
latch: shared pool - 日本エクセム株式会社 Oracle待機イベント情報
目次[非表示]
- 1.基本情報
- 2.待機パラメータと待機時間
- 3.チェックポイントとソリューション
- 3.1.サブ・プールを使用する
- 3.2.共有プールのサイズを小さくする
- 3.3.共有カーソル機能を使用する
- 4.豆知識
- 4.1.共有プールの構造
- 4.2.ヒープ及びヒープ・ダンプ
- 5.分析事例
- 5.1.ハード解析による性能低下現象分析ケースⅠ
- 5.2.ハード解析による性能低下現象分析ケースⅡ
- 5.2.1.性能低下区間の確認
- 5.2.2.待機イベントの検出および分析
- 5.2.3.待機イベント発生原因の調査
- 5.2.4.セッションおよびSQLの分析
- 5.2.5.結論
- 5.2.6.解決策
基本情報
共有プール・ラッチは共有プールの基本的なメモリー構造であるヒープを保護する役割をします。空きチャンクを探すために空きリストを探索して、適切なチャンクを割り当てて、必要な場合空きチャンクを分割する、という一連の作業は全て共有プール・ラッチを獲得してから可能になります。共有プール・ラッチを獲得する時、競合が発生するとlatch:shared pool待機イベントで待機します。
ヒープと関連した一連の作業は非常に早く完了するので、普通の場合は共有プール・ラッチでの競合は発生しません。しかし、次のような場合には、latch:shared pool待機イベントが増加する可能性があります。
ハード解析が発生すると、新しいSQL情報を入れるチャンクを割当られるために空きリストを探索しなければなりません。このような一連の作業が行われる時、ただ一つのプロセスだけが共有プール・ラッチを占有するため、同時に数多くのセッションがハード解析を実行する場合は、latch: shared pool待機イベントが発生します。
ハード解析が過度に発生するシステムで共有プール・ラッチ待機イベントを減らすために共有プールのサイズを増やすのは非常に危険な発想です。共有プールが大きくなると、それだけの空きリスト数と空きリストで管理しなければならない空きチャンクの数も増えるためです。従って、空きリストを探索するために共有プール・ラッチを獲得する時間が長くなります。それに伴い、latch: shared pool待機イベントの待ち時間も増えていきます。
待機パラメータと待機時間
待機パラメータ
待機時間
待機時間は、指数的に増加します。
チェックポイントとソリューション
サブ・プールを使用する
Oracle9i以降からは、共有プールをいくつかのサブ・プール(最大7個まで)で分けて管理することができます。
_KGHDSIDX_COUNT隠しパラメータを利用すればサブ・プール数を管理することができます。
OracleはCPU数が4以上で、共有プールの大きさが250MB以上の場合、_KGHDSIDX_COUNT値の数だけサブ・プールを生成し、共有プールを管理します。サブ・プールは独立的な共有プールとして管理されており、独自の空きリスト、LRUリスト、共有プール・ラッチを持ちます。従って、共有プールが大きい場合にはサブ・プールを分けて管理することによって共有プール・ラッチ競合を減らすことができます。
共有プールのサイズを小さくする
ハード解析によって共有プール・ラッチ競合が発生する場合、他の解決策としては共有プールのサイズを小さくすることがあります。共有プールの領域が減った分、空きリストの空きチャンク数も減少し、空きリスト探索に所要する時間も短くなるためです。しかし、この方法を使った場合、ORA-4031エラーが発生する可能性が高くなります。また、共有プールにキャッシュできるオブジェクト数が減り、追加のハード解析が多発する可能性があります。
これを解消するためには、DBMS_SHARED_POOL.KEEPプロシージャを利用し、頻繁に使われるSQLカーソルやパッケージ、プロシージャなどを共有プールに永続的にキャッシュさせる方法があります。 DBMS_SHARED_POOL.KEEPで指定したオブジェクトは共有プールに永続にキャッシュされるため、ALTER SYSTEM FLUSH SHARED_POOLコマンドを使っても共有プールからフラッシュされなくなります。
つまり、共有プールを小さくすることと同時にDBMS_SHARED_POOLパッケージを使って、よく利用されるオブジェクトをメモリーにキャッシュするのも一つの方法になります。
共有カーソル機能を使用する
共有カーソル機能は、リテラルを使ったSQL文が自動でバインド変数を使うように置き換えて、カーソルを共有させる機能です。共有カーソル機能は既存のリテラルSQLをバインド変数に変えることができない場合推奨されます。この機能を使う場合、既存SQL文の実行計画が変更される可能性もあるため、十分なテストを行ってから適用することが望ましいです。
豆知識
共有プールの構造
共有プールはSGAのコンポーネントの一つです。 下記のコマンドでSGAのコンポーネントを確認することができます。
共有プールはSGA領域の中で、可変する領域に属します。 可変領域は共有プール、Java プール、ラージ・プール、ストリーム・プールで構成されています。
また、共有プールは様々な種類のメモリー領域に分けられます。代表的なものは、ライブラリ・キャッシュとディクショナリ・キャッシュです。共有プールがどんな領域に分けられているのかはV$SGASTATビューで確認することができます。
共有プールの構成要素は大きく分けて、次のように区分されます。
共有プールはヒープと呼ばれるメモリー管理手法で管理されます。共有プールのヒープからメモリーの割当てを要求する全てのプロセスは必ず共有プール・ラッチを獲得しなければなりません。例えば、ハード解析が発生した場合、プロセスは共有プール内にSQL文を保存するメモリーを割当られるため、必ず共有プール・ラッチを獲得します。 共有プール・ラッチは基本的にインスタンス全体で一つのみ存在しますが、必要なメモリーが割当られるまで保有していなければなりません。従って、同時に多くのプロセスが共有プール・メモリーを使おうとする場合は、ラッチを獲得するための競合が発生します。この競合が発生すると、セッションはlatch:shared pool待機イベントで待機します。
Oracle9i以上からは共有プールをいくつかのサブ・プール(最大7個まで)に分けて管理することができます。_KGHDSIDX_COUNT隠しパラメータを利用すればサブ・プール数を管理することができます。 OracleはCPU数が4以上で、共有プールの大きさが250MB以上の場合、_KGHDSIDX_COUNT値の数だけサブ・プールを作って共有プールを管理します。 サブ・プールは独自の共有プールで管理されており、独自の空きリスト、LRUリスト、共有プール・ラッチを持ちます。 従って、共有プールが大きい場合には、サブ・プールに分けて管理することをお勧めします。こうすることで共有プール・ラッチ競合を減らすことができます。
ヒープ及びヒープ・ダンプ
ヒープに対する基本的な項目を整理してみます。
ヒープ・ダンプを取ってみると、ヒープの構造を確認することができます。
下記のコマンドを実行し、USER_DUMP_DESTにヒープ領域に関するダンプ・ファイルを確認します。
次は、結果ファイルの内容です。
上記のようにヒープ・ダンプを取ることによって、ヒープの正確な構造情報を得ることができます。各ヒープはまたサブ・ヒープ構造を持ちます。 ヒープは自分が保持している特定のチャンクにサブ・ヒープのアドレスを保存してサブ・ヒープの位置を管理します。
ヒープ・ダンプで分かるように、次のような”ds”値が設定されているチャンクがサブ・ヒープの位置を保存しているチャンクです。
ds値はヒープ・ディスクリプタという意味であり、ds=c0000000993293e8がサブ・ヒープのアドレスを示します。
下記のコマンドで、該当サブ・ヒープのダンプを取ることができます。
下記のサブ・ヒープのダンプ内容を確認すると、ヒープ・ダンプとほとんど同じ形式を持っていることが分かります。エクステントの大きさが変動する点と、予約空きリストを管理しないという点を除けば、サブ・ヒープは最上位のヒープと同じ構造を持ちます。
分析事例
ハード解析による性能低下現象分析ケースⅠ
アプリケーションをMaxGaugeで監視した結果ですが、ハード解析によりlatch: shared pool待機イベントが発生していることが確認できます。

下の結果はV$SESSION_EVENTビューとV$SESSTATビューで待機現象と作業量を分析したもので、latch: shared pool待機イベントが最も多く発生していることが確認することができます。また、ハード解析の回数が全体解析の回数と同じ数値になるほどハード解析が頻繁に発生していることも確認できます。
実行結果 |
Type=EVENT, Name=latch: shared pool, Value=112(cs) Type=EVENT, Name=latch: library cache, Value=72(cs) |
共有カーソル機能を使用することによってハード解析を避けることができます。
下記のようなコマンドでCURSOR_SHARINGパラメータ値をFORCEに変更すると、全てのリテラルSQLを自動で共有可能なSQLに変換することができます。
下の結果は共有カーソルを設定した後の性能測定結果です。 latch: shared pool待機イベントが解消されており、ハード解析の回数が大きく減少したことが確認できます。
実行結果 |
Type=EVENT, Name=events in waitclass Other, Value=6(cs) |
ハード解析による性能低下現象分析ケースⅡ
同時ユーザーが多いOLTPおよびWEB環境で、過剰なリテラルSQLの使用は、性能上の深刻な問題を引き起こす場合が多いです。MaxGaugeを活用して、リテラルSQLの過度な使用による性能低下問題の原因を解析してみます。
性能低下区間の確認
性能問題が発生したインスタンスで収集された稼動ログから推移グラフを確認すると、「CPU」使用率には明確な変化が見えませんが、10時17分をピークに「Active Session」および「Wait Events」が急増していることを簡単に確認できます。
■「CPU」使用率の推移グラフ

■「Active Session」数の推移グラフ

■「Wait Events」の推移グラフ(待機時間)

待機イベントの検出および分析
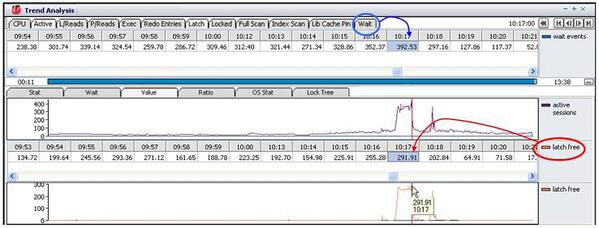
アクティブ・セッションの急増によるスローダウンの原因を究明するため、問題時点(10時17分)の待機イベントの発生内容を確認してみます。MaxGaugeの「Stat/Wait」で同じ時点のトップ待機イベントを確認した結果、アイドル・イベント(SQL*Net message from client)以外のトップ待機イベントはlatch freeであることが分かりました。
下図では、アクティブ・セッションの急増とlatch free待機イベントの関連性を確認するために、発生パターンを比較してみました。その結果、latch free待機イベントは「Active Session」の推移と非常に似ていることが分かります。
また、latch free待機イベントは、問題が発生した時点の待機時間の約74%(全体392.53秒中、291.91秒)を占めています。このようなパターンの比較によって、アクティブ・セッションの急増は、latch free待機イベントの急激な発生と関連しているとのことが考えられます。
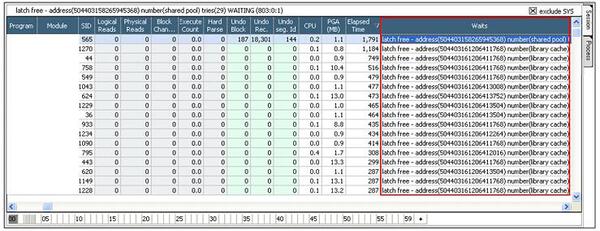
実際、同じ時点の詳細データである「セッション・リスト」でも、latch free待機イベントがトップ待機イベントになっており、その中でもlatch free (shared pool) およびlatch free (library cache) 待機イベントが多く発生していることが確認できます。
待機イベント発生原因の調査
latch free待機イベントの発生原因は様々ですが、一般的にlatch free (shared pool)とlatch free (library cache)待機イベントが同時に発生した場合は、ハード解析がその原因である可能性が高いです。その根拠を確認するため、parse count (hard)、parse time cpu、parse time elapsed統計値の推移を確認してみます。
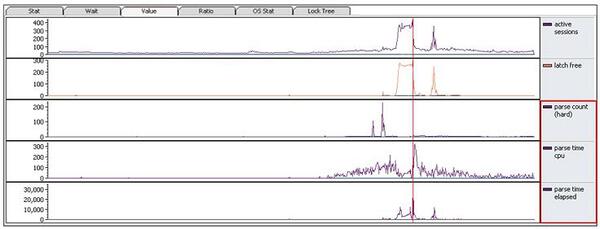
推移グラフの分析結果、アクティブ・セッションが急増した時点で、parse time elapsed統計値が20,000 cs /sec(=200sec/sec)に高まっていて、スローダウン現象が発生するその前(09時26分)のparse count (hard)統計値が200回/秒発生したことが確認できます。
つまり、前の時点の過度なハード解析が共有プールのメモリー断片化を引き起こして、これによってライブラリ・キャッシュでのSQL検索や新規SQLを登録する時に、遅延が発生したと考えられます。
セッションおよびSQLの分析
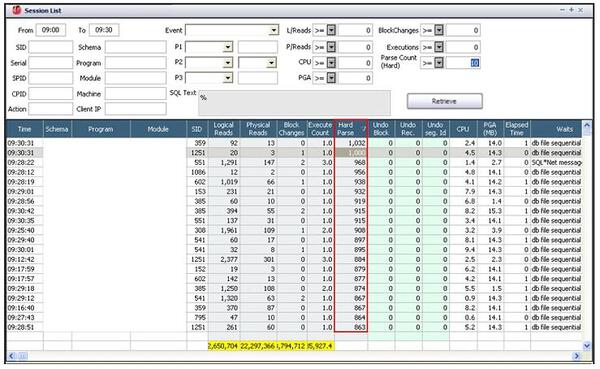
ハード解析の実行が多かった09時00分~ 09時30分間で、parse count (hard)統計値が1秒に10回以上のセッションを検索した結果、1秒に100回以上ハード解析を実行したセッションは、ほとんど「JDBC Thin Client」プログラムであることが確認できます。
過多にハード解析を実行しているセッションは、ほとんどが類似したSQLを使っているにも関わらず、バインド変数を使わずリテラルSQLであることが分かりました。
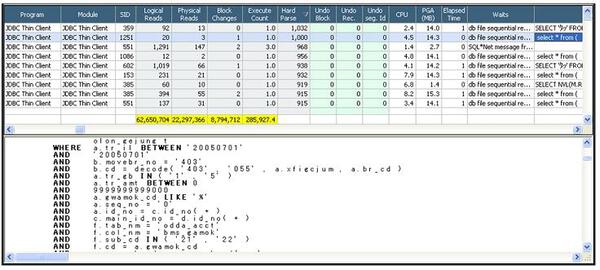
結論
latch free待機イベントの急増によるアクティブ・セッションの急増。
↓
リテラルSQLによるハード解析の過剰な実行がスローダウンの原因。
解決策
- リテラルSQLのバインド変数化
- Prepared Statementを使用することによってJDBC P/G内のリテラルSQLを排除

