても構いません。
下記のコマンド実行結果では、CHILD# 569、827、178の3つの子ラッチが集中的に使われており、これによってラッチ競合が発生したことを確認できます。
X$BHビューを利用すれば、どのブロックがホット・ブロックになっているかを確認することができます。ユーザーオブジェクト(表、索引)でありながら、接触した回数(TCH)が高いブロックを抽出し、ホット・ブロックを確認します。
下記の結果では、CBC_TEST_IDX索引の45918、45919、100ブロックでほとんどの競合が発生していることが推論できます。
待機パラメータと待機時間
待機パラメータ
待機時間
待機時間は、指数的に増加します。
チェックポイントとソリューション
非効率なSQLのチューニング
非効率なSQLをチューニングして論理読取りを減らすと、バッファ・キャッシュに対するアクセスが減るため、それだけCBCラッチ競合も減少します。
ホット・ブロックの分散
ホット・ブロックのためCBCラッチ競合が発生した場合は、ホット・ブロックを分散することによって競合を減らすことができます。ホット・ブロックを分散させる方法は下記の通りです。
表でCBCラッチの競合が発生した場合は、比較的簡単に解決できます。行を分散させるために、様々な方法があるためです。一方、索引で競合が発生した場合は問題を解決するのが非常に難しいです。なぜなら、ソートされた形で格納されている索引の固有の特性のため、任意のブロックに分散させることが不可能な場合があるためです。この場合にはPCTFREEを高くするか、ブロックを小さくする方法以外には解決策はありません。この場合にブロック数が増え、逆にラッチ競合が増える場合もあるため適用時には必ず注意が必要です。
豆知識
バッファ・キャッシュの構造
Oracleは物理I/Oを最小化するために、最近使われたブロックに対する情報をメモリー領域に保存します。このメモリー領域をバッファ・キャッシュと言います。バッファ・キャッシュは共有プール、REDOログ・バッファと共にSGAを構成する最も重要なメモリー領域の一つです。
下記のコマンドでインスタンスのバッファ・キャッシュの大きさが分かります。
Database Buffersの値がインスタンスの現在バッファ・キャッシュの大きさです。Oracleはバッファ・キャッシュを効率的に管理するためにハッシュ・チェーン構造を使います。ハッシュ・チェーンは共有プール内に存在し、Oracleの典型的なメモリー管理手法であるバケット→チェーン→ヘッダーの仕組みで構成されています。
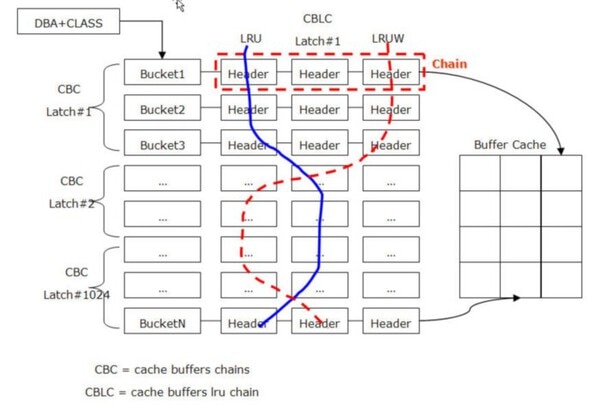
ハッシュ・チェーン構造の開始点はハッシュ表です。ハッシュ表はいくつかのハッシュ・バケットで構成されています。一つのハッシュ・バケットはハッシュ関数の結果です。Oracleはブロックのアドレス(DBA: Data Block Address。 File#とBlock#で構成されている)とブロック・クラスに簡単なハッシュ関数を適用した結果を利用してハッシュ・バケットを探していきます。ハッシュ・バケットには同じハッシュ値を持つバッファ・ヘッダーがチェーンの形で繋がっています。バッファ・ヘッダーはバッファに対するメタ情報を持っており、メモリー領域での実際バッファに対するポインタ値を持っています。ハッシュ・チェーン構造は共有プールに存在していますが、バッファに対する実情報はバッファ・キャッシュ領域に存在しています。
ハッシュ・チェーン構造はCBCラッチで保護されます。特定のブロックをスキャンするセッションは、必ず該当ブロックに対するハッシュ・チェーンを管理しているCBCラッチを獲得しなければなりません。基本的には、一つのセッションだけが一つのCBCラッチを獲得できます。また、一つのCBCラッチはいくつかのハッシュ・チェーンを管理します。従って、同時に多数のセッションがバッファ・キャッシュを探索する場合は、CBCラッチを獲得するため競合が発生し、latch: cache buffers chains待機イベントで待機します。
Oracle9iからは読み取り専用の作業に限ってCBCラッチを共有モードで獲得します。従って、同時に読み取り作業を実行するセッション間にはCBCラッチを共有することができます。しかし、前述したようにバッファに対してバッファ・ロックを獲得したり解除する時に、CBCラッチを排他モードに変える必要があるため、読み取り作業だけの場合にもCBCラッチ競合は相変らず発生します。
下記のコマンドでCBCラッチ数を求めることができます。
または、_DB_BLOCK_HASH_LATCHES隠しパラメータを確認しても同じ結果を得ることができます。ハッシュ・バケットの数は、_DB_BLOCK_HASH_BUCKETS隠しパラメータで確認可能です。
分析事例
不適切な索引カラムによる待機
latch: cache buffers chains待機イベント発生の検証シナリオは下記の通りです。
同時に多数のセッションから下記のSQLを実行します。
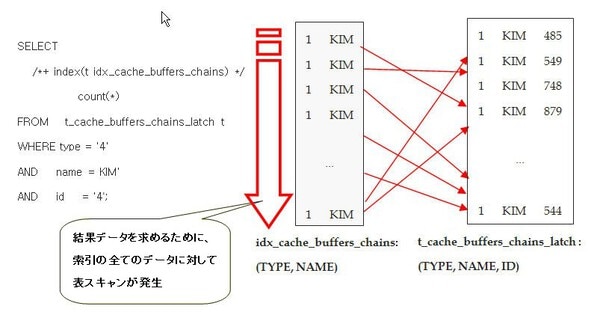
この状況で監視した結果が下記の通りです。latch: cache buffers chains待機イベントが最も発生していることが分かります。
実行結果 | Type=EVENT, Name=jobq slave wait, Value=50404(cs) |
MaxGaugeのアクティブ・セッション・リストで、ほとんどのアクティブ セッションがlatch: cache buffers chains待機イベントで待機していることを確認します。
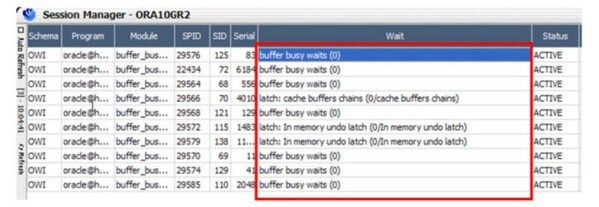
このような状況でlatch:cache buffers chains待機イベントが発生する理由は次の通りです。
SQLの検索条件の中、idカラムは選択度がいいので、索引使用時にはこのカラムを利用するようにします。
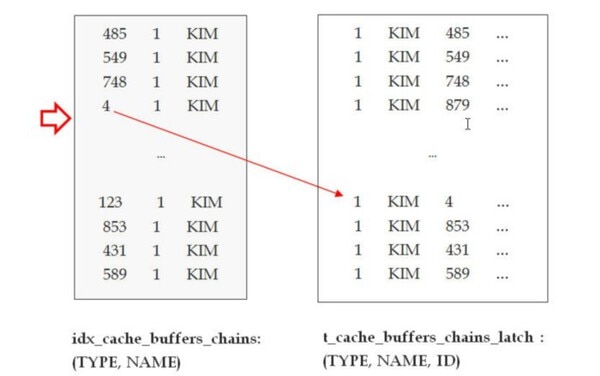
性能改善後のシステム監視結果は下記の通りです。latch: cache buffers chains待機イベントの待機時間が1133(cs)で、性能改善前の待機時間が3061(cs)だったことに比べると、3倍ほどの改善効果がありました。
実行結果 | Type=EVENT, Name=jobq slave wait, Value=4994(cs) |
過度な論理読取りによる待機
同時ユーザー数が多いOLTPおよびWEB環境で、適切ではない索引の使用による過度なI/O発生は
性能面で深刻な問題を引き起こす場合が多いです。MaxGaugeを使用して、不適切な索引の使用による過度なI/O発生が引き起こす性能低下問題の原因を究明します。
性能低下区間の確認
性能問題が発生したインスタンスで収集した稼動ログからグラフを確認すると、21時35分前後で「Active session」数、「Wait」イベントが、類似した推移で変化しています。
■「Active Session」の推移グラフ

■「Wait」イベントの推移グラフ(待機時間もしくは待機回数)

待機イベントの検出および分析
アクティブ・セッションの急増による性能低下の原因を究明するため、問題時点(21時35分)の待機イベントの発生内容を確認します。
「Value」タブでこの時点のトップ待機イベントを確認した結果、Idle Event(= SQL*Net message from client)を除いたトップ待機イベントはlatch freeであることが確認されます。
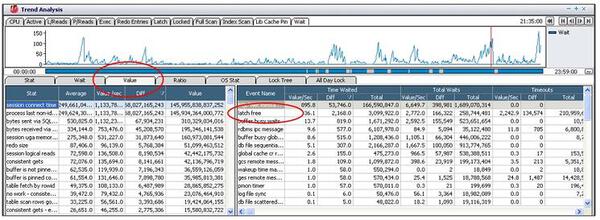
アクティブ・セッションの急増に対するlatch free待機イベントの関連性を判断するために、待機イベントとの発生パターンを比較してみた結果、アクティブ・セッションの発生推移と非常に類似しており、問題時点に発生した待機イベントの待機時間の約53.4%(全体109.89秒中、58.69秒)を占めていることから、アクティブ・セッションの急増はlatch free待機イベントの急激な発生と関連があることが推論されます。
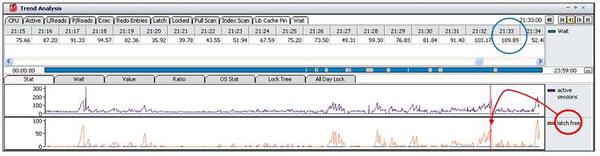
実際に、同じ時間に詳細内容を表示しているセッション・リスト画面でも、latch free待機イベントがトップ待機イベントになっており、その中でもlatch: cache buffers chain待機イベントが多く発生していることが確認されます。
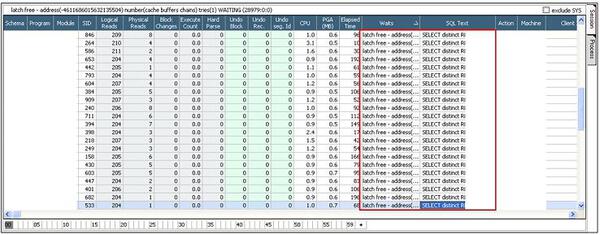
待機イベント発生原因
latch free待機イベントの発生には様々な原因がありますが、一般的にlatch: cache buffers chain待機イベントが発生した場合には、ホット・ブロックがその原因であることが多いです。ホット・ブロックは全表走査よりは索引レンジ・スキャンで頻繁に発生します。解決策としてはSQLチューニングを実施し、索引を検索する範囲を減らす方法があります。SQLチューニングが不可能な場合にはブロック・サイズを減らしたりPCT FREE値を増加させ、ブロック当たり行数を減らすのも一つの方法です。
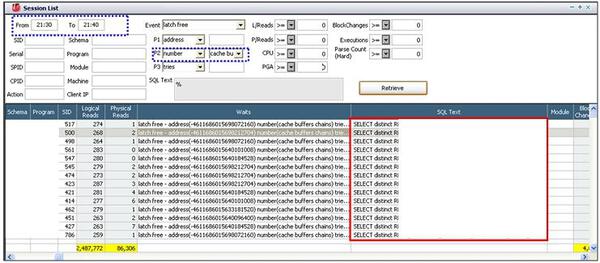
セッションおよびSQLの分析
latch: cache buffers chain待機イベントの発生が多かった21時30分~21時40分で、latch freeを発生させたSQLリストを確認すると、同じパターンを持ったSQLであることが分かりました。
結論
latch: cache buffers chain待機,イベントの多発によるアクティブ・セッションの急増
↓
非効率的な索引スキャンによる性能低下の発生
↓
SQLの検索条件のカラムで索引スキャンのみを実行するように索引を再作成し、解決
非効率な索引の選択による待機Ⅰ
性能問題が発生したインスタンスでアクティブ・セッションの推移を確認します。問題区間のアクティブ・セッションはlatch: cache buffers chain待機イベントで待機しており、アクティブ・セッション・リストのラッチのアドレスは16321267696であることを確認します。
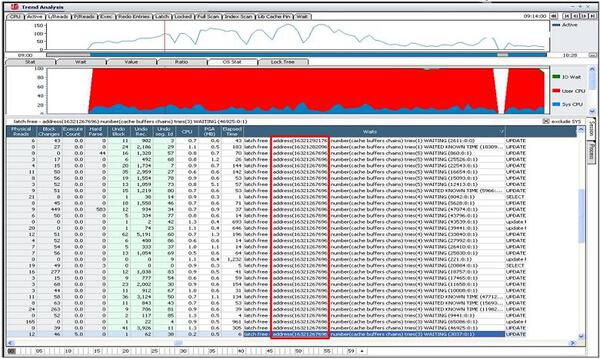
ラッチ競合が発生したラッチのアドレスをX$bhビューと結合して、どのオブジェクトのブロックなのか、どのブロックがTCHが高いかを確認します。
同じラッチ・アドレスで検索した結果、いくつかのオブジェクト結果値が出てくる理由は、一つのラッチがいくつかのチェーンを管理しているためです。問題のインスタンスのCBCラッチ数は1024個で、ハッシュ・バケットの数は、254083個です。すなわち、問題のインスタンスで1個のCBCラッチは約249個のチェーンを管理している状況です。
ABC$123索引が最もTCH値が高いため、CBCラッチの競合を発生させたブロックであることが推測されます。
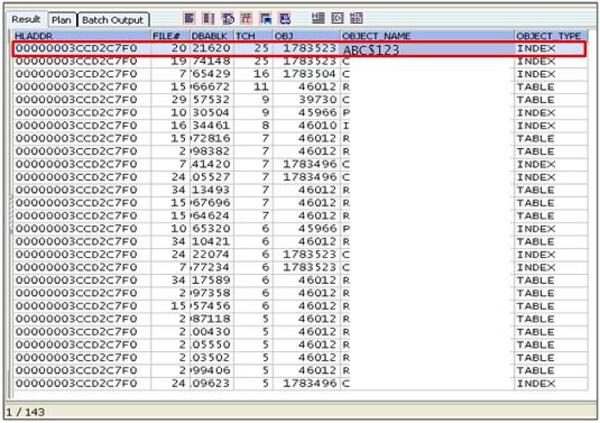
DBA_INDEXESビューを通じて、この索引の表を確認し、表の索引構成を確認します。
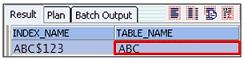
ABC表はABC_NUM + ABC_TIMで構成された一意索引のABC$PK索引とABC_TYPEで構成されたABC$123索引を保持しています。ラッチ競合で問題になった索引はABC$123索引です。
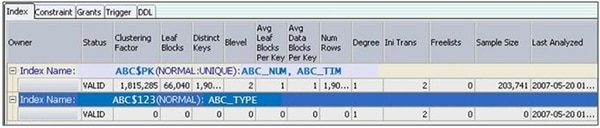
競合が発生したセッションの下記のSQLのトレース結果を確認します。
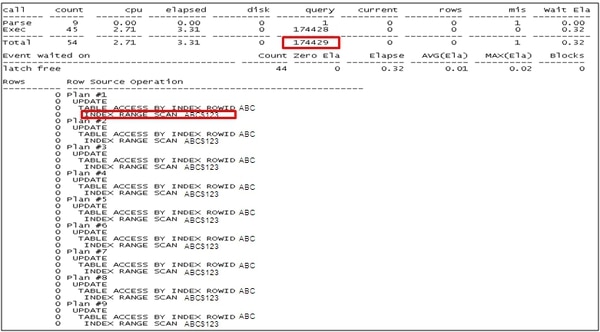
SQLのWHERE条件にABC$PKのカラムが含まれているにもかかわらず、範囲が広い索引が選択されたことが分かります。(赤く表示した部分から、不必要に174429ブロックをアクセスしていたことが確認されます。)ここで、ヒントを使用してABC$PK索引経由で実行されるように変更すれば、latch: cache buffers chain競合を解消することができます。
非効率な索引の選択による待機Ⅱ
システムのCPU使用率のグラフが論理読取りや物理読取りと類似したパターンになっています。SQLの実行回数であるExecute Countは、平均500回程度を維持しており、SQLの実行が多くてCPU使用率が上がったとは考えにくいです。
この区間の「Active Session」グラフの推移を確認すると、latch free待機イベントグラフの推移グラフと非常に似ていることが分かります。また、latch: cache buffers chain待機イベントを待機するセッションも確認されます。
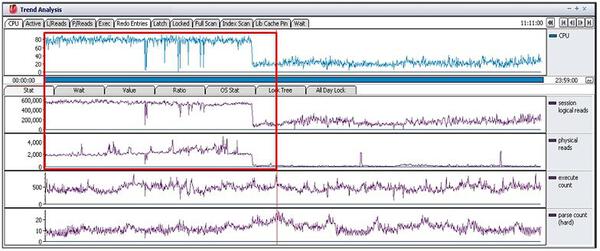
latch: cache buffers chain待機イベントはSQL実行時に、広い範囲を処理する時に発生します。また、db file sequencial reads待機イベントの発生推移も似ていることから、SQLが非効率な索引で索引スキャンが行われていたと考えられます。
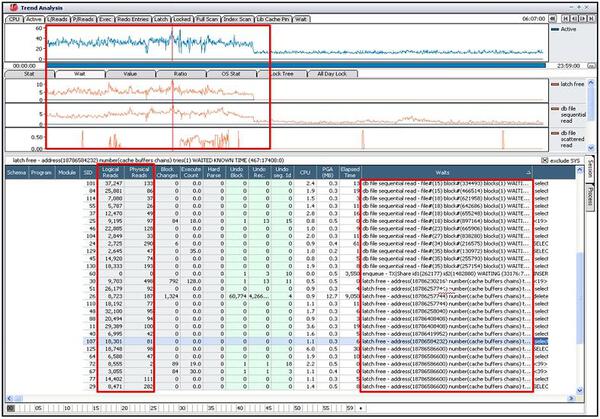
この事例は、セッションが実行しているSQLで統計情報が変更され、本来の索引の代わりに、非効率な索引が選択されデータにアクセスした場合です。
例えば、下記のSQLでは、emp_idカラムにTO_NUMBERという関数を使用したため、該当索引を利用できずemp_nameカラムの索引を利用して実行されたと考えられます。
この場合は、次の通りにSQLを変更することを推奨します。
このように、latch: cache buffers chain待機イベントが発生した場合は、処理量が多いSQLを抽出し、処理量を減らすためにチューニングをする必要があります。
「 latch: cache buffers chains 」など待機イベントは、Oracleデータベースのボトルネックを調べるのに非常に有効です。
Oracleの性能状況把握のために押さえておくべき指標をまとめた「Oracle Wait Event Cheetsheet」をこちらから入手できます。主要な待機イベントの種類と、発生した場合の原因・改善策案などがわかります。

