

2021.11.02
EXISTS構文を利用したSQLチューニング事例
2021. 4. 28. 09:13

SQLチューニングとは?
SQL(Structured Query Language)は、リレーショナルデータベースからのデータを処理する目的で利用するクエリ言語であり、SQLチューニングのためにSQLの理解と構文の正確な分析が必要です。
今回のエキスは、複数のチューニング事例の中からEXISTS 構文を利用したチューニング事例をご紹介いたします。
テーブルとINDEX情報
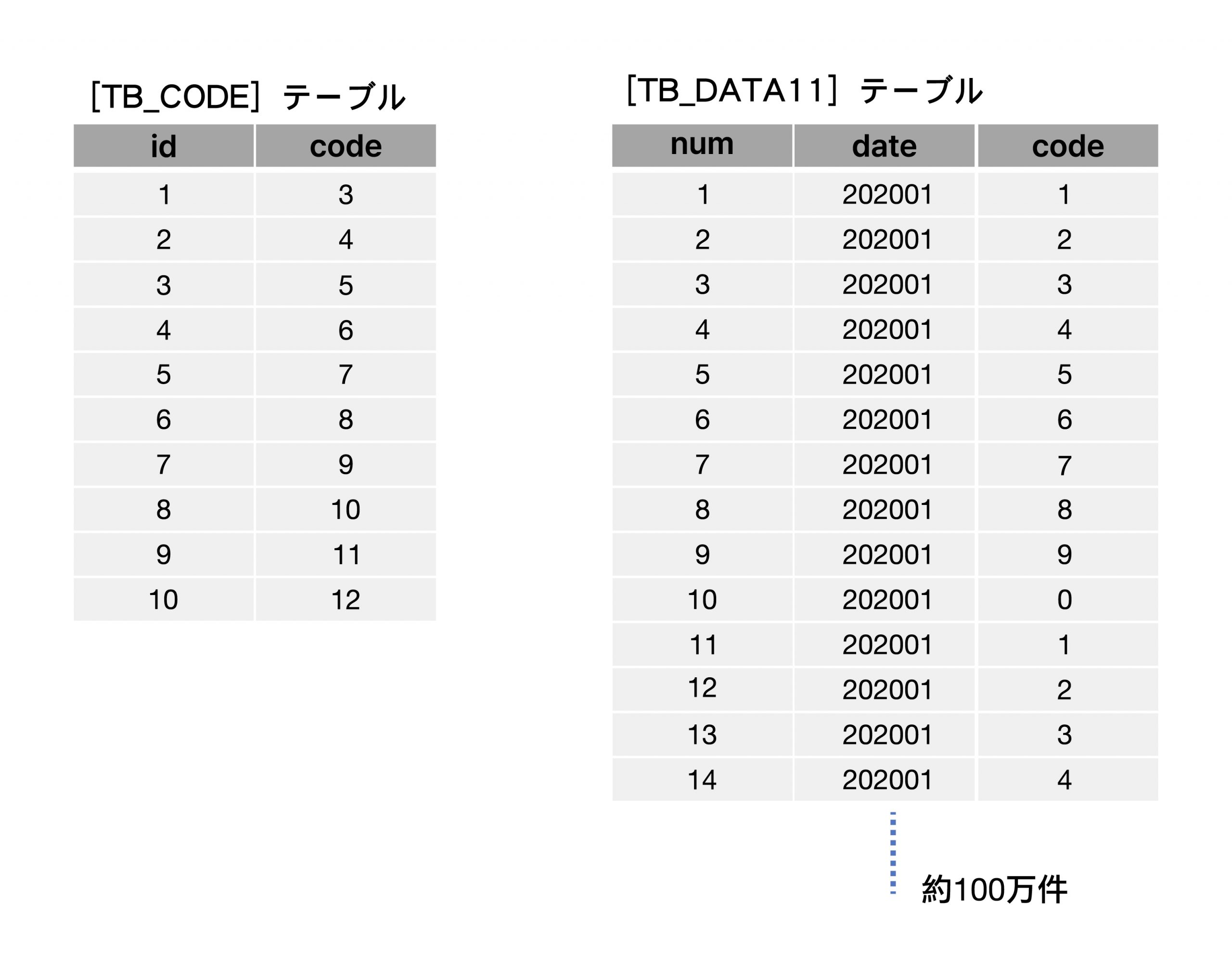
.png)
[TB_CODE]テーブルには10件のデータ、[TB_DATA11]テーブルには約100万件のデータが蓄積されています。 [TB_CODE] テーブルに [code] 列をキー、[TB_DATA11] テーブルに [code, date] 列をキーとして Non-Clustered Index が構成されています。
ユーザーの要件が「[TB_CODE]テーブルの[code]値のうち、[TB_DATA11]テーブルに値が存在する2020年1月以降の[code]値のみを出力したい」という場合、SQL構文は次のように作成できます 。
SQL構文と実行計画
| SELECT A.code FROM TB_CODE A INNER JOIN TB_DATA11 B ON A.code=B.code AND B.date >‘20200101’ GROUP BY A.code ORDER BY A.code GO |
.png)
構文の場合は、ユーザーの要件に合わせて作成されていますが、実際に実行された実行計画を解釈すると、「[TB_CODE]テーブルに基づいて[TB_DATA11]テーブルと[code]列に結合し、結合結果セットの[code]値を GROUP BY して重複値を削除して照会する」となっていることが分かります。
最終結果件数は7件であるにもかかわらず、45万件のデータを読み取り、これをGROUP BYして重複除去するロジックは不要なIOを発生する要因であるため最適化が必要です。
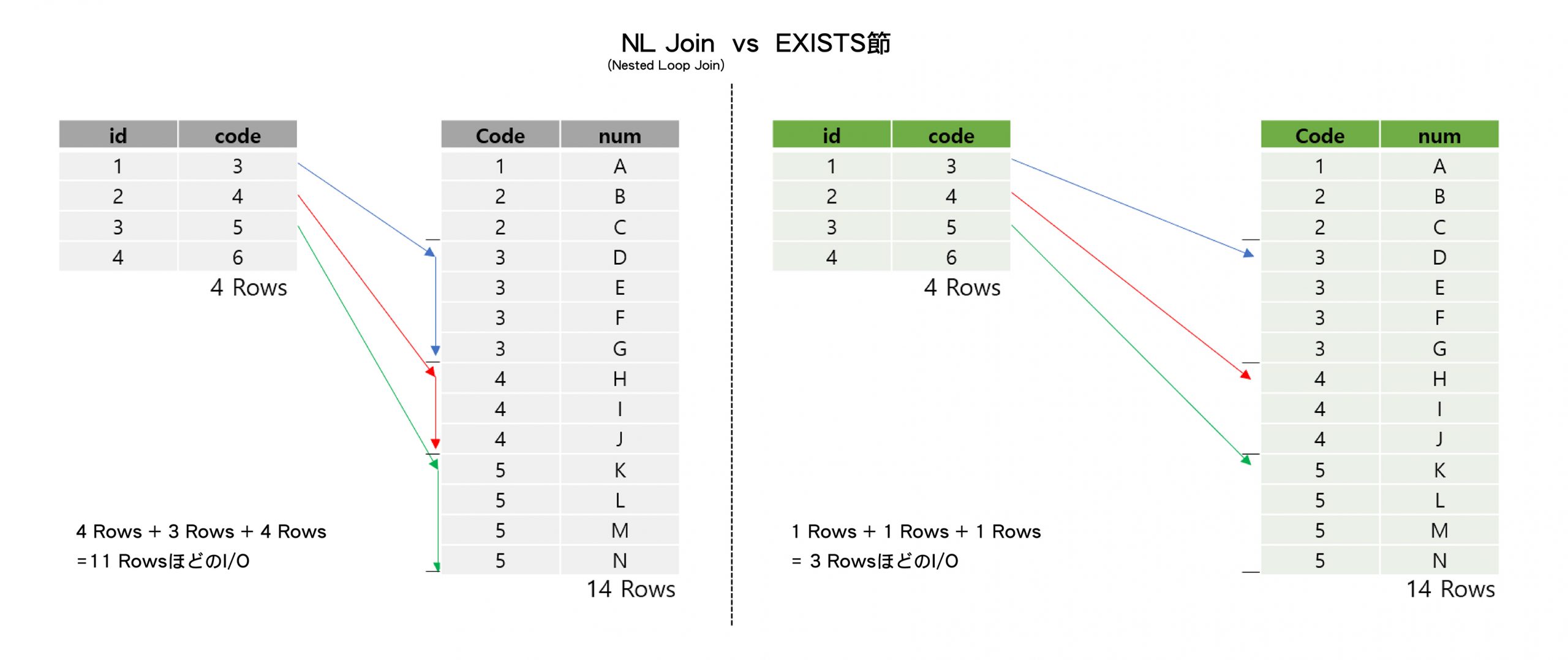
さらに、その計画はNLジョイン(Nested Loop Join)で行われました。
NL 結合特性上、先行テーブル件数だけ後続テーブルに結合しようとするため、先行テーブル件数が多いほど多くの IO を発生する要因です。
では、その構文の最適化はどのように進むべきでしょうか?
[TB_CODE] テーブルの [code] 値が [TB_DATA11] テーブルに存在しますが、確認すればよいので、EXISTS 節を考慮していることが分かります。
EXISTSは内部的にセミジョインで行われ、メインクエリの1つの行に対してサブクエリのすべての行と結合する方法ではなく、最初の結合に成功した行にあったら、もう結合せずにその行を最終 結果セットに含めるため、不要なIOを最小限に抑えることができます。
EXISTS句を考慮したSQL構文に変更するには、[TB_CODE]テーブルと[TB_DATA11]テーブルを内部結合して集計する構文をサブクエリであるEXISTS句に変更します。
変更されたSQL構文は、メインクエリの結果セットである10件の行をサブクエリと結合しながら存在の有無だけを確認すればよいため、IOが改善され、変更されたSQL構文は次のとおりです。
変更されたSQL構文と実行計画
| SELECT A.code FROM TB_CODE A WHERE EXISTS ( SELECT ‘1’ FROM TB_DATA11 B WHERE A.code=B.code AND B.DATE >‘20200101’ ) GROUP BY A.code ORDER BY A.code GO |
.png)
変更前実行計画と比較すると、後続テーブルの結果Rowsが約45万件から7件に減ったことが確認できます。
つまり、先行テーブル10件に対して末尾テーブル[code]値と一致する行があると、結果セットに含めて以降不要なデータは読み取らず、直前のテーブルの次の値を比較するため、IO減少効果が得られていることが分かります。
改善効果
.png)
終わり…
EXEMのSQL Serverチームは、MaxGauge for SQL Serverだけでなく、チューニングとコンサルティングもサポートしています。
SQLパフォーマンス問題関連のチューニングブックも今年出版準備中ですので、ご期待ください!




