
PostgreSQL Architecture - 3. Logical Structure
Logical Structure
前回のPhysical Structureを通じて領域およびファイルの観点からのPostgreSQLの構成要素を確認しました。 本稿では、ユーザの立場から実際の管理対象であるObject、Schema、Database、Tablespace、およびClusterについて説明します。
下図は、PostgreSQLの論理構造(Logical Structure)を図式化したもので、最も下位の概念である「Object」から、最上位の「Cluster」まで、順を追って理解していきましょう 。
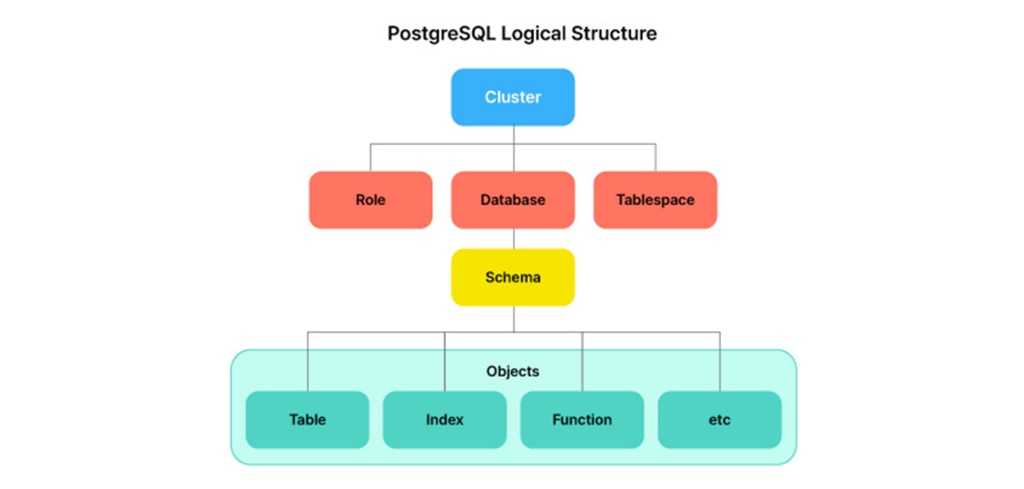
Object
Objectとは、データを保存したり参照したりするのに使用されるデータ構造のことです。 私たちがよく知っているテーブル(Table)、インデックス(Index)、プロシージャ(Stored Procedure)、シーケンス(Sequence)、ビュー(View)などがここに含まれます。 以下の表ではOracleで主に使用されるObjectと比較しています。
オブジェクトタイプ (OBJECT TYPE) |
対応状況 |
特記事項 |
|---|---|---|
FUNCTION |
Oracle, PostgreSQL |
|
INDEX |
Oracle, PostgreSQL |
PG: BRIN、GIN、GIST、SP-GISTインデックス対応 |
INDEX PARTITION |
Oracle, PostgreSQL |
バージョン11からlocal partition対応 |
JOB |
Oracle |
PGではExtensionとして使用可能(pg_cron、pgAgent) |
MATERIALIZED VIEW |
Oracle, PostgreSQL |
|
PACKAGE |
Oracle |
PGではFunctionで代替可能 |
PACKAGE BODY |
Oracle |
PGではFunctionで代替可能 |
PROCEDURE |
Oracle |
PGではFunctionで代替可能 |
SCHEDULE |
Oracle |
PGではExtensionとして使用可能 |
SEQUENCE |
Oracle, PostgreSQL |
PGではExtensionとして使用可能(pg_cron、pgAgent) |
SYNONYM |
Oracle, PostgreSQL |
PGではNOCACHEオプション未対応 |
TABLE |
Oracle, PostgreSQL |
|
TABLE PARTITION |
Oracle, PostgreSQL |
バージョン10から対応 |
TRIGGER |
Oracle, PostgreSQL |
PGではFunctionで代替可能 |
TYPE |
Oracle, PostgreSQL |
PGではFunctionで代替可能 |
VIEW |
Oracle, PostgreSQL |
|
XML |
Oracle, PostgreSQL |
Schema
PostgreSQLにおいて、Schemaとは様々なObjectの集合を意味します。 一つのDatabaseは多数のSchemaを持つことができ、その中でもPublic SchemaはCREATE権限を含むすべての権限が付与された基本Schemaです。
Schemaは以下のような特徴を持っています。
- Schema Ownerは必要に応じてSchemaに対するAccessを制御することができます。
- 所有権は譲渡できます。
- Schemaごとに同じ名前のObject(テーブル、関数など)が存在することがあります。
📌Oracleに慣れている人には少し馴染みの薄い概念かもしれません。 Oracleの場合、SchemaとOwnerが合わさった形で使用されるため、Owner=Schemaと認識されるからです。
しかし、PostgreSQLで言うSchemaとは、Role、User、Ownerなどユーザーアカウントとは関係のない単純なObjectの集合を意味します。Database
PostgreSQLにおけるDatabaseは、複数のSchemaの集合を意味します。 他のDBMSと違って、PostgreSQLはDatabaseとSchemaを明確に区別します。 そのため、User(Owner)とSchemaが同じ意味を持つOracleとは異なり、PostgreSQLではDatabase→Schemaの順に接続し、該当SchemaにObjectを構成しなければなりません。
特徴
- PostgreSQL初期化(initDB)時、template0、template1、postgresという3つのDatabaseが生成されます。 template0とtemplate1 Databaseは、ユーザDatabaseを生成するためのテンプレートDatabaseであり、System Catalogテーブルが含まれています。
- template0とtemplate1 Databaseのテーブルリストは、initDBの直後は同じです。 しかし、template1 Databaseは必要に応じてユーザーがObjectを作成することができます。
- Databaseを作成する際、特定の
templateオプションを使用しない限り、template1 Databaseを複製元として作成されます。📌 template1 Database : Database 生成時に参照される基本Database template0 Datebase:template1に問題が発生したときに使用されるDatabase
Role
Roleとは、PostgreSQLで提供されるDatabase関連の権限を名前つきの単位でまとめたものです。バージョン8.0まではUserとGroupによるアカウントおよび権限管理をしていましたが、バージョン8.1からはUserとGroupの概念がRoleに統合されました。
つまり、現在のバージョンでは、以下の例のようにUserとRoleの機能的な違いはなく、RoleにLOGIN権限を付与すれば、一般ユーザーアカウントのように機能します。
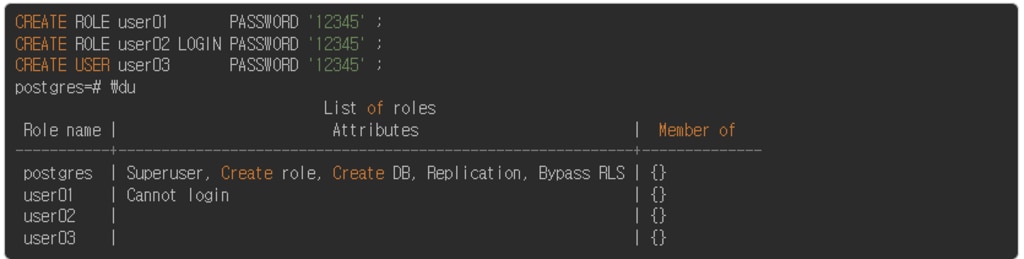
📌 PostgreSQL 8.1 Document 内容のうちCREATE USER 部分
CREATE USER はデータベース Role を定義する新しいコマンドで、現在(PostgreSQL 8.1 以上)はCREATE ROLE の別名として扱われます。 2つの違いは、CREATE USERにはLogin オプションが含まれており、CREATE ROLEにはLogin オプションが含まれていないところです。
PostgreSQL 8.1 Document内容のうちCREATE GROUP部分
CREATE GROUP はデータベースRole を定義する新しいコマンドで、現在(PostgreSQL 8.1 以上)はこちらもCREATE ROLE の別名として扱われます。特徴
• Roleは個別のDatabaseではなく、Clusterレベルで共通して利用されます。
• RoleはObject(テーブル、関数など)を所有することができ、Objectに対する権限管理が行えます。
• Roleを削除する際、Roleが所有するObjectに対する処理(削除またはownerの変更)を先に行う必要があります。
• Role権限の種類は以下の通りです。
ロールタイプ |
説明 |
|---|---|
SUPERUSER |
LOGINロールを除くすべてのロールを含む |
LOGIN |
データベースに接続するためのロール |
CREATEDB |
データベースを作成するためのロール |
CREATEROLE |
ロールを作成、修正、削除、変更するためのロール |
REPLICATION |
レプリケーションを使用するためのロール |
PASSWORD |
パスワードの設定 |
CONNECTION LIMIT |
接続数の設定 |
INHERIT |
ロールに対応する権限を継承 |
BYPASSRLS |
Row Security Systemを回避するロール |
Tablespace
Tablespaceとは、Object(テーブル、インデックスなど)が保存されるファイルシステムの位置を定義したものを意味し、一般的にディスク空間管理の目的として利用されます。 また、PostgreSQLのTablespaceはOracleとは異なり、複数のDatabaseが一緒に使用することができます。
PostgreSQLには基本的に以下のような2つのDefault Tablespaceが存在します。
- pg_default:すべてのユーザーのデータを保存 (位置:$PGDATA/base)
- pg_global : すべてのGlobal データ(Cluster)を保存 (位置:$PGDATA/global)
📌 テーブルスペースディレクトリ構造はPhysical Structureを参照してください。上記のようなDefault Tablespace以外にユーザーTablespaceも作成可能ですが、作成時にOWNER情報とLOCATION情報を記述することにより、Tablespaceの実データはLOCATIONで指定したパスに保存され、$PGDATA/tblspcパスにはLOCATIONを指すシンボリックリンクが生成されます。

特徴
- Tablespaceを生成するユーザ(Role)がTablespaceの所有者(Owner)となります。
- Tablespaceを作成する際、
OWNER句に名前を指定して所有権を指定することができます。 - Tablespaceを作成する際、
LOCATION句に定義されたパスが実際のデータを保存するディレクトリになります。該当ファイルシステムはPostgreSQLのシステムユーザー(OSUser)が所有しなければなりません。 (読み書き権限) - Objectの使用パターンによって保存領域を変えて性能を最適化することができます。 一例として、よく使用されるObjectはSSDのような速いDiskにTablespaceを構成し、使用頻度の低いObjectはより遅いDiskにTablespaceを構成、配置することができます。
📌 一つのTablespaceは、一つのファイルシステム上のディレクトリで構成されます。
一方、1つのファイルシステムには複数のTablespaceを構成することができます。 注意事項
- Tablespaceは、データディレクトリに含まれるメタデータに従属するため、他のDatabase Clusterに接続して使用したり、個別にバックアップすることはできません。
- Tablespaceの障害(ファイル削除、ディスク障害)が発生すると、Database Cluster全体が動作しなくなります。
Cluster
PostgreSQLでClusterとは、複数のDatabaseとRole、Tablespaceの集合を意味します。 Cluster内部には、互いに隔離されている複数のDatabaseが存在します。 最初にPostgreSQLをインストールすると、基本的にpostgres、template0、template1 Databaseが生成されますが、これらのDatabase集合体をClusterと呼びます。
- Objectの集合 → Schema
- Schemaの集合 → Database
- Databaseの集合 + Role + Tablespace → Cluster
📌OracleにおいてはClusterはRAC環境の共有ノードの概念であり、一つのストレージを参照する複数のノード、Oracle Grid Instructure(Clusterware Software)を通じたActive-Active環境を造成し、Clusterwareを通じて構成された共有ノードをClusterといいます。


