
Oracle SQLチューニング Season2(第7回)第2章 SQLチューニング対象選定方法(4/8)
SQLチューニング対象の選定方法 の4回目は(Case別)SQLチューニング対象の選定方法 の1回目 です。
「Case1. IO / CPU Top SQL関連性能の改善対象選定」について解説していきます。
それでは早速スタートしましょう!!
2.3 Case別SQLチューニング対象選定方法
前回までのテーマでは、SQLチューニング対象選択の重要性と対象を選定するために活用ができるツールについて説明して来ました。ここからは、先に説明したDictionary Viewを使って、実際にスクリプトを作成していきます。
そして、CASE別チューニング対象選定作業を進めながら、読者の皆さんの理解を助けていきたいと思います。
2.3.1 Case1. IO / CPU Top SQL関連性能改善対象選定
■ ターゲット抽出スクリプト
Top SQLを抽出するための基準となる基本要素は、I/O発生量とCPU使用率です。
なぜならば、DBサーバーの性能問題を引き起こす要因ともなり得るからです。
I/O発生量とCPU使用率はV$SQLAREA、DBA_HIST_SQLSTATビューを照会する下記のようなスクリプトを作成して、その性能指標に関連するSQLを抽出することができます。
上記の内容の中でDBA_HIST_SQLSTATを利用したスクリプトは、特定期間に実行したSQL実行履歴を抽出したい場合によく使われます。
例えば、業務担当者から以下のような依頼を受けたとした場合に使用できるスクリプトです。
” 昨夜9時から今朝9時まで実行されたSQLのうち、CPU使用率が最も高いリストを抽出する ”
CPU使用率ではなく、I/O使用率や実行時間(Elapsed Time)を抽出したい場合には、ORDER BY節の内容だけクエリを変更することで必要となるリストを抽出することができます。
■ 活用例
PROD DBシステムのCPU使用率の推移は以下の通りです。
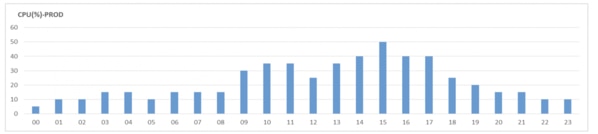
「 図2.3.1-1 」PROD CPU使用率の時間別推移(3月23日)
[ 図2.3.1-1 ]は、当該システムの特定日のCPU使用率推移で、常に時間別CPU使用率は最大50%未満で推移しており、安定して運用されていることがわかります。
ところが突然、[図2.3.1-2]のようにCPU使用率が大幅に高く検出されてしまいました。
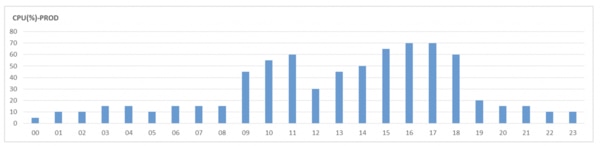
「 図2.3.1-2 」PROD CPU使用率の時間別推移(3月24日)
このような状況においては、先に紹介したDBA_HIST_SQLSTATビューを使ったスクリプトを活用することで、CPU使用率が高くなった原因を分析することができます。
先に紹介したスクリプトで普段のCPU使用率を維持する時のSQLリストとCPU使用率が高くなった時のSQLリストを比較すると、どのプログラム(SQL)によって発生したのかを分析することができます。
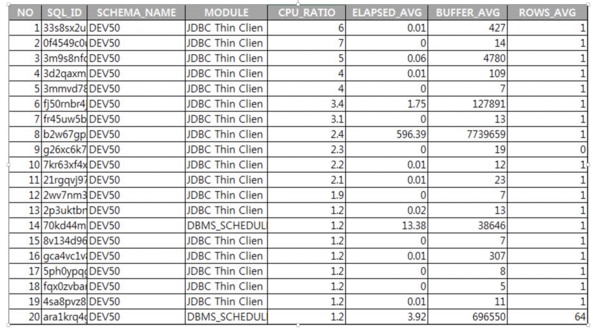
「 表2.3.1-1 」PRODシステムのTop SQL List(3月23日)
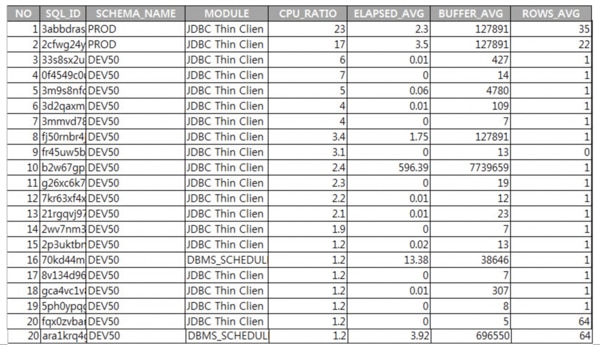
「 表2.3.1-2 」PRODシステムのTop SQL List(3月24日)
3月23日に比べて3月24日のCPU使用率が高かったのは、PRODで実行されたTop SQL1,2が過去の時点では実行されなかったことが明確な原因であるということが分かりました。
つまり、新しく追加されたプログラムの実行によりCPU使用率が増加した訳です。
この場合、当該SQLをチューニング対象に選定して改善の余地があるかどうかを点検する必要があります。

次回ブログテーマ
『 Case2. Table Full Scan関連性能改善対象選定 』

