2022.06.22
SQL分析機能

Contents
- ANALYTIC FUNCTIONの理解
- ANALYTIC FUNCTIONの理解
- Window Aggregate Family
- FIRST/ LAST
- LAG/ LEAD
- ANALYTIC FUNCTIONの実行。
- ROLLUP/ CUBE
Analytic Functionとは?
・Business 分野で頻繁に行われる様々な形態の分析に有用に活用できる
SQL Function
・Running Summary, Moving Average, Ranking, Row 比較(LEAD/LAG Func)
・Pointer/Offsetの概念が導入
・Query Speed の向上
・改善された開発生産性
・Self Joinなどにより困難に実装されたSQLをより容易に表現可能
・大量のデータで複数のAnalytic Functionを使用すると、パフォーマンスの低下が発生する可能性があります。
・Oracle 8iからのサポート
分析機能の実行プロセス
- General Query Processing : Join、Where条件節、Group By、Havingなどの既存のQuery Processing実行ステップ。
- Analytic Function Applying :ステップ1の結果を持つ実際のAnalytic Functionが適用され、必要計算を行うステップ。
⇒つまり、Analytic Functionの実行対象はSELECT句の列です。
3.Order By Processing : QueryにOrder By句がある場合は、最終結果のOrdering実行ステップ。
SELECT ename, sal, job,
RANK() OVER ( PARTITION BY job ORDER BY sal ) rank_sal, SUM(sal) OVER ( PARTITION BY job ORDER BY sal ) sum_sal
FROM emp WHERE sal > 100 ORDER BY job

分析機能のメカニズム
- Partitioning
– PARTITION BY句の列構成によるパーティションの設定。
– PARTITION BY句未記述の場合、全体を1つのパーティションとして扱います。
2.Ordering
– ORDER BY 句 記述時にパーティション単位で ORDER BY 句列の順序でソートします。
ORDER BY句は、Analytic Functionの種類(特性)別にのみ記述可能。
⇒ORDERINGが必要ない場合は省略可能!
3.Caculations Based on Window Contents
設定された処理範囲のターゲットROWに対してAnalytic Functionを実行。
4.Analytic FunctionはSELECT句とORDER BY句にのみ対応することができます。
5.Analytic Functionを適用した後のQueryの結果集合レベルは、Analytic Functionを適用する前の
結果セットレベルと同じ(Grouping Setを除く)
6.PGAのSORT_AREA_SIZEとTemporary Segmentの使用。
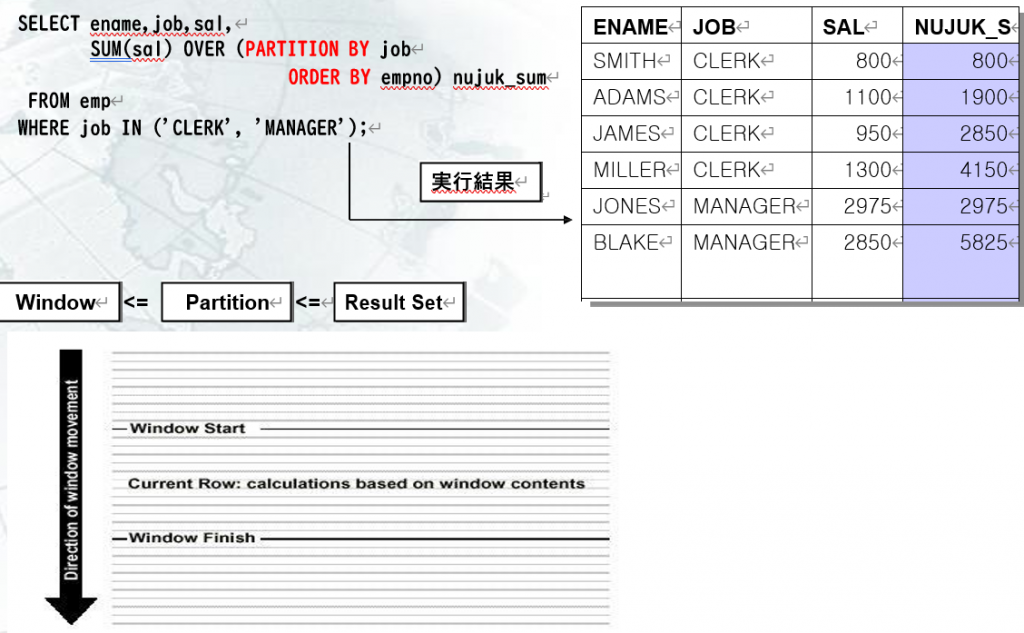
ResultSet,Window,CurrentRow
分析機能リスト(9iR2ベース)

目的:結果セット内の他のレコードと比較してランク付けするために使用
Syntax : RANK() OVER ( [PARTITION BY <value expression1> [, …]]
ORDER BY <value expression2> [collate clause] [ASC|DESC] [NULLS FIRST|NULLS LAST] [, …] )
- RANK and DENSE_RANK
- CUME_DIST and PERCENT_RANK
- NTILE
- ROW_NUMBER
Sample
SELECT ename,job,sal,
RANK() OVER (PARTITION BY job ORDER BY sal) Rank1 ,
DENSE_RANK() OVER (PARTITION BY job ORDER BY sal) Dense_Rank ,
ROW_NUMBER() OVER (PARTITION BY job ORDER BY sal) Rownum_Rank FROM emp
WHERE job IN (‘CLERK’, ‘SALESMAN’);
| ENAME | JOB | SAL | RANK1 | DENSE_RANK | ROWNUM_RANK |
| SMITH | CLERK | 800 | 1 | 1 | 1 |
| JAMES | CLERK | 950 | 2 | 2 | 2 |
| ADAMS | CLERK | 1100 | 3 | 3 | 3 |
| MILLER | CLERK | 1300 | 4 | 4 | 4 |
| MARTIN | SALESMAN | 1250 | 1 | 1 | 1 |
| WARD | SALESMAN | 1250 | 1 | 1 | 2 |
| TURNER | SALESMAN | 1500 | 3 | 2 | 3 |
| ALLEN | SALESMAN | 1600 | 4 | 3 | 4 |
目的: Aggregate Functionの拡張形式
Syntax : {SUM|AVG|MAX|MIN|COUNT|STDDEV|VARIANCE|FIRST_VALUE|LAST_VALUE}
({<value expression1> | *})
OVER ([PARTITION BY <value expression2>[,…]]
ORDER BY <value expression3>[collate clause>][ASC| DESC] [NULLS FIRST | NULLS LAST] [,…]
ROWS | RANGE{ {UNBOUNDED PRECEDING |
<value expression4> PRECEDING}|
BETWEEN {UNBOUNDED PRECEDING |
<value expression4> PRECEDING} AND {CURRENT ROW |
<value expression4> FOLLOWING} }
)
Window Size定義で使用されるKEY WORD
q ROWS : 物理的なROW単位でWINDOWを指定することを示します。
q RANGE : 論理的な相手先としてWINDOWを指定することを示します。
- CURRENT ROW : 現在の Row で Window が開始または終了することを示します。
- UNBOUNDED PRECEDING : Partitionの最初の行でWindowが開始されることを示します。
- UNBOUNDED FOLLOWING : Partition の最後の行で Window が終了したことを示します。
- Order By句がない場合 : RANGE BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING
- Order By句がある場合 : RANGE BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW
Range のない Analytic Function
SELECT ename,job,
SUM(sal) OVER (PARTITION BY job ORDER BY empno) nujuk_sum , SUM(sal) OVER (PARTITION BY job) p_sum ,
SUM(sal) OVER () all_sum , FIRST_VALUE(sal) OVER (PARTITION BY job ORDER BY empno) first_value, LAST_VALUE(sal) OVER (PARTITION BY job ORDER BY empno) last_value
FROM emp
WHERE job IN (‘CLERK’, ‘MANAGER’);
| ENAME | JOB | NUJUK_S | P_SUM | ALL_SUM | FIRST_V | LAST_VALUE |
| SMITH | CLERK | 800 | 5150 | 13425 | 800 | 800 |
| ADAMS | CLERK | 1900 | 5150 | 13425 | 800 | 1100 |
| JAMES | CLERK | 2850 | 5150 | 13425 | 800 | 950 |
| MILLER | CLERK | 4150 | 5150 | 13425 | 800 | 1300 |
| JACK | CLERK | 5150 | 5150 | 13425 | 800 | 1000 |
| JONES | MANAGER | 2975 | 8275 | 13425 | 2975 | 2975 |
| BLAKE | MANAGER | 5825 | 8275 | 13425 | 2975 | 2850 |
| CLARK | MANAGER | 8275 | 8275 | 13425 | 2975 | 2450 |
NumberTypeのRange

| ENAME | JOB | SAL | ROWNUM | SAL1 | SAL2 | SAL3 |
| JAMES | CLERK | 950 | 1 | 950 | 950 | 1750 |
| SMITH | CLERK | 800 | 2 | 1750 | 1750 | 2850 |
| ADAMS | CLERK | 1100 | 3 | 1900 | 1900 | 3200 |
| MILLER | CLERK | 1300 | 4 | 2400 | 2400 | 3400 |
| JACK | CLERK | 1000 | 5 | 2300 | 2300 | 2300 |
DateTypeのRange
SELECT ename,job, sal, TRUNC(hiredate),
SUM(sal) OVER (PARTITION BY job ORDER BY hiredate ROWS 1 PRECEDING ) rows_1 ,
SUM(sal) OVER (PARTITION BY job ORDER BY hiredate
RANGE BETWEEN INTERVAL ‘1’ YEAR PRECEDING
AND INTERVAL ‘1’ YEAR FOLLOWING ) year_1 ,
SUM(sal) OVER (PARTITION BY job ORDER BY hiredate
RANGE BETWEEN INTERVAL ‘1’ MONTH PRECEDING
AND INTERVAL ‘2’ MONTH FOLLOWING) month_1,
SUM(sal) OVER (PARTITION BY job ORDER BY hiredate
RANGE BETWEEN INTERVAL ‘1’ DAY PRECEDING
AND INTERVAL ’99’ DAY FOLLOWING ) day_1
FROM emp
WHERE job = ‘CLERK’
ORDER BY hiredate;
| ENAME | JOB | SAL | HIREDATE | ROWS | YEAR | MONTH | DAY_1 |
| JACK | CLERK | 1000 | 1980/12/01 | 1000 | 1800 | 1800 | 1800 |
| SMITH | CLERK | 800 | 1980/12/17 | 1800 | 2750 | 1800 | 800 |
| JAMES | CLERK | 950 | 1981/12/03 | 1750 | 3050 | 2250 | 2250 |
| MILLER | CLERK | 1300 | 1982/01/23 | 2250 | 3350 | 1300 | 1300 |
| ADAMS | CLERK | 1100 | 1983/01/12 | 2400 | 2400 | 1100 | 1100 |
VariableTypeのRange
SELECT a.ename,a.job, a.sal,rownum,b.no1,
SUM(sal) OVER (PARTITION BY job ORDER BY rownum RANGE BETWEEN b.no1 PRECEDING
AND b.no1 FOLLOWING ) sal3
FROM emp a,
( SELECT 1 no1 FROM dual
UNION ALL
SELECT 2 no1 FROM dual
) b
WHERE job = ‘CLERK’;
| ENAME | JOB | SAL | ROWNUM | NO1 | SAL3 |
| JAMES | CLERK | 950 | 1 | 1 | 1900 |
| JAMES | CLERK | 950 | 2 | 2 | 3500 |
| SMITH | CLERK | 800 | 3 | 1 | 2550 |
| SMITH | CLERK | 800 | 4 | 2 | 4750 |
| ADAMS | CLERK | 1100 | 5 | 1 | 3000 |
| ADAMS | CLERK | 1100 | 6 | 2 | 5600 |
| MILLER | CLERK | 1300 | 7 | 1 | 3700 |
| MILLER | CLERK | 1300 | 8 | 2 | 5700 |
| JACK | CLERK | 1000 | 9 | 1 | 3300 |
| JACK | CLERK | 1000 | 10 | 2 | 3300 |
目的: ORDER BY句で指定された最初または最後の値を見つけるために使用されます。
Syntax : {MIN | MAX | SUM | AVG | COUNT | VARIANCE | SETDEV }
KEEP ( DENS_RANK FIRST ORDER BY <value expression1>
[ASC | DESC] [NULL FIRST| NULL LAST]
OVER ([PARTITION BY <value expression2>[,…]] )
- 一般的なAnalytic Function
- 各パーティションにグループ関数を適用します。
- FIRST/LAST
各パーティションごとの基準項目でソートした後、FIRST / LAST Value Setにグループ関数を適用します。
SELECT empno,, deptno, sal , hiredate,
min(hiredate) OVER (partition by deptno order by sal) nor_min , min(hiredate) OVER (partition by deptno ) nor2_min , min(hiredate) KEEP (DENSE_RANK FIRST ORDER BY )
OVER (partition by deptno ) first_min
FROM scott.emp
| EMPNO | DEPTNO | SAL | HIREDATE | NOR_MIN | NOR2_MIN | FIRST_MIN |
| 7934 | 10 | 1300 | 1982-01-23 | 1982-01-23 | 1981-06-09 | 1982-01-23 |
| 7782 | 10 | 2450 | 1981-06-09 | 1981-06-09 | 1981-06-09 | 1982-01-23 |
| 7839 | 10 | 5000 | 1981-11-17 | 1981-06-09 | 1981-06-09 | 1982-01-23 |
| 7369 | 20 | 800 | 1980-12-17 | 1980-12-17 | 1980-12-17 | 1980-12-17 |
| 7876 | 20 | 1100 | 1983-01-12 | 1980-12-17 | 1980-12-17 | 1980-12-17 |
| 7566 | 20 | 2975 | 1981-04-02 | 1980-12-17 | 1980-12-17 | 1980-12-17 |
| 7788 | 20 | 3000 | 1982-12-09 | 1980-12-17 | 1980-12-17 | 1980-12-17 |
目的:テーブルの2行を位置に応じて比較するために使用します。
Syntax : {LAG | LEAD}(<value expression1>, [<offset> [, <default>]]) OVER ([PARTITION BY <value expression2>[,…]]
ORDER BY <value expression3> [collate clause>][ASC | DESC]
[NULLS FIRST | NULLS LAST] [,…]
)
- LAG 以前のROW比較
- LEAD 以降のROW比較
– RDBMSの基本原則に違反しますが、前後のロー比較はSQL作成効率を向上させる強力な機能を提供。
à Self Join、レプリケーションでしか処理できなかった既存の方式を改善。
( RDBMSの論理上の集合内のすべての行間の物理的、論理的関連性はありません!)
SELECT empno, job,
TO_CHAR(hiredate,’yyyymmdd’) hiredate,
LAG(hiredate) OVER (PARTITION BY job ORDER BY hiredate) lag_1 , LEAD(hiredate) OVER (PARTITION BY job ORDER BY hiredate) lead_1 , LAG(hiredate,2) OVER (PARTITION BY job ORDER BY hiredate) lag_2 , LEAD(hiredate,2) OVER (PARTITION BY job ORDER BY hiredate) lead_2
FROM emp
WHERE job IN (‘CLERK’, ‘SALESMAN’) ;
| EMPNO | JOB | HIREDATE | LAG_1 | LEAD_1 | LAG_2 | LEAD_2 |
| 9999 | CLERK | 19801201 | 1980/12/17 | 1981/12/03 | ||
| 7369 | CLERK | 19801217 | 1980/12/01 | 1981/12/03 | 1982/01/23 | |
| 7900 | CLERK | 19811203 | 1980/12/17 | 1982/01/23 | 1980/12/01 | 1983/01/12 |
| 7934 | CLERK | 19820123 | 1981/12/03 | 1983/01/12 | 1980/12/17 | |
| 7876 | CLERK | 19830112 | 1982/01/23 | 1981/12/03 | ||
| 7499 | SALESMAN | 19810220 | 1981/02/22 | 1981/09/08 | ||
| 7521 | SALESMAN | 19810222 | 1981/02/20 | 1981/09/08 | 1981/09/28 | |
| 7844 | SALESMAN | 19810908 | 1981/02/22 | 1981/09/28 | 1981/02/20 | |
| 7654 | SALESMAN | 19810928 | 1981/09/08 | 1981/02/22 |
Lag / Leadを使用して冗長履歴を分割する
SELECT ban,s_date,e_date FROM test ;
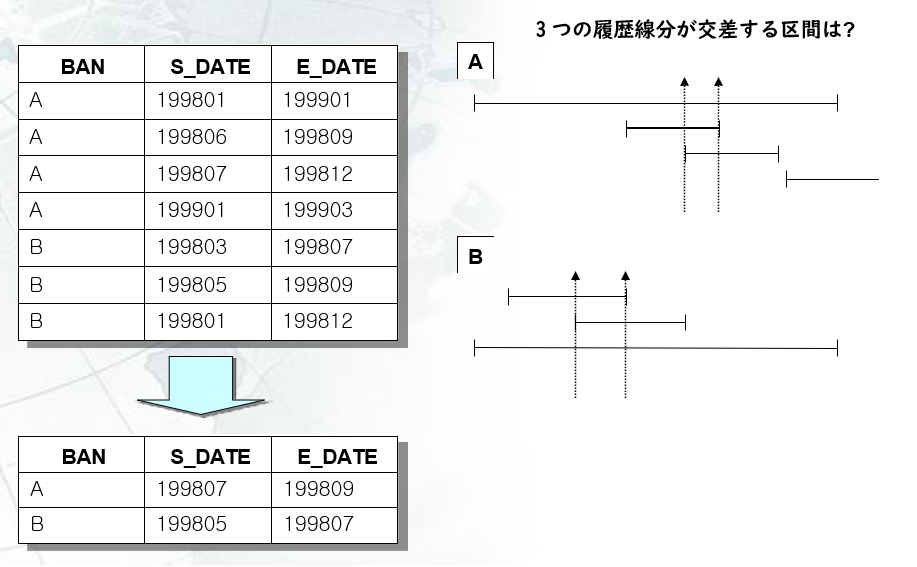
| BAN | S_DATE | E_DATE |
| A | 199807 | 199809 |
| B | 199805 | 199807 |
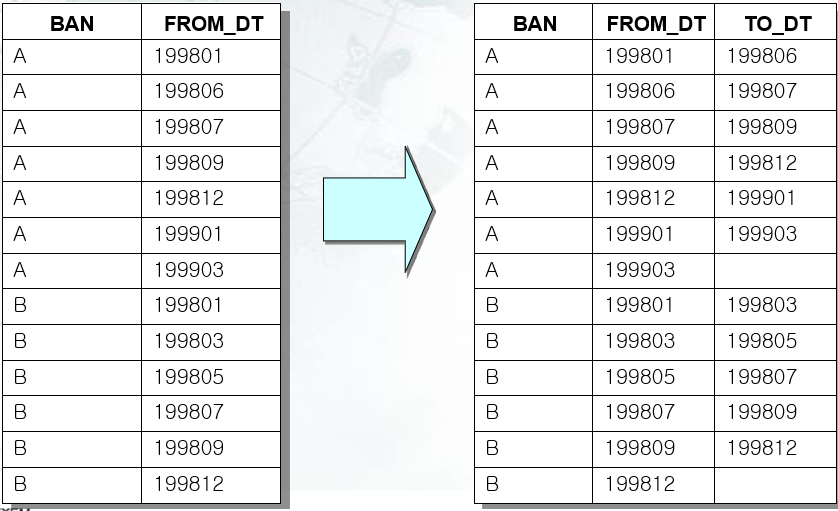
Data複製を介して線分を作成する
SELECT ban,DECODE(no1,1,s_date,e_date) from_dt
FROM test, ( SELECT 1 no1 FROM dual
UNION ALL
SELECT 2 no1 FROM dual ) GROUP BY ban, DECODE(no1,1,s_date,e_date);
Lag/Leadを使用して線分を作成する
SELECT ban, from_dt,
LEAD(from_dt) OVER (PARTITION BY ban ORDER BY from_dt) to_dt FROM ( SELECT ban, DECODE(no1, 1, s_date, e_date) from_dt
FROM test,
( SELECT 1 no1
FROM dual UNION ALL SELECT 2 no1
FROM dual )
GROUP BY ban, DECODE(no1, 1, s_date, e_date)
)
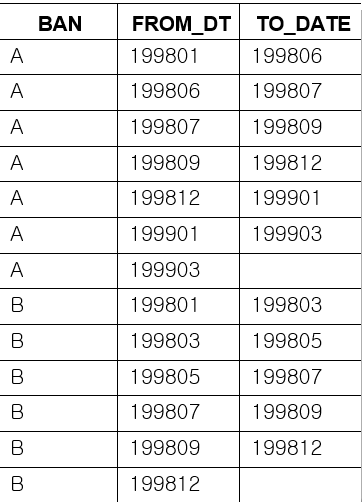
元の線分と新しく作成した線分とBetweenJoin
SELECT b.ban,b.from_dt,b.to_dt FROM test a,
( SELECT ban, from_dt,
LEAD(from_dt) over ( PARTITION BY ban
ORDER BY from_dt) to_dt
FROM ( SELECT ban,
DECODE(no1, 1, s_date, e_date) from_dt FROM test,
( SELECT 1 no1
FROM dual UNION ALL SELECT 2 no1
FROM dual )
GROUP BY ban, DECODE(no1, 1, s_date, e_date)
)
) b
WHERE a.ban = b.ban
AND b.from_dt < a.e_date
AND b.to_dt > a.s_date GROUP BY b.ban,b.from_dt,b.to_dt HAVING COUNT(*) > 2 ;

Analytic Function 実行計画
SELECT OWNER, OBJECT_NAME,
COUNT(*) OVER (PARTITION BY OWNER,TEMPORARY ) OBJTYPE_CNT , COUNT(*) OVER (PARTITION BY TEMPORARY ) TEMP_CNT , COUNT(*) OVER (PARTITION BY OBJECT_TYPE ) TYPE_CNT , ROW_NUMBER() OVER (PARTITION BY OWNER, OBJECT_TYPE
ORDER BY OBJECT_NAME ) OBJTYPE_POS ,
COUNT(*) OVER ( ) TOT_CNT
FROM BIG_OBJECTS WHERE OWNER = ‘HR’
*********************************************************************************************
SELECT STATEMENT CHOOSE-Cost : 6
WINDOW SORT WINDOW SORT
TABLE ACCESS BY INDEX ROWID FIRE.BIG_OBJECTS(1)
INDEX RANGE SCAN FIRE.BIG_OBJECTS_IDX2(U) (OWNER,OBJECT_NAME,SUBOBJECT_NAME,OBJECT_TYPE)
□実行計画上の表示
– Analytic FunctionはGeneral Result Setで処理されます。 実行計画上ではWINDOW SORTと表示されます。
WINDOW SORTは、記述されたAnalytic FunctionのPARTITION BY句の列構成に従って決定されます。
PARTITION BY句の先頭列からの構成順序、または結合によって決定されます
□作成ガイド
– PARTITION BY句の構成順序が一致する順序で記述。
□ RollupはGROUP BYの拡張形式(小計、合計形式)
□ Cube は、複製テーブルと同じ役割をする Cube を生成し、結合可能なすべての値に対して
SUBTOTALを生成する
□Parallelで実行可能
□ 時間や地域など、階層分類(大分類、中分類、小分類)を含むデータの集計に適しています。
□ Copy_Tのように複製テーブルを作成する必要はなく、Performanceの観点からもプラス
□ 過度に多くの Column を Cube に割り当てると、システムのリソースを過剰に使用する
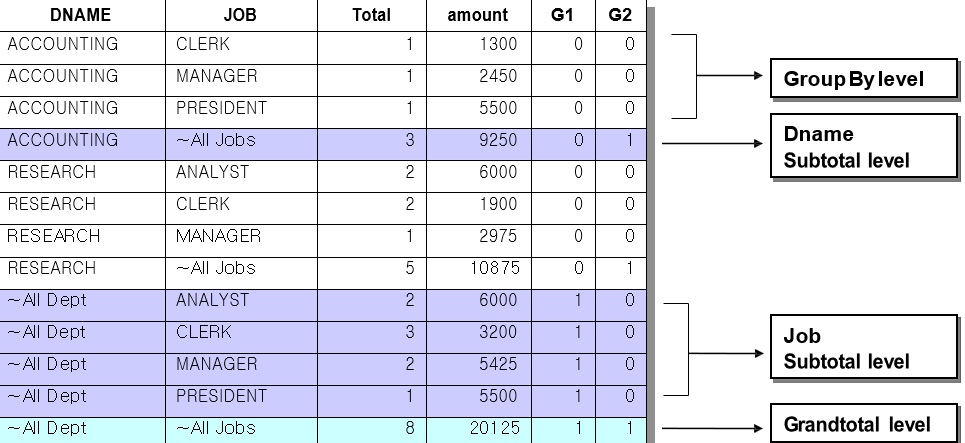
□ GROUPING関数の導入(Rollup、Cubeでのみ使用するNULL判定)- 元データの行と列とSub Totalの区別のために使用。
SubTotalを作成
Rollupの SUBTOTAL
GROUPING COLUMNSの数(n) n+1 LEVELのSUBTOTALを生成する
Cubeの SUBTOTOAL
GROUPING COLUMNSの数(n) n2 LEVELのSUBTOTAL生成
| GROUPING関数: ROLLUPORCUBEにより、 生成されたNullvalueに出会ったら数字1を返します。 |
SELECT DECODE(GROUPING(dname), 1, ‘All Departments’,dname) dname , DECODE(GROUPING(job) , 1, ‘All Jobs’, job) job , COUNT(*) total_cnt,
SUM(sal) amt , GROUPING(dname) g1, GROUPING(job) g2
FROM emp a, dept b WHERE a.deptno = b.deptno
GROUP BY ROLLUP (dname, job);
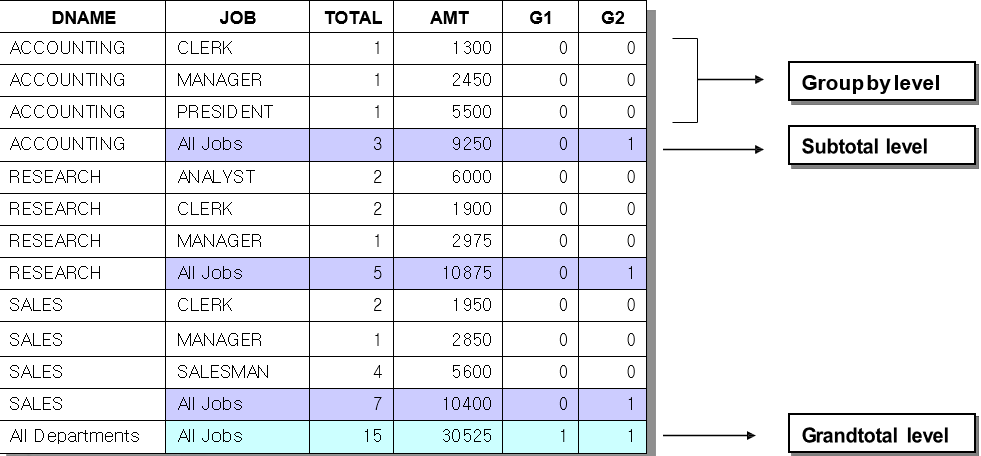
原集合を保存しながらSub TotalとGrand Totalを入手する
SELECT b.deptno ,b.dname,sal FROM emp a, dept b
WHERE a.deptno = b.deptno AND a.deptno IN (10,20)
| DEPTNO | DNAME | SAL |
| 10 | ACCOUNTING | 5500 |
| 10 | ACCOUNTING | 2450 |
| 10 | ACCOUNTING | 1300 |
| 10 | ACCOUNTING total amount | 9250 |
| 20 | RESEARCH | 2975 |
| 20 | RESEARCH | 3000 |
| 20 | RESEARCH | 800 |
| 20 | RESEARCH | 3000 |
| 20 | RESEARCH | 1100 |
| 20 | RESEARCH total amount | 10875 |
| Final total amount | 20125 |
原集合を保存しながらSub TotalとGrand Totalを入手する
SELECT b.deptno ,
DECODE(ROWNUM || b.deptno, null,’ Final total amount’,
b.deptno, MIN(b.dname)||’ total amount’, MIN(b.dname) ) dname ,
SUM(a.sal) sal
FROM emp a, dept b
WHERE a.deptno = b.deptno
GROUP BY ROLLUP( b.deptno,ROWNUM )
SELECT DECODE(GROUPING(dname), 1, ‘~All Dept’,dname) AS dname, DECODE(GROUPING(job) , 1, ‘~All Jobs’, job ) AS job , COUNT(*) “Total”, SUM(sal) “amount”,
GROUPING(dname) G1,GROUPING(job) G2
FROM emp a, dept b
WHERE a.deptno = b.deptno AND a.deptno in (10,20)
GROUP BY CUBE (dname, job) ORDER BY dname ,job ;