
gc cr/current block 2-way - 日本エクセム株式会社 Oracle待機イベント情報
目次[非表示]
- 1.概要
- 2.待機パラメータと待機時間
- 3.チェックポイントとソリューション
- 4.豆知識
- 4.1.2-wayと3-wayの違い
- 4.1.1.gc cr blocks served
- 4.1.2.gc cr blocks served
- 4.1.3.gc cr block build time
- 4.1.4.gc cr block flush time
- 4.1.5.gc cr block send time
- 4.1.6.gc cr block flush time
- 4.1.7.gc cr block send time
- 4.1.8.gc current blocks served
- 4.1.9.gc current block pin time
- 4.1.10.gc current block flush time
- 4.1.11.gc current clock send time
- 4.1.12.gc cr blocks received
- 4.1.13.gc cr block receive time
- 4.1.14.gc current blocks received
- 4.1.15.gc current block receive time
- 4.1.16.gc blocks lost
- 4.1.17.blocks corrupt
- 4.1.18.gc CPU used by this session
概要
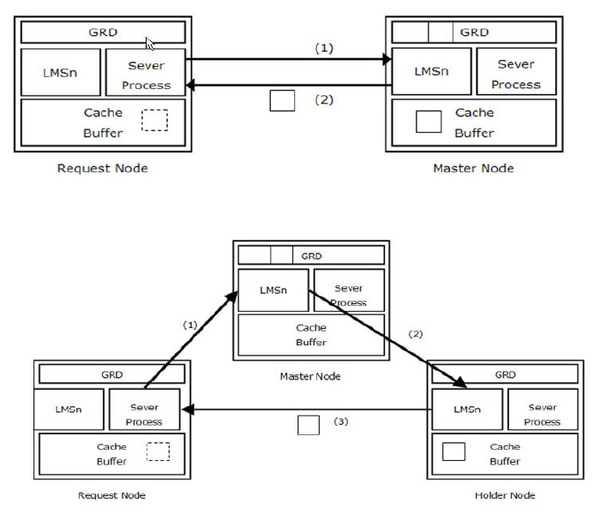
gc cr/current block 2-wayイベントは、gc cr/current requestイベントのFixed-upイベントで、ブロックを要求されたプロセスがマスターノードから直接ブロックイメージを転送受信したことを意味します。 gc cr/current requestイベントが、gc cr/current block 2-wayイベントに変わる(fixed upされている)の流れは、以下の通りです。
リクエストノードのユーザプロセスが特定のデータブロックをCRモードまたはCurrentモードで読もうとします。
ユーザプロセスは、データブロックの適切なバージョンがローカルバッファキャッシュにないことを確認し、マスターノードのLMSプロセスにブロック転送を要求します。ユーザプロセスは、応答を受信するまで、gc cr requestイベントやgc current requestイベントを待機します。
マスターノードのLMSプロセスは、自分のローカルバッファキャッシュに要求されたブロックのイメージが存在することを確認して、インターコネクトを介してそのブロックのイメージを送信します。 CRブロックを送信する場合には、gc cr blocks served、gc cr block build time、gc cr block flush time、gc cr block send time統計値が増加します。 Currentブロックを送信する場合には、gc current blocks served、gc current block pin time、gc cr block flush time、gc cr block send time統計値が増加します。
ユーザプロセスは、ブロックイメージを送信されることで、gc cr / current requestイベントをFixed-upイベントgc cr block 2-wayイベントやgc current block 2-wayイベントに変更shじます。 CRブロックを送信された場合には、gc cr blocks received、gc cr block receive time統計値が増加します。 Currentブロックを送信された場合には、gc current blocks received、gc current block receive time統計値が増加します。
Oracleは、すでにローカルキャッシュに読み取ることができるバージョンのブロックが存在する場合、すなわち、現在のSQL文が要求するSCNを満足するブロックがローカルキャッシュに存在する場合、追加のグローバルキャッシュの同期処理を実行せずに、ローカルキャッシュにあるブロックのイメージを使用します。そのため、SQL文のチューニングと効率的なバッファキャッシュを使用して、一度ローカルキャッシュに読み込んだブロックを最大限に再利用することがRACのための最高のチューニング方法になります。
ローカルキャッシュに読み取ることができるバージョンが存在する場合には、グローバルキャッシュの同期を実行していない正確な条件を理解する必要があります。
RACシステムで「CRモードで読むことができるバージョンのブロック」の正確な意味は、「共有モード(Shared Mode)でBLロックを獲得したブロック」のことです。つまり、ローカルバッファキャッシュにBLロックを共有モードで獲得したブロックが存在する場合には、グローバルキャッシュの同期作業をせず、ローカルバッファキャッシュから直接ブロックを読み込みます。リクエストノードのユーザプロセスがCRモードのブロック転送を要求された後、データブロックの共有モードでBLロックを獲得する場合は、次のとおりです。
クラスタ全体で最初のブロックを読み込む場合は、gc cr grant 2/3-wayイベントがFixed-upイベントに使用されます。
ホルダーノードが共有モード(Shared Mode)で読み込んだブロックを送信される場合は、、gc cr block 2-way / 3-wayイベントがFixed-upイベントに使用されます。一つのブロックに複数のノードが同時に共有モードでBLロックを獲得することになます。
ホルダーノードが排他モード(Exclusive Mode)で読み込んだブロックを送信し、このブロックが_FAIRNESS_THRESHOLDパラメータ値(デフォルトは4)を超えて送信された場合には、gc current block 2-way / 3-wayイベントがFixed-upイベントに使用されます。特定のブロックを排他モードで保有しているホルダーノードは、当該ブロックのCRモードの転送が要求された場合には、自分が現在保有している排他モードのロックを維持します。ロックダウングレードが過度に頻繁に発生することを防止するための施策です。この場合、要求ノードは、共有モードではなく、Nullモード(Null Mode)でBLロックを獲得します。しかし、要求ノードが継続してロックダウングレードの要求をする場合には、すなわち、CRモードの要求をする場合には、排他モードのロックを共有モード(Shared Mode)にダウングレードして、他のノードがBLロックを共有モードで獲得することを可能にします。これを制御するパラメータが、_FAIRNESS_THRESHOLDパラメータであり、文字通り「ノード間公平性を制御する」役割を担います。
_FAIRNESS_THRESHOLDのしきい値を超えてロックダウングレードが発生した場合の数は、V$ CR_BLOCK_SERVERビューで確認することができます。
全体CRブロック要求回数比ロックダウングレード発生回数が約5%程度良好な数値を示します。
CRブロック要求によるロックダウングレード発生回数が過度に高い場合には(25%以上)、_FAIRNESS_THRESHOLDパラメータ値を1または2程度下げることを考慮する必要があります。ロックダウングレード回数が高いということは、逆にCRブロック要求に対して追加のブロック転送(最大4回まで)が多く発生するということを意味するからです。このような場合には、ロックダウングレードが早く行われるようにすれば、その分の追加ブロック転送がなくなるため、パフォーマンスの向上に役立つことができます。
簡単なテストを介して_FAIRNESS_THRESHOLDパラメータによって、グローバルキャッシュの同期がどのように行われることを確認してみましょう。gc cr block2-wayイベントが5番目の要求でgc current block2-wayイベントに変わり、6番目の要求から、グローバルキャッシュの同期が発生していないことに留意して、テストの結果を分析してみましょう。
RACシステムで「Currentモードで読むことができるバージョンのブロック」の正確な意味は、「排他モード(Exclusive Mode)でBLロックを獲得したブロック」のことです。つまり、ローカルバッファキャッシュにBLロックを排他モードで獲得したブロックが存在する場合には、グローバルキャッシュの同期作業をせず、ローカルバッファキャッシュから直接ブロックを読み込みます。リクエストノードのユーザプロセスが現在のモードのブロック転送を要求された後、データブロックの排他モードでBLロックを獲得する場合は、次のとおりです。
排他モードのCurrentブロックをCurrentモードで送信する場合(これを一般的にWrite-Write競合と呼ぶ)には、常にPIブロックが生成されます。したがって、クラスタ内一つのブロックのPIブロックが複数の存在することができます。 PIブロックは、ローカルインスタンスレベルの排他モードのCurrentブロックとすることができます。たとえば、クラスタ全体のレベルでは、一つだけの排他モードのCurrentブロックが存在しますが、各インスタンス・レベルで個々のCurrentブロック(PIブロック)を持っているというわけです。この場合、クラスタ全体のレベルのCurrentブロックだけがディスクに書き込まれるメカニズムが保障されなければなりません。特定のインスタンスでダーティバッファを記録する必要が生じた場合に、自分が直接記録することなく、マスターノードにクラスタ全体のレベルでのCurrentブロックを記録することを要求します。マスターノードは、GRDを介してホルダノードにディスクの記録を要求し、ディスクの記録が成功した場合、他のすべてのインスタンスにPIブロックをバッファ・キャッシュから解除することを知らせます。このような一連の過程をFusion Writeと呼びます。 OracleはFusion Writeを通じて1つの最新のブロックだけがディスクに書き込まれることを保証して、不必要なPIブロックをメモリから解放する方法を提供します。 V$SYSSTATビューを使用してDBWRプロセスによるディスク書き込み中Fusion Writeがどのように多くの比重を占めているかを確認することができます。
1)一貫性のある読み取りモード要求に対して現在のモードのブロックを転送する場合
ホルダーノードがCurrentブロックをローカルキャッシュに持っている状況では、他のノードが_FAIRNESS_THRESHOLDパラメータ値(4)を超えてCRモードでブロックを要求された場合には、CRモードではなくCurrentモードのブロックイメージが送信されます。この場合、要求ノードは、gc cr block2-way/3-wayイベントではなく、gc current block2-way/3-wayイベントをFixed-upイベントとして使用します。また、リクエストノードでは、gc current blocks received、gc current receive time統計値が増加し、ホルダーのノードでgc current blocks served、gc current block pin time、gc current block flush time、gc current block send time統計値が増加します。
2)現在のモードのブロック要求に対して一貫性のある読み取りモードのブロックを転送する場合
UpdateステートメントなどDML実行では、Currentブロックを要求する。ホルダーのノードですでに変更されたブロックが送信される場合には、さらに、UNDOセグメントヘッダブロックと、UNDOブロックの情報を一貫性のある読み取りモードで送信なければなりません。なぜなら、これらのブロックにトランザクション情報が管理されるからでです。
DML実行後、過度に長時間のコミットを実行しない場合、UNDOセグメントヘッダブロックやUNDOブロックのCRバージョンが送信されるべきなので、余計なインターコネクト競合を引き起こす可能性があるという事実を忘れてはなりません。特定のノードの長時間のトランザクションを実行する途中で、他のノードからのDMLを実行すると、UNDO情報を参照するための追加のブロック転送が行われ、gc cr block2/3-wayイベント待ちが観察されます。
簡単なテストでは、DML実行時にCRブロック転送が行われることを確認することができます。
待機パラメータと待機時間
待機パラメータ
gc cr block2-wayのイベントなどのFixed-upイベントは、P1、P2、P3の値が別途付与されず、Placeholderイベント(ここではgc cr requestイベント)と同じ値を持つものと解釈すればよいです。
待機時間
--
チェックポイントとソリューション
gc cr/ current requestの#Check Point&Solutionを参照ください。
豆知識
2-wayと3-wayの違い
2つのノードで構成されるRAC環境では、最大2回(2-way)の通信が行われます。しかし、三つ以上のノードで構成されRAC環境では、最大3回(3-way)までの通信が行われます。3回の通信を介して、ブロックイメーがを送信された場合には、gc cr/current block3-wayイベントをFixed-upイベントとして使用します。3-way通信は、クラスタ環境では、必然的に発生し、この現象自体をチューニングするための努力は無意味です。しかし、3-way通信が過度に多いということは、マスターノードが間違って割り当てられていることを示唆することもできます。オラクル10g R2からセグメントレベルのダイナミックリマスタリングがサポートされるので、誤ったマスターノードの指定による不必要な相互接続通信が自然的に減少します。2-way通信と3-way通信の違いを図で表すと以下の通りです。
gc cr blocks served
他のインスタンスのCRブロック要求のために送信(Send/ Serve)されたブロックの数を意味します。名前とは異なり、この統計値が送信された「CRブロックの数」だけを意味するものではないことに注意する必要があります。CRブロック要求に対してCurrentブロックを送信する場合もあるからです。
gc cr blocks serverd統計値は、常にgc cr block build time、gc cr block flush time、gc cr block send time統計値と一緒に分析しなければなりません。CRブロックを送信するプロセスは、CRブロック構成(Build)、CRブロックのREDOフラッシュ(Flush)とCRブロック転送(Send)を含んでいるからです。
gc cr blocks served
他のインスタンスのCRブロック要求のために送信(Send/ Serve)されたブロックの数を意味します。名前とは異なり、この統計値が送信された「CRブロックの数」だけを意味するものではないことに注意する必要があります。CRブロック要求に対してCurrentブロックを送信する場合もあるからです。
gc cr blocks serverd統計値は、常にgc cr block build time、gc cr block flush time、gc cr block send time統計値と一緒に分析しなければなりません。CRブロックを送信するプロセスは、CRブロック構成(Build)、CRブロックのREDOフラッシュ(Flush)とCRブロック転送(Send)を含んでいるからです。
gc cr block build time
他のインスタンスのCRブロック要求のためにCRブロックを送信するためにCRブロックを構成(Build)にかかった時間を意味します。単位は1/100秒(cs)です。 CRブロックの構成(Build)は、バッファキャッシュからCRブロックを探索する時間と、バッファ・キャッシュにCRブロックが存在しない場合に、ディスクからCRコピー(Copy)を生成する時間を含んでいます。一般的に、CRコピーを作成する作業は、ディスクからアンドゥイメージを読み込み、アンドゥ画像からCRブロックを生成する作業を含んでいます。この作業は、LMSプロセスに大きな負荷を引き起こす可能性がありますので、Oracleは、要求されたSCNと最も近いブロックからCRブロックを生成します(このプロセスをCRコピーと呼ばれます)。つまり、ディスクからUNDOイメージを反映せず、不完全なイメージのCRブロックを生成した後、送信します。不完全なCRブロックを送信されたリクエストノードのプロセスが直接、UNDOを実行して、完全なイメージのCRブロックを生成します。これをLight Weight Ruleと呼びます。 CRブロックを構成(Build)する作業は、メモリのナビゲーションとメモリコピー操作を含んでいるため、CPUのリソースを多く必要とし、この一連の作業をLMSプロセスが担当します。もしCRブロック構成に多くの時間がかかる場合LMSプロセスの性能の点検が必要であります。
gc cr block flush time
他のインスタンスのCRブロック要求のためにCurrentブロックを送信する過程で、REDOフラッシュ(Redo Flush)にかかった時間を意味します。単位は1/100秒(cs)です。Oracleは、要求されたCRブロックのCurrentイメージに満足できる場合には、CRコピー処理を実行せずCurrentブロックを直接送信します。もしCurrentブロックが現在ダーティ(Dirty)の状態であれば、REDOログに変更履歴を記録した後、送信する必要があります。もし、REDOフラッシュに多くの時間がかかる場合LGWRプロセスの性能やREDOログ・ファイルのI / Oパフォーマンスのチェックが必要です。gcs log flush sysnc待機イベントとgc cr block busy待機イベントと関連付けて分析すると、より正確な診断を下すことができます。
gc cr block send time
他のインスタンスのCRブロック要求のためにブロックを転送する過程で、ネットワーク転送(Send)にかかった時間を意味します。単位は1/100秒(cs)です。この値の意味を正確に理解するには、ブロック転送プロセスがバッファキャッシュ層とネットワーク層の2つの層によって達成されるという事実を理解する必要があります。バッファキャッシュ層から始まったブロック転送要求は、次のような過程を経て、物理的な転送が行われます。
他のインスタンスのCRブロック要求のためにCRブロックを送信するためにCRブロックを構成(Build)にかかった時間を意味します。単位は1/100秒(cs)です。 CRブロックの構成(Build)は、バッファキャッシュからCRブロックを探索する時間と、バッファ・キャッシュにCRブロックが存在しない場合に、ディスクからCRコピー(Copy)を生成する時間を含んでいます。一般的に、CRコピーを作成する作業は、ディスクからアンドゥイメージを読み込み、アンドゥ画像からCRブロックを生成する作業を含んでいます。この作業は、LMSプロセスに大きな負荷を引き起こす可能性がありますので、Oracleは、要求されたSCNと最も近いブロックからCRブロックを生成します(このプロセスをCRコピーと呼ばれます)。つまり、ディスクからUNDOイメージを反映せず、不完全なイメージのCRブロックを生成した後、送信します。不完全なCRブロックを送信されたリクエストノードのプロセスが直接、UNDOを実行して、完全なイメージのCRブロックを生成します。これをLight Weight Ruleと呼びます。 CRブロックを構成(Build)する作業は、メモリのナビゲーションとメモリコピー操作を含んでいるため、CPUのリソースを多く必要とし、この一連の作業をLMSプロセスが担当します。もしCRブロック構成に多くの時間がかかる場合LMSプロセスの性能の点検が必要であります。
gc cr block flush time
他のインスタンスのCRブロック要求のためにCurrentブロックを送信する過程で、REDOフラッシュ(Redo Flush)にかかった時間を意味します。単位は1/100秒(cs)です。Oracleは、要求されたCRブロックのCurrentイメージに満足できる場合には、CRコピー処理を実行せずCurrentブロックを直接送信します。もしCurrentブロックが現在ダーティ(Dirty)の状態であれば、REDOログに変更履歴を記録した後、送信する必要があります。もし、REDOフラッシュに多くの時間がかかる場合LGWRプロセスの性能やREDOログ・ファイルのI / Oパフォーマンスのチェックが必要です。gcs log flush sysnc待機イベントとgc cr block busy待機イベントと関連付けて分析すると、より正確な診断を下すことができます。
gc cr block send time
他のインスタンスのCRブロック要求のためにブロックを転送する過程で、ネットワーク転送(Send)にかかった時間を意味します。単位は1/100秒(cs)です。この値の意味を正確に理解するには、ブロック転送プロセスがバッファキャッシュ層とネットワーク層の2つの層によって達成されるという事実を理解する必要があります。バッファキャッシュ層から始まったブロック転送要求は、次のような過程を経て、物理的な転送が行われます。
つまりgc cr block send time統計値は、実際のブロック転送にかかった時間ではなく、ネットワーク層にブロック転送要求をした後に応答を受け取るまでにかかった時間を意味します。一般的に、OSレベルでのネットワーク転送要求は非常に速い速度で行われるため、gc cr block send time統計値の占める割合は高くはありません。もしgc cr block send time統計値が、他の統計値と比較して高い割合を占めている場合、ネットワーク設定やネットワークドライブ、ハードウェアの設定などに問題があることを点検してみる必要があります。
gc current blocks served
他のインスタンスのCurrentブロック要求のために送信(Send。Serve)されたブロックの数を意味します。
gc current blocks serverd統計値は、常にgc current block pin time、gc current block flush time、gc current block send time統計値と一緒に分析しなければなりません。Currentブロックを送信するプロセスは、Currentブロックのロック獲得(Pin)、CurrentブロックのREDOフラッシュ(Flush)とCurrentブロック転送(Send)を含んでいるからです。
gc current block pin time
他のインスタンスのCurrentブロック転送要求を処理するためにCurrentブロックのロックを獲得するのにかかった時間を意味します。単位は1/100秒(cs)です。ロックを獲得する作業を、通常のピン(Pin)と呼ばれることから始まった名前です。ロック獲得の過程で時間がかかる理由は大きく二つがあります。
gc current block pin time統計値が占める割合が高すぎる場合には、ホット・ブロックの存在するかどうかを確認しなければならず、ブロックの競合が過度に頻繁に発生していないか点検して見なければならりません。 buffer busy waits待機イベントとgc current block busy待機イベントと連携して分析すると、より正確な診断を下すことができます。また、V $ CURRENT_BLOCK_SERVERビューを活用すれば、Currentブロックのロック獲得のパフォーマンスの問題をより細かく分析することができます。
gc current block flush time
他のインスタンスのCurrentブロック要求のためにCurrentブロックを送信する過程で、REDOフラッシュ(Redo Flush)にかかった時間を意味します。単位は1/100秒(cs)です。送信対象Currentブロックが現在ダーティ(Dirty)の状態であれば、REDOログに変更履歴を記録した後、送信する必要があります。もし、REDOフラッシュに多くの時間がかかる場合LGWRプロセスの性能やREDOログ・ファイルのI / Oパフォーマンスのチェックが必要です。gcs log flush sync待機イベントとgc current block busy待機イベントと関連付けて分析すると、より正確な診断を下すことができます。また、V$ CURRENT_BLOCK_SERVERビューを参照するとCurrentブロックの、REDOフラッシュのパフォーマンスの問題をより細かく分析することができます。
gc current clock send time
他のインスタンスのCurrentブロック要求のためにブロックを転送する過程で、ネットワーク転送(Send)にかかった時間を意味します。単位は1/100秒(cs)です。
gc cr blocks received
別のインスタンスにCRブロック転送を要求した後、受信したブロックの数を意味します。 gc cr blocks received統計値はgc cr blocks served統計値と一対一の関係を持ちます。もし2つのインスタンスからなるRACシステムであれば、次のような関係を持地ます。
[1回インスタンスのgc cr blocks received≈2回インスタンスのgc cr blocks served] gc cr blocks served統計値で説明したようにCRブロック転送の過程でLight Weight Ruleが適用された場合には、不完全なバージョンのCRブロックを送信されます。この場合は、要求のインスタンスでCRブロック構成作業を終えことになります。特にリモート・インスタンスで頻繁ブロックの変更が発生した場合Light Weight Ruleがよく適用されることになります。不完全なCRブロックを送信されたリクエストのインスタンスは、CRブロックを完成するために、ディスクからのUNDOイメージを読み取り、UNDOセグメントヘッダブロックの情報を再リモート・インスタンスから送信される一連の追加の作業を行う必要があります。 Light Weight RuleはホルダーインスタンスのLMSプロセスの負荷を減らす代わりに、その負担を求めるのインスタンスのサーバープロセスが分け持つことを理解することができます。
gc cr block receive time
別のインスタンスにCRブロック転送を要求した後送信されるまでにかかった時間を意味します。単位は1/100秒(cs)です。 gc cr block receive time統計値はgc cr block build time、gc cr block flush time、gc cr block send time統計値に実際のネットワーク送受信に消費された時間を合わせた値に理解すれば良いです。もし2つのインスタンスからなるRACシステムであれば、次のような関係を持ちます。
[1回インスタンスのgc cr block receive time = 2回インスタンスのgc cr block build time + gc cr block flush time + gc cr block send time +転送要求を転送にかかった時間+要求に対する応答を伝達するにかかった時間]
もしネットワーク転送のパフォーマンスが遅い場合、要求のインスタンスは、実際のブロックを受信するまでの時間がホルダーインスタンスが送信にかかった時間に比べて非常に高く出てくることがあります。したがって、このような場合には、ネットワークのパフォーマンスを点検しなければなりません。
gc current blocks received
別のインスタンスにCurrentブロック転送を要求した後、受信したブロックの数を意味します。gc current blocks received統計値はgc current blocks served統計値と一対一の関係を持ちます。もし2つのインスタンスからなるRACシステムであれば、次のような関係を持ちます。
[1回インスタンスのgc current blocks received≈2回インスタンスのgc current blocks served]
gc current block receive time
別のインスタンスにCurrentブロック転送を要求した後送信されるまでにかかった時間を意味します。単位は1/100秒(cs)です。 gc current block receive time統計値はgc current block build time、gc current block flush time、gc current block send time統計値に実際のネットワーク送受信に消費された時間を合わせた値に理解すればよいのです。もし2つのインスタンスからなるRACシステムであれば、次のような関係を持ちます。
[1回インスタンスのgc current block receive time = 2回インスタンスのgc current block pin time + gc current block flush time + gc current block send time +転送要求を転送にかかった時間+要求に対する応答を伝達するにかかった時間]
もしネットワーク転送のパフォーマンスが遅い場合、要求のインスタンスは、実際のブロックを受信するまでの時間がホルダーインスタンスが送信にかかった時間に比べて非常に高く出てくることができます。したがって、このような場合には、ネットワークのパフォーマンスを点検しなければなりません。
gc blocks lost
ブロック転送の過程で失わ(Lost)されたブロックの数を意味します。ブロックの損失は、RACシステムの性能に決定的な影響を与えるのでgc blocks lost統計値は、可能な低い数値を維持しなければなりません。もしgc blocks lost統計値が増加すれば、次のような確認手続きを経なければなりません。
ネットワーク設定やハードウェアの設定に異常はないかを点検します。 netstatのようなツールを利用して、ネットワークパケットにエラーが発生していないことを確認して、ネットワークパラメータが過度に小さく設定されていないことを確認します。ネットワークバッファサイズを大きくして、MTUのサイズを大きくすることなども解決方法になることができます。
誤ったネットワークプロトコルを使用していないかを点検します。ほとんどのOSで、Oracleは、UDPをデフォルトのプロトコルとして使用することをお勧めします。多くの種類のプロトコルに対してRACパフォーマンステストと適用が行われましたが、UDPで最も安定して動作することが経験的に検証されました。もし特定のベンダーが提供する特定のプロトコルを使用する場合は、必ず、Oracleから検証を経なければならりません。
過度インターコネクト負荷が高い場合には、パケットの損失は避けられません。この場合には、ネットワーク帯域幅を高めたりSQL /アプリケーションのチューニングを介してブロック転送数を減らさなければなりません。
blocks corrupt
ブロック転送中に破損(Corrupt)が発生したブロック数を意味します。ブロックの破損かどうかはチェックサム(Checksum)の値を使用して確認します。ブロックの破損は、RACシステムの性能に決定的な影響を与えるのでblocks corrupt系の値は、可能な低い数値を維持しなければなりません。ブロックの破損は、RAC自体の問題というよりは、ほとんどより下部の層、すなわち、ネットワークの設定やハードウェアの設定によって発生する問題でなければなりません。もしgc blocks corrupt統計値が増加すれば、非現実的なネットワークパラメータやハードウェアの設定がないか点検しなければなりません。
gc CPU used by this session
グローバルキャッシュの同期処理に使用したCPU時間を意味します。単位は1/100秒(cs)です。この値を全体的なCPU使用時間と比較すると、グローバルキャッシュの同期作業にどのくらいのCPUリソースを使用していることを推測することができます。Oracleは統計値(Stats)で提供するCPU使用時間は、合計4つに次の通りです。
上記の値を比較して、特定のタスクのCPUリソースが全体的なCPU使用時間比どれくらい使用されるかを確認することができます。

