

2022.04.22
BLOOM FILTERの理解と活用方法
BLOOM FILTERの理解と活用方法
㈱エクセムコンサルティング本部/DBコンサルティングチーム オスヨン
概要
Bloom Filterとは、1970年度にBurton H. Bloomが考案したもので、コンポーネントが集合のメンバーであることを確認するために使用される確率的データ構造です。
Bloom Filterは2組の要素うち片方は少なく、片方は多い集合において、その積集合の数が少ない場合、優れた性能を示します。
積集合はOracleの結合に対応し、bloom filterは大容量データを結合するときにさらに効果的です。
オラクルはますます大容量データベースを扱うようになり、大幅に大容量データを効率的に処理できる方式が必要になります。
その結果、10g R2では、Parallel Join時のSlave間のコミュニケーションデータ量とHash Join時の負荷を低減するために初めてBloom Filterを採用し、その結果は非常に優れていました。
Oracleはここにとどまらず、11g R1ではJoin Filter PruningやResult Cacheをサポートするのにも活用され、OracleでBloom Filter活用幅はますます広がってきています。
特に最近発売したEXADATAの場合には、Bloom Filterがoffloadingで処理するようにすることで、データベースの負荷を減らすことができる重要な要素となります。
今後も引き続きデータは膨大になるでしょうし、これによりOracle内のBloom Filterの活用はさらに重視されるであろうと筆者は考えます。
したがって、Bloom Filterとは何か、そしてOracleで、パフォーマンスを向上させるためにBloom Filterをどのように活用する必要があるのかを見てみます。
この文書は、Bloom Filterのアルゴリズムを理解し、それをOracleで効果的に活用する目的で作成されています。
Bloom Filterの動作原理
Bloom Filterは、mビットサイズのビット配列構造と、異なるK個のHash関数を使用して実装されます。
ここで、各 Hash 関数は m 個の値を均等な確率で出力しなければなりません。
理解を助けるために例を挙げてみます。
10ビットサイズのビット配列構造を持ち、1つのHash関数を持つBloom Filterがあるとします。 Hash関数は10で割った後に残りの値を求める関数です。
Filter の基準となる集合の元素が 34 一つだけであれば (Oracle で先行テーブル)、10 で割った残りは 4 なので 4 番目のビットを 1 に変更します
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
基準セットと比較するターゲットの(Oracleの後続テーブル)最初の要素が56であるとします。 まず56に対してHash関数を実行します。
それから6という結果が得られます。
したがって、6番目のビットを確認すると、結果は0です。
残りの値が4でない場合、基準セットである34と値が同じである可能性は0%です。
したがって、結合を行う必要のない対象となります。
比較対象の2番目の値は54とします。
54にHash関数を実行すると、4の結果値が得られます。
したがって、4番目のビットを確認したところ、値は1です。
私たちは一気に34と54は同じではないと判断しますが、Bloom Filterアルゴリズムの立場では、54や34、またはHash関数の実行結果はそれぞれ4です。
54 は 4 番目の bit が 1 なので、一旦真だが最後に値を比較する演算をするときに偽になります。 Bloom Filter 偽であるが真である場合(False Negative)は発生しませんがが、54 のように真であるが偽となる場合は(False Positive)発生します。
問題はfalse positiveが多く発生するほど、Bloom Filterの性能はますます低下するということです。
Bloom Filterのパフォーマンスを向上させるためには、False positiveを減らす必要があります。 False positive を減らす方法には、配列のビット数を増やすか hash 関数を増やす方法があります。
配列のビット数を増やすとメモリ使用率が上がり、hash関数を増やすとcpu使用量が上がります。
したがって、ブルームフィルターの性能を向上させるためには、適切なmとkを維持することが非常に重要なポイントなのです。
Oracle Bloom Filterの動作要件
オラクルでもParallel JoinとPartition Table Joinの際にBloom Filterが活用されるますが、このときBloom filterは結合前に対象件数を減らして性能を最適化する役割を果たします。
Bloom Filterを使用するかどうかを制御する関連ヒントには、PX_JOIN_FILTER / NO_PX_JOIN_FILTERがあります。
しかし、そのヒントを使用しても、すべてのSQLに対してBloom Filterを使用するわけではありません。
Bloom Filterを使用するにはいくつかの前提条件が必要ですが、まとめてみると以下の通りとなります。
- ジョイン方法は必ず Hash Join または Merge Join でなければなりません。.
- Partition Table 結合でなければなりません(結合 Key は Partition Key でなければなりません)。
- Partition Table 結合でない場合は、Parallel Query でなければなりません。
- parallel Query でも partition table でもない場合でも Inline View 内に Group by を適切に含めた場合には Bloom Filter を使用することができます (結合カラムは Group by 句で使用されたカラムでなければならなりません)。
1つの注意点は、Parallel Queryの場合は前提条件を満たし、Bloom Filterを使用するようにヒントを使用しても、先行テーブルに対する定数条件がない場合にはBloom Filterが使用されないことです。
このような場合にBloom Filterを使用することが効率的であれば、Dummy条件を追加することで、強制的にBloom Filterに誘導することができます。
前提条件を満たし、ヒントまで与えたにもかかわらず、なぜ先行セットに定数条件がないと Bloom Filter を使用できないのでしょうか?
私の考えでは、Bloom Filterを使うことで、むしろ性能が大きく低下する部分を防ぎたいというOracleの考え方ではないかと考えられます。
たとえば、Bloom Filterを使用する場合、先行テーブルはFilterセットを作成するために使用されます。
たとえば、条件がなく、抽出されたセットに1から10までのデータが含まれているとします。 そして、ビット配列のサイズが10の場合、10の配列はすべて1に設定されます。
これはすべてのデータが false positive が発生することで、結合前にデータをあらかじめろ過していた Bloom Filter の目的を衰退させてしまいます。
つまり、先行テーブルに条件がないと、大量のデータが抽出されることになり、これによりビット配列の大部分が1にマーキングされることでBloom Filterの効率が低下する可能性が大きくなるということです。
しかしデータ件数が多くても、14、24、34、54、104、204、……式でいずれも端数が4のデータだけであれば、10個の配列のうち4番目だけが1になるので、falsepositiveが発生する確率は大きく減ります。
まさにこのような状況が、私たちがダミー条件を追加してもBloom Filterを使用するように誘導しなければならない状況です。
それでは、Bloom Filterをいつ使用するべきですか?
答えは簡単明瞭です。
効率が良いときに使用しなければならない。
もしそうなら、Bloom Filterの効率性をどのように確認するべきかを見てみましょう。
Bloom Filterの利点と監視方法
OracleがBloom Filterを使用することによって得られる利点は次のとおりです。
- Bloom Filter は (Join Filter Pruning) Hash Join や Merge Join をする前にJoin対象件数をあらかじめ減らすことで Join の負荷を減少させる。
- Parallel Processing の場合 Slave で結合を行うために Coordinate に送信する通信量を減少させ、結合の負荷まで減少させる。
- EXADATA では Bloom Filter を offloading として処理することで Cell Server の CPU を使用して DB サーバへの CPU 負荷を低減させる。
Bloom Filterは上記のように利点がありますが、False positiveの発生頻度が高い場合、むしろより非効率的であるため、現在SQLがBloom Filterを使用している場合、どのくらい効率的なのかを監視する必要性があります。
これから、OracleでBloom Filterが使用されているかどうか、およびその効率を監視する方法について学びましょう。
Bloom Filterを監視する方法は、Parallelを使用するかどうかによって異なります。
まず、Parallel Processingの場合について学びましょう。
Parallel SQLの場合、DBMS_XPLANのPredicate Informationを使用してBloom Filterを使用するかどうかはわかりますが、実際の作業はそれぞれのSlave Processが行うため、実際の量がわからないためモニタリングが不可能です。
したがって、Parallelを使用した場合は、V $ SQL_JOIN_FILTER Viewを介して観察する必要があります.

<< V$SQL_JOIN_FILTER View による観察>>
SELECT qc_session_id ,
sql_plan_hash_value , filtered ,
probed ,
probed- filtered AS send FROM v$sql_join_filter
WHERE qc_session_id = 21;

FILTEREDはBloom Filterで削除されたRowを意味し、PROBEDは全体のターゲットを意味します。 つまり、FILTEREDとPROBEDの数値が似ているほど効率が高いと見ることができます。
つまり、全体のPROBED集合対象は10万件であるが、その中でBloom Filterで99,993件をろ過した後、7件のデータのみCoordinateに転送した後、結合演算をしたことが分かります。
Parallel SQLの場合は、上記のパフォーマンスビューを持ってBloom Filterの効率をチェックすればいいのです。
1つの注意点は、V $ SQL_JOIN_FILTERパフォーマンスビューは、Parallel SQLに対してのみパフォーマンスが収集されることです。
Partition Join Pruningの場合、そのビューに情報が残らないため、この時点ではDBMS_XPLANまたはTrace結果を介して効率を監視する必要があります。
XPLANによる分析は、次の内容であるBloom Filterを使用するかどうかのテストで詳しく説明します。
Bloom Filterを使用するかどうかのテスト
今から、Bloom Filterがどのような状況で使用されているのか、また使用されている場合は、その効率を確認する方法について5つのテストで調べてみます。
まず、テスト用のテーブルを作成してみましょう。
テストスクリプト
<< FUNCTION_TABLE テーブル作成>>
CREATE TABLE FUNCTION_TABLE AS SELECT LEVEL C1,
MOD(LEVEL, 2) C2, CHR(65+MOD(LEVEL,26)) C3, MOD(LEVEL, 3) +1 C4
FROM DUAL
CONNECT BY LEVEL <= 100000;
— 各列にインデックスを作成して統計情報を収集する
CREATE UNIQUE INDEX IDX_FUNCTION_TABLE_C1 ON FUNCTION_TABLE(C1); CREATE INDEX IDX_FUNCTION_TABLE ON FUNCTION_TABLE(C2,C3); CREATE INDEX IDX_FUNCTION_TABLE_C4 ON FUNCTION_TABLE(C4);
EXEC
dbms_stats.gather_table_stats(OWNNAME=>’SCOTT’,TABNAME=>’FUNCTION_TABLE’,CASCADE=>TRUE,ESTIM ATE_PERCENT=>100) ;
<< C1_CODE_NAME テーブルの作成>>
— 列C1のコード性表の作成と索引の生成]
— C1_CODE_NMテーブルの作成
CREATE TABLE C1_CODE_NM AS SELECT LEVEL C1,
LEVEL||’C2 CODE VALUE’ C2, CHR(65+MOD(LEVEL,20)) C3, MOD(LEVEL,5) C4
FROM DUAL
CONNECT BY LEVEL <= 100000;
— インデックスの生成と統計情報の収集
CREATE UNIQUE INDEX IDX_C1_CODE_NM ON C1_CODE_NM(C1);
EXEC
dbms_stats.gather_table_stats(OWNNAME=>’SCOTT’,TABNAME=>’C1_CODE_NM’,CASCADE=>TRUE,ESTIMATE_
PERCENT=>100) ;
<<PART_TEST パーティションテーブルの作成 >>
CREATE TABLE SCOTT.PART_TEST ( C1 NUMBER,
C2 VARCHAR2(4), C3 NUMBER,
C4 VARCHAR2(4), BIG_ADDR VARCHAR2(3000)
) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 STORAGE(
BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE USERS
PARTITION BY RANGE (C1)
(PARTITION TB1 VALUES LESS THAN (40000) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE USERS NOCOMPRESS , PARTITION TB2 VALUES LESS THAN (600000)
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE USERS NOCOMPRESS , PARTITION TB3 VALUES LESS THAN (800000)
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE USERS NOCOMPRESS ,
PARTITION TB4 VALUES LESS THAN (1000000) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE USERS NOCOMPRESS ,
PARTITION SYS_P21 VALUES LESS THAN (20000000) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE USERS NOCOMPRESS ) ;
insert into part_test value (select level, CHR(65+MOD(LEVEL,26)), level+99999, CHR(65+MOD(LEVEL,26)), null from dual connect by level <=2000000);
dbms_stats.gather_table_stats(OWNNAME=>’SCOTT’,TABNAME=>’PART_TEST’,CASCADE=>TRUE,ESTIMATE_ PERCENT=>100) ;
No Parallel でヒープテーブルの場合
まず、No Parallelであり、通常のテーブルの場合にBloom Filterが使用されていることを確認してます。

ヒープテーブルで Parallel Query でなければ、 PX_JOIN_FILTER をヒントに使用しましたが、前提条件を満たさないために Bloom Filter を使用できなかったことがわかります。
ヒープテーブルですがParallel処理をする場合
ヒープテーブルで Parallel Processing を実行する場合に Bloom Filter が使用されることを確認する要因を見てみます。
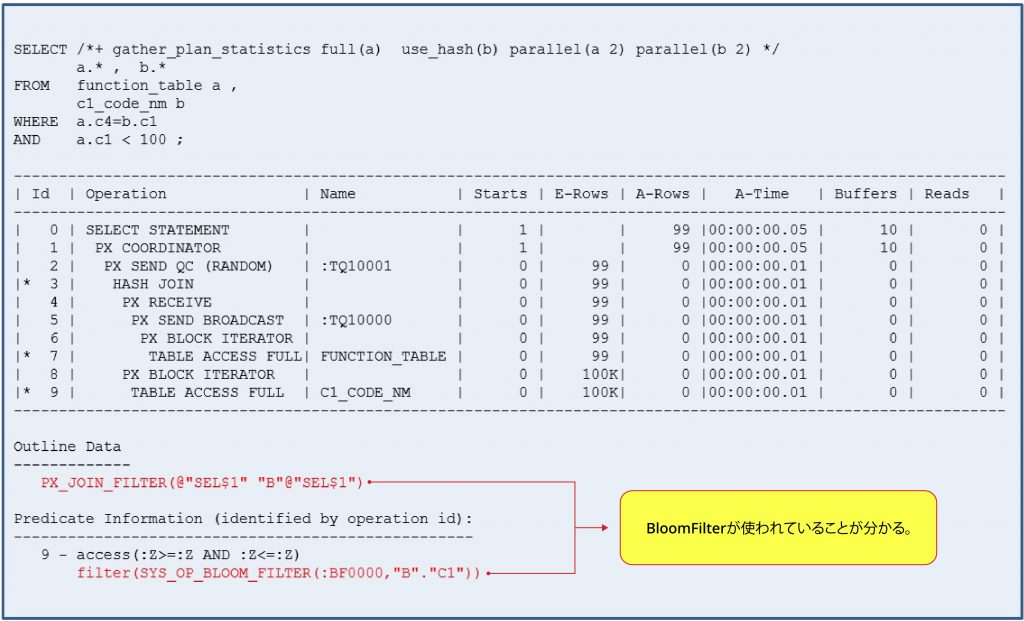
まず、Outline Dataを確認してみると、PX_JOIN_FILTERヒントが適用されており、Bloom Filterが使用されたことがわかります。
また、Predicate Information の存在する filter(SYS_OP_BLOOM_FILTER(:BF0000, ”B”.”C1”)) 条件も Bloom Filter が使用されたことを意味する。
しかし、Bloom Filterが効果的かどうかはDBMS_XPLANを介して確認することはできなません。
なぜなら、実際の仕事を行ったプロセスはSlaveなので、量に関する情報が表示されないからです。 上記の例のように、Parallel SQLに対するBloom Filterの効率を確認するには、V $ SQL_JOIN_FILTERパフォーマンスViewで確認する必要があります。
上記のBloom Filter効率監視Scriptを活用して上記のSQLに関する情報を確認すると、下の図のようになります。
前提 100,000 件の中から 99,993 を Bloom Filter でデータをろ過したことが分かるます。 これは、Bloom Filterが非常に効果的に使用されたことを意味します。
FILTERED値が非常に小さい場合、Bloom Filterの効率が低下し、むしろBloom Filterを使用するためのオーバーヘッドのみが増加するため、NO_PX_JOIN_FILTERヒントを使用してBloom Filterを使用できないようにする必要があります。
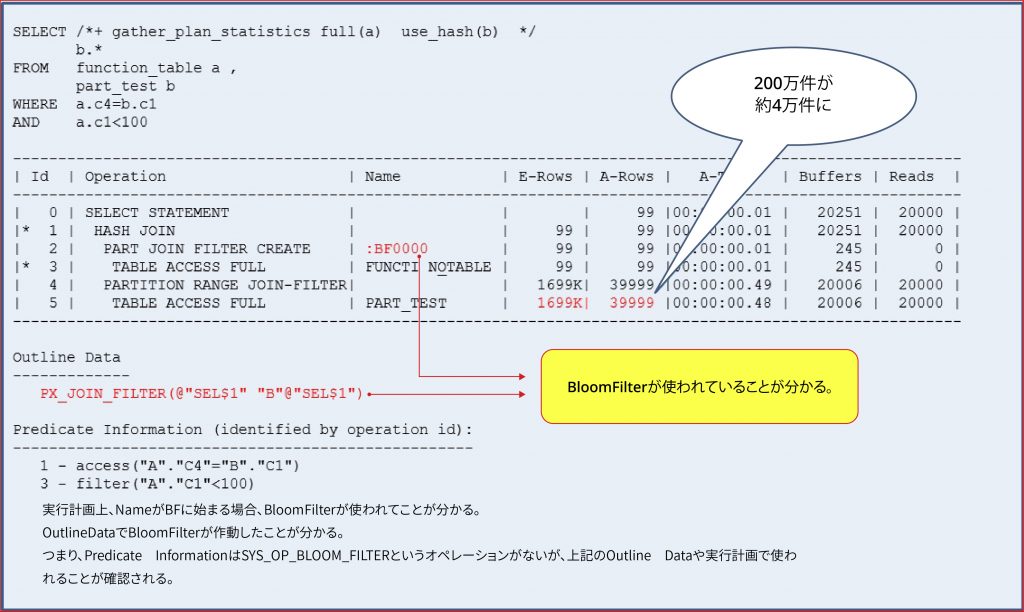
No Parallelですがパーティションテーブルの場合
No Parallel Processingですがパーティションテーブルの場合は、Bloom Filterが使用されていることを確認してみます。
Outline Data を確認してみると、PX_JOIN_FILTER ヒントが適用されており、実行計画上 PART JOIN FILTER CREATE オペレーション名である :BF000 を通じて該当 SQL が Bloom Filter を使用したことが分かります。
上記のSQLはparallel Processingではないので、Viewを介して効率を確認することは不可能です。
したがって、この場合はDBMS_XPLANを介して確認できます。
PART_TESTテーブルの総件数は200万件です。
別の定数条件が存在しない場合は、Hash Joinで200万件の全体に対してHash Joinを実行する必要があります。
ところで、PART_TESTテーブルをFULL SCANした後のA-Rows部分を見ると39,999件になりました。
これは Bloom Filter で不要な結合対象を除去し、39,999 件に対してのみ実際の Hash Join を行ったと見られます。
実行計画でA-Rowsが200万に近い場合、これはBloom Filterを使用した利点がほとんどなかったことを意味します。
このようなときには、NO_PX_JOIN_FILTERヒントを使用してBloom Filterを使用しないようにすることで、Bloom Filterによるオーバーヘッドを削除する必要があります。
一つ注意すべき点がある。 Join Filter 機能は 11g で追加された機能で 10g では使用できないということと、結合カラムを必ずパーティション Key 列で結合しなければ使用できないということです。 (結合キーで書かれたPART_TEST C1はパーティションキー列です。C1以外のC2列で結合すると、Bloom Filterは使用できません。)
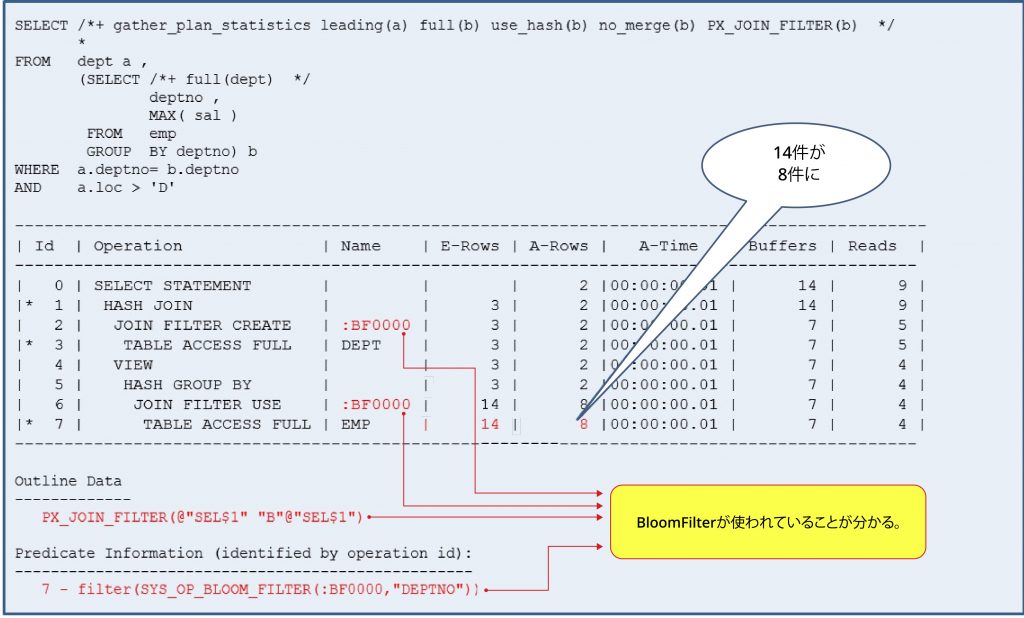
No Parallel でヒープテーブルの場合 (Group by 句存在)
No Parallel であり、ヒープテーブルであるが Group By を持つ Inline View が存在するときの場合、 BloomFilterを使用しているかどうかを確認します。
ヒープテーブルで No Paralle SQL なので Bloom Filter の使用が不可能に見えますが、Outline Data を確認してみると PX_JOIN_FILTER がヒントが適用されており、PLAN や PredicateInformation でも Bloom Filter を使った痕跡を確認することができます。
Bloom Filterの効率を確認すると、全14件中6件がBloom Filterを介して結合対象から除去されたことを確認することができます。 ヒープテーブルであり、No Parallelであるにもかかわらず、Bloom Filterが使用された理由は、Inline Viewの中にあるGroup by句によるものです。 Inline Viewのデータを見ると、Deptno別にMax(sal)を求めています。 これは、パーティションテーブルのように、データがDeptnoに基づいて明確に区切られているためです。
インラインビューをパーティションと比較すると、パーティションKeyに対応する部分はGroup by句にリストされているdeptnoです。
パーティションテーブルの場合、結合は条件がパーティションキーでなければなりませんが、Bloom Filterを使用できました。
Group by句を使ったInline Viewも同様です。 パーティションキーに対応するGroup by句に対応する列Deptnoと結合キーが存在する必要がありますが、Bloom Filterを使用できます。
結論
これまで、Bloom Filterが何であるか、OracleでBloom Filterがどのように使用されているかを調べまました。
さらに、Oracleで使用されているBloom Filterが効率的であるかどうかを判断する方法について説明しました。 Bloom FilterはSlave間のコミュニケーションデータ量はもちろん、Joinによる負荷を効果的に減らしてパフォーマンスを改善する方法ですが、常にそうであるとは限りません。
したがって、我々は効率を判断した後、有利な場合にのみ使用することが望ましいのです。
Bloom Filterは大容量データを非常に効率的に処理できます。
そのため、Oracleもバージョンが上がるたびに活用範囲が増えている傾向にあります。 そしてこれからももっと多くの場所で活用されると予想されます。
このように活用幅が大きくなるBloom Filterのアルゴリズムを理解し、さらに一歩進んで、Bloom Filterの使用が効率的かどうかを判断し、適材適所で活用すれば、DBの性能を改善する上で多くの役に立つと考えられます。


