

2021.10.08
SSD概念と活用
SSD概念と活用
エクセム コンサルティング本部/DBコンサルティングチーム
概要
サーバーを構成する多くのデバイスの中で、CPU、メモリ、およびディスクがサーバーの最も重要な役割を果たし、サーバーの性能を決定します。この中でCPUとメモリのパフォーマンスは急速に増加していますが、ハードディスクは比較的遅いペースで成長しています。その理由は、CPUとメモリはデータを電子信号として扱い、これらの信号は微細な電子チップ上で処理しますが、ディスクはプラッタと呼ばれるディスクを水平に回転させてデータを処理するという機械的な制限があるためです。SSD は、このような短所を補完しメモリーの半導体技術を利用することで性能を向上させたメモリストレージ ディスクです。
SSDはHDDよりも優れた I/O パフォーマンスを提供し、持続的に寿命や安全性も改善中であるため、Oracle などのデータベース ストレージに頻繁に適用されます。Oracle でSSD を適用する一般的な機能の1 つは、db flash cache, smart flash cache, smart flash loggingなどです。
これにより、 SSDの速度をフルに活用して、データベースのパフォーマンスを向上させることができます。
この記事では、SSDの動作原理と、Oracle に適用する際に注意すべき事項について簡単に説明します。
ソリッドステートドライブ (SSD) とは何ですか
(1)SSD タイプ
SSDはソリッドステートドライブ(Solid state drive )、ソリッドステートディスク(solid state disk )の略であり、または電子ディスク(electronic disk )とも呼ばれています。
ハードディスクとの相違点は、機械的な装置がなく、半導体を利用して電子的信号により情報を保存します。
したがって、高速でデータを移動することができていて、機械的遅延や失敗が比較的少ないのが特徴です。SSDはラム方式のディーラム(DRAM)とフラッシュ方式のNAND型フラッシュ(Nand flash)に大きく分けることができます。
この両者の違いは、データの揮発性です。DRAM方式は、速度が速いが、電源がない場合、データがすべて消去される揮発性である半面、NAND型フラッシュ方式はDRAMより遅いが、電源がなくても、データが保持されている不揮発性です。これらの理由から、DRAMベースのSSDは、ほとんど使用されず、エンタープライズ級に適用されるのは、ほとんどのNAND型フラッシュ方式のSSDとして、フラッシュディスクとも呼ばれています。
(2)SSD の構造
NAND フラッシュベースの SSDは、複数のフラッシュチップを複数のデータバスに接続してプロセッサの役割をするマイクロコントローラで構成されています。
サイズと体積がHDDに比べて小さく、衝撃や振動に敏感ではない。HDDにあるヘッダやディスクなどの機械的な移動がなく、電子コンローラを利用して、データを移動するので、速度が速く、騒音と消費電力が少ない。
しかし、HDDに比べて寿命が短く、価格が高価で、磁場や静電気に弱い欠点があります。

SSD の基本ユニットは、セル(Cell) と呼ばれるシリコン形式の小さなブロックで構成されます。セルに格納されているバイナリ形式のデータサイズ に応じて、 SLC (Single level Cell) と MLC (Multi Level Cell) に分割できます。
SLCは1ビット(bit) を 1 つのセル(Cell)に格納し、MLCは2ビットを1 つのセルに格納する方法ですSLCとMLCの動作原理を簡単に説明すると、コントローラはセルにデータを格納するときにバッテリのゲートに電圧を印加し、電界を生成して0,1相を格納します。SLCでは、0と1 の2つの電圧のみを考慮する必要がありますが、MLCでは、4つの相 (00,01,10,11) を考慮する必要があります。データへのアクセスには時間がかかり、エラー率も増加します。したがって、SLCはディスクの応答が遅くなったり、反応がないフリージング(Freezing)現象がほとんどありません。MLCに比べて安定し成果速度を確保し、10万回までの読み込み、書き込みが可能です。しかし、やはり価格が高いという欠点があります。一方、MLCは安定性と速度がSLCよりも低下し寿命予測が難しいですが、価格はSLCに比べて安価です。その結果、エンタープライズ・ストレージには、安全で寿命が長いSLCタイプのSSDを大部分使用します。

SSDのストレージ構造は、HDDとは異なる構成されています。基本単位であるセルが集まったことをページとし、これらのページが集まったことをブロックとします。HDDと比較してページは、セクタに対応しと、ブロックはトラックに該当すると見ることができます。ページのブロックにつきましてはSSDの動作原理で詳しく説明します。
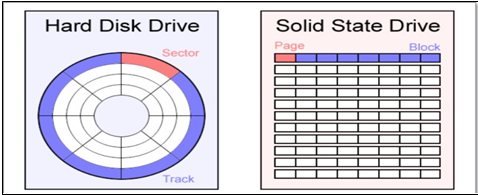
フラッシュSSDは、通常、SATA、PCI、および障害のあるドライブの3つのドライブ形式でインストールされます。
SATAベースのドライブは、他のSATAドライブと同じ形式で バンドルでき、SATAインターフェイスを介して任意のデバイスをインストールできます。
PCIベースのドライブは、PCIインターフェイスを介してデバイスのマザーボードに直接接続できます。障害自動サーバーは、複数の PCIカードを1つのラックに格納し、高速ネットワーク インターフェイス カードとしてデバイスにインストールします。SATAベースのドライブは、PCI またはラック サーバよりもはるかに安価ですが、SATAインターフェイスは、遅延が遅いミリ秒デバイス向けに設計されています。
したがって、SSDサービスは膨大なオーバーヘッドを引き起こす可能性があります。
PCIベースのデバイスはサーバーに直接接続されるため、ほとんどのデバイスは最適なパフォーマンスを提供します。
OracleのX-Dayの場合、インテリジェントフラッシュキャッシュとして使用されるSSDは、 PCIベースのデバイスに接続されます。

(3)SSD の動作原理
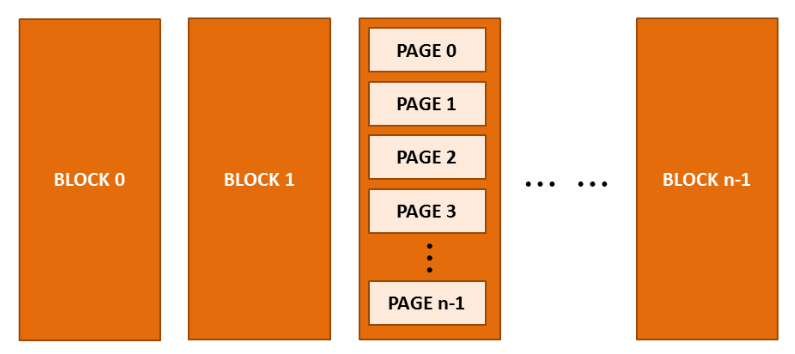
SSD の基本単位はセルと呼ばれるシリコン状の小片です。 これらのセルが複数集まったものをページといいます。 一つのページの大きさは通常4kbytesであり、複数のページが集まって一つのブロックを構成します。 一つのブロックの大きさは128Kから1Mだが、主に512Kで構成されます。
SSD はデータを読み込み、書き込むときページ単位で動作しますが、削除は必ずブロック単位で動作します。 これはSSD の性能と寿命を決定づける重要な特徴です。 すなわち、読み込み、書き出しは4K のページ単位からなりますが、削除はこれより大きい512K のブロック単位からになります。
HDDの場合、データを削除するとき、実際のディスクのデータを削除していないデータの位置情報であるメタ情報のリンクを切断し、そこに新たなデータを上書き(Overwrite)する方式で実装がされています。
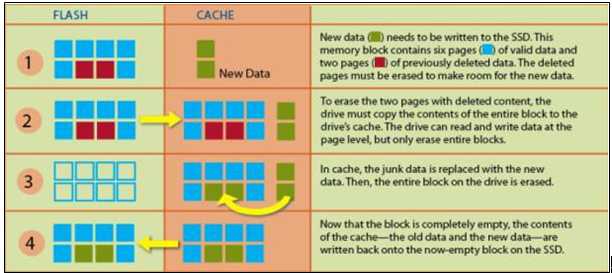
しかし、SSDは上書きが不可能で、空のページにのみデータを記録することができます。
もし空でないページにデータを書き込む必要がある場合は、データを削除後にデータを記録する必要があります。
したがって、特定のページの再記録のため、必ずページが属するブロック単位の削除が先行されるべきです。
このようにすると、ブロック内の関係のない ページがクリアされる可能性があります。
これを防止するために、まず、ブロックのデータすべてをSSD内部のラムキャッシュに移し、ブロックをクリアし、キャッシュ上の既存のデータと新しいデータを結合します。
その後、再び空になったブロックに結合されたデータを記録することになります。
このような理由でSSD からの削除は性能上最も負担になる過程です。
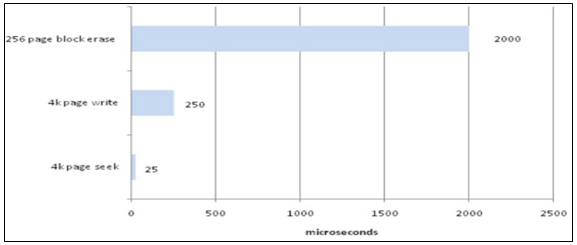
実際、4Kサイズのページを読むのに約25us、書き取りは250usと早いが、1ブロックに対する削除は2msで読み書きに比べて非常に遅いです。
NANDフラッシュメモリは、データの書き込みまたは削除時に、電子を酸化膜を通過させる操作を繰り返します。
そのため、酸化膜に電界が発生するたびに、酸化膜の寿命が低下し、限界に達し、電子を受信できなくなります。
MLC の場合、1つのセルの削除回数が約1万回にに達すると、その有効期間は寿命にに近くなり、 SLCの場合は約10万回が寿命となります。
ただし、読み取るときは、いつでも繰り返すことができます。
SSDの有効期間は、ユニットが保持できる削除の数に関連しています。
したがって、セルの寿命を可能な限り確保するために、削除プロセスは、新しい書き込みが要求された場合にのみ開始されます。
OSからdeleteコマンドを発行しても、メモリ内のデータは、新しいデータを削除せずに、実際には未使用のスペースとして表示されます。
次に、ブロックの支払いが特定の割合の領域を使用していないように表示されるまで待ってからブロックを削除します。
(4) フラッシュ変換層(Flash Translation Layer)
オペレーティングシステムとファイルシステムを基盤とするプログラムはディスクをセクター(Sector)基盤として認識しますが、SSDはページとブロックを基盤として保存単位が実装されています。
これはセクタを基盤として認識するプログラムはSSD にデータを直接記録することができないというものであります。 したがって、セクタ基盤のプログラムがSSD を認識できるように手助けする何かが必要ですが、これをフラッシュ変換階層(Flash Translation Layer)といいます。
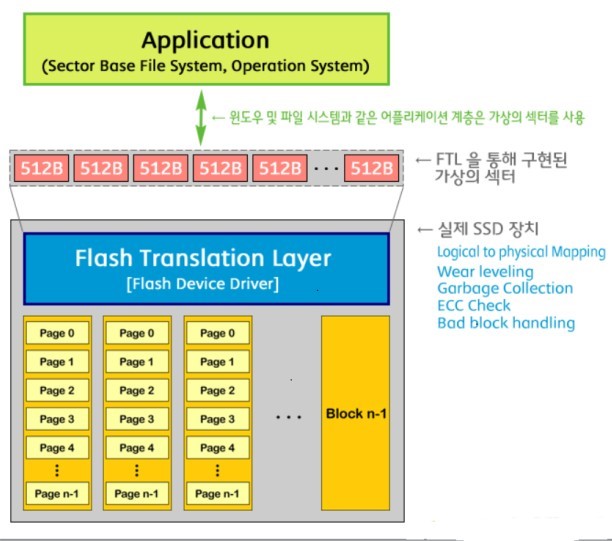
FTLはSSDのコントローラで実行され、仮想論理セクタを作成することで、セクタ ベースのプログラムが物理SSDの物理ページにデータを書き込むのに役立ちます。
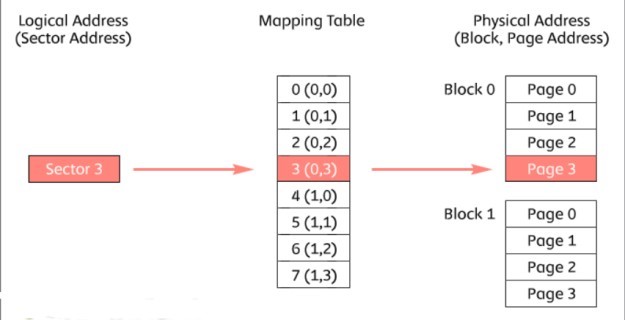
FTLは、 論理セクタを 物理ページに格納するために論理 アドレスを物理アドレス値に変換する必要があり、その値に関する情報はマッピングテーブル(Mapping table)を参照して変換されます。
次の図を参照してください。
SSDが物理ページサイズを論理セクタなどの512 bytesと想定するのを助けるために実際のSSDのページサイズはほとんどが 4Kです。
(5) ウェアレベリング(Wear leveling)とガベージコレクション(Garbage Collection)
SSD はフラッシュメモリなのでセルごとに書き込み回数が制限されています。 したがって、その分メモリ寿命が決まっており、上書きも不可能です。 このような性質のため、同一ページに書き込むことが集中する場合、当該ページが属するブロックは継続的な削除が発生します。 これによって、ブロックに属している他のページも一緒に寿命が短縮されることになります。
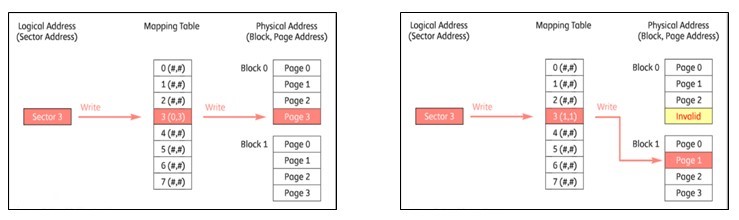
従って、全てのページにくまなく書き込むことができるようにすることでSSD の寿命をのばすことができます。 SSDコントローラは、ウェアレベリングを通じて、全てのページにくまなく書き込むように管理することができます。 ウェアレベリングはFlash Translation Layerで動作しますが、すべてのページの再記録回数を保存し、主マッピングテーブルで論理アドレスと物理アドレスを連結するとき、マッピングアドレスを記録が不十分なページの物理アドレスに変換します。
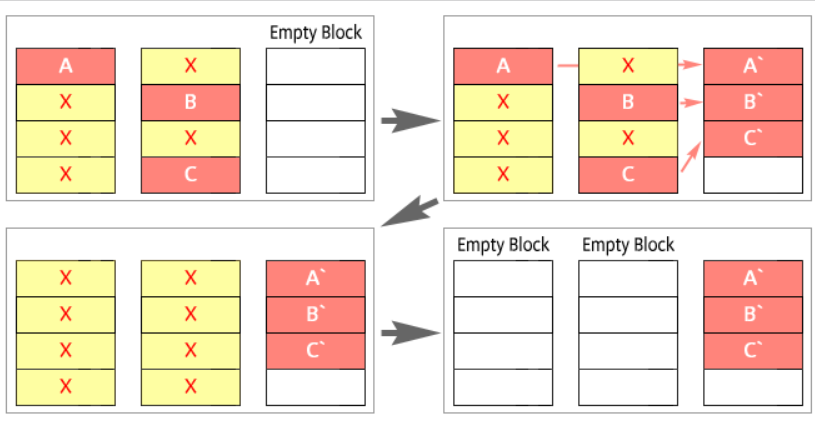
その結果、論理アドレスが使用頻度の低いページの物理アドレスにつながり、書き出し作業が行われます。 つまり、ウェアレベリングは主マッピングテーブルを修正して論理アドレスとつながった物理アドレスを変えてしまうのです。 そして、既存物理アドレスのページはInvalid状態で削除せずにそのまま放っておきます。 これを削除した場合、再びブロック単位の削除が行われ、ウェアレベリングの意味がなくなるためです。 それでは既存のページはいつ削除されるのでしょうか? これはいったん不要なゴミという意味でGarbageの状態(=Invalid)でチェックしておきます。
この状態でずっとメモリーが使われ、ガベージページがある程度溜まった時、適切な時点で一度に削除することになります。 これをガベージコレクション(Garbage collection)と言います。
これは、Javaのガベージコレクションに似ているといえます。
ウェアレベリングとガベージコレクションはSSDコントローラがメモリを管理するのに最も重要な技術です。
最大限書き出し作業をすべてのページに分散させ、SSDの寿命を延ばすだけでなく、最も負担になる削除回数を減らしてSSD性能を保障することができるからです。
Oracle にSSDを適用
ここまでは、SSD構成と基本動作原理について簡単に説明しました。次に、SSDをOracleに適用する際に注意すべき点について説明します。
銀行のインターネットバンキングや証券会社の基幹系システムの場合、数千TPSの短いトランザクションが集中的に発生する場合が多いです。この時、データベース側でディスクI/Oパフォーマンスは、トランザクション処理に大きな比重を占めています。ランダムに分散して発生するI/Oより順次一箇所集中するI/O部分でパフォーマンスの問題が発生する確率が高いのです。
その意味で、短いトランザクションが頻発する環境では、オンラインREDOログのI/Oパフォーマンスが問題になることがあります。
トランザクションが短い場合commit回数が多くなって、REDOログのI/O回数が急増するので、その結果、log file sync待機イベントが発生することがあります。この時、REDOログのI/O速度を向上させることが目的でSSDを適用することができます。
しかし、一般的なデータ・ファイルとは異なり、REDOログにSSDを適用する場合、いくつかの注意が必要です。
REDOログは、通常のデータファイルとは異なり、読み込みより書き込みが頻繁に発生し、限られたファイルサイズでランダム書き込み(Random write)より順次書き込み(sequential write)が継続的にに発生する構造です。
そして、もう一つ重要なことは、Oracleで認識されるブロックサイズです。
ほとんどのOracleのI/Oは2k、4k、8k(default)、16k、32kのいずれかに構成され、ブロック単位で実行されます。二重制御ファイルとREDOログ・ファイルは、他のブロックサイズを持っています。
— コントロール ファイルの ブロック サイズ
SQL> select distinct cfbsz from x$kcccf;
CFBSZ
——- 16384
— REDOログ・ファイルのブロックサイズ
SQL> select distinct lebsz from x$kccle;
LEBSZ
——- 512
コントロールファイルは、ブロックサイズが16kであるのに対し、REDOログのブロックサイズO/Sが認識しているディスクのセクタの大きさで512 bytesです。SSDの物理セクタサイズはページサイズである4Kです。
しかし、すべてのオペレーティングシステムやプログラムが4Kセクターを認識することはありません。
Linuxの場合、カーネル2.6.32バージョンから4kセクターを支援し始めており、前のバージョンは、基本的に512bytesのみ認識することができます。
したがって、Linuxカーネル2.6.32以前は、ディスクのLUNの構成時4kセクターでフォーマットすることができないのです。
ここで、フォーマット(format)は、オペレーティングシステムやプログラムが認識することができる論理セクタサイズを生成するものです。
つまりO/Sやファイルシステムが認識することができる大きさで、ディスクのセクタを構成するというものです。
SSDは、論理セクタサイズが512 bytesや4Kでも物理セクタサイズは、読み取り、書き込み単位であるページ4Kに予め定められています。Oracleのデータファイルのブロックは、ほとんど4Kの倍数であるが、REDOログのみがより小さな512 bytesです。この場合、データファイルと制御ファイルは、4Kの倍数物理セクタサイズと正確なI/Oが発生しますが、REDOログの場合、物理的4Kセクターに合わせるために512 bytesセクター8つを結合して記録することになります。これEmulationモードと言います。4Kセクターを認識しないO/S環境でプログラムがディスクにデータを記録する際に、論理的に4Kを構成して、物理セクタサイズに合わせるようにするものです。
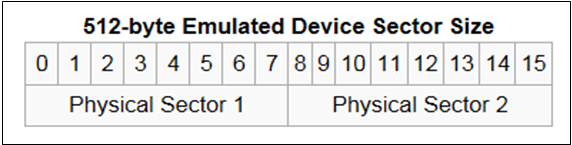
Emulation モードにおける512 Bytes ブロックにデータを記録する過程は、バックグラウンドに見えないいくつかの作業が必要です。 SSDストレージは読み込み、書き出し単位のページ4kを全てキャッシュで読み込みます。 その後、当該512bytesだけを変更してディスクに保存するときは、4kセクター全体を記録することになります。 これを部分書き(Partial Write)と言いますが、単に512 bytesを記録するだけで、複数の手続きを経ることになり、性能に良くない影響を及ぼします。 このため、REDOログファイルをSSDで構成する場合、512bytesセクタでフォーマットされたLUN を使用するとI/O 速度はあまり期待できません。 さらに、それぞれのブロック記録が物理的セクタの出発点から始まっていないため、最後のブロックが新しいセクタとして重なり、追加の書き出しが発生する整列不良状態となります。 整列不良状態はストレージを無駄にし、不必要なI/Oが発生する恐れがあります。

これとは逆にLUNが4Kセクターでフォーマットされた場合をNativeモードという。Nativeモードは、論理セクタと物理セクタの両方が4Kで構成された場合です。その結果、データの記録過程が4Kまたはその倍数の物理セクタサイズと同じように、I/Oが発生することになります。
これはセクタが上書きされる前にはセクタからデータを読み込む必要がないので、Emulation モードに比べてI/O速度が速いのです。
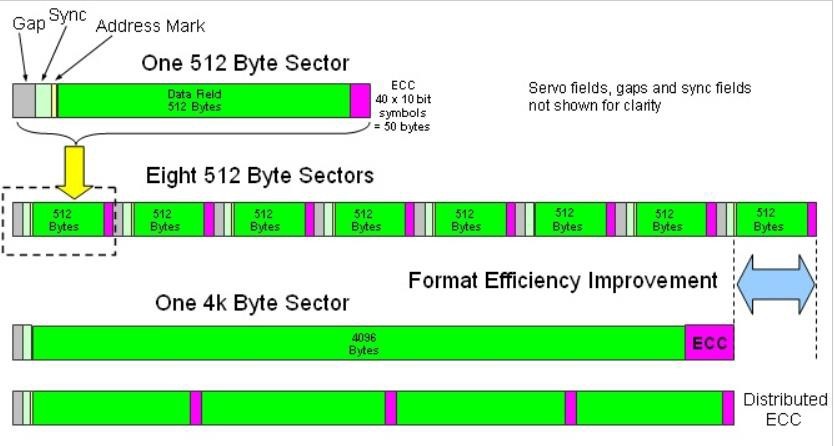
4Kセクターの大きさでディスクをフォーマットする場合を、Advanced Format(Advanced format)と呼びます。4Kセクターフォーマットは、既存のレガシー(legacy)ディスクの512 bytesフォーマットよりもパフォーマンスと容量の効率が高くなります。図で示すように、512 bytesセクターごとに存在するECC(Error Correction code)の部分を4Kセクターでは、一つに統合され、管理されるため、より強力なエラー訂正が可能であり、不必要な容量が減ります。
LUN(Logical Unit Number):論理ストレージユニットにより、SCSIバスで使用される一意の識別子で最大8台までの独立した装置が互いに区別できるようにします。LUNは、特定の論理ユニットを識別するための固有の番号としてストレージをLUN単位に分けて構成します。したがって、LUNを論理的単位ユニットで構成し、ボリュームマネージャを使用して、ファイルシステムを構成します。
4Kセクタを認識できないデバイスで LUNを作成した場合、ディスクは512バイトのセクタサイズにフォーマットでき、Emulationモードで処理できます。
したがって、部分的な書き込みや不適切な順序などの潜在的な問題は避けられません。
ただし、Oracleがo OSカーネルが認識できない4Kセクタを認識できる場合は、状況が異なります。
これは、ほとんどのI/OがOracle によって発生するためです。
したがって、Oracle が 4Kブロックの読み取りと書き込みを行うことができれば、Emulationモードの欠点を克服できます。
Oracleは11gr2から4kセクターを認識できるようになりました。その結果、4kと同じか大きなブロックの正確なサイズのI/Oを発生させることができます。ASMディスク・グループとオンラインREDOログの場合、それぞれのSECTOR_SIZE、BLOCKSIZEキーワードを使用して、その領域のセクタサイズを4Kに変えることができます。したがって、SSDのように物理セクタサイズが4Kベースのストレージの場合、重要な性能改善効果を見ることができます。したがって、4kセクターベースのストレージを使用する場合は、Oracleが考慮事項は、大幅に減少しました。
しかし、最大の問題は、論理セクタと物理セクタが異なるセクターサイズで構成された場合です。LUNは、512 byteセクターサイズでフォーマットされた状態なのにREDOログを4Kセクターに生成する場合OSカーネルとOracleカーネルとの間のセクタサイズが違うので、エラーが発生します。
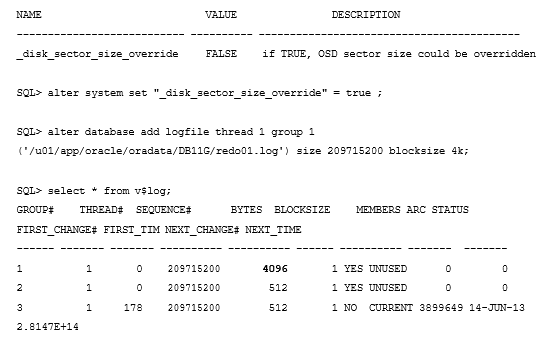
SQL> alter database add logfile thread 1 group 1 (‘/u01/app/oracle/oradata/DB11G/redo01.log’) size 209715200 blocksize 4k;alter database add logfile thread 1 group 1 (‘/u01/app/oracle/oradata/DB11G/redo01.log’) size 209715200 blocksize 4k
*
ERROR at line 1:
ORA-01378: The logical block size (4096) of file
/u01/app/oracle/oradata/DB11G/redo01.log is not compatible with the disk sector size (media sector size is 512 and host sector size is 512)
デフォルトでは、Oracleはファイルを作成するときにカーネルのセクタサイズを確認する必要があります。
ただし、seedパラメーター “_ disk_sector_size_override” を TRUEに変更すると、OSカーネルの検査プロセス (Default : false)をOracleで無視できます。
Linuxカーネルのバージョンが2.6.32以降の場合、LUNを作成するときに、論理セクタサイズは物理セクタと同じ4Kに設定できます。
つまりは4K サイズのドバンストフォーマット形式を採用できます。
この場合、「_disk_sector_size_override」隠しパラメータを変更せずに4KセクタサイズのREDOログを生成してもORA-01378エラーは発生しません。
一方、 2.6.32より前の バージョンでは、物理セクタは4kのままですが、O/Sによって認識されるには、512bytes セクタの LUNを生成する必要があります。
この時点で、 4KブロックのREDOログを作成する場合は、 ORA-01378エラーを回避するめに、 必ず「_disk_sector_size_override」隠しパラメータをtrueに変更しなければならないのです。
Linux カーネル2.6.32 ディスクの論理セクタ、物理セクタ サイズ、ディスクの種類などの情報を特定のファイルから検索できます。
– 物理 セクタ サイズ
[root@ora11 queue]#cat /sys/block/sdb/queue/physical_block_size 4096
– 論理 セクタ サイズ
[root@ora11 queue]#cat /sys/block/sdb/queue/logical_block_size 512
-フラッシュメモリかどうか照会(ヘッダーが回転ディスクではなくメモリタイプのディスクの場合、結果は 0になります)
[oracle@ora11 ~]$cat /sys/block/sdb/queue/rotational 0
ここでは、これまでに説明したいくつかの簡単な表を示します:
| Linux カーネル バージョン | Oracle バージョン | SSD 形式 部門 | やり直し 部門 | _disk_sector_size_override |
| 2.6.32 より前 | 11gr2 | 4K不可/ 512 bytesのみ可能 | 512 bytes | False |
| 2.6.32 より前 | 11gr2 | 512 bytes | 4K | True |
| 2.6.32 以降 | 11gr2 | 512 bytes | 4K | True |
| 2.6.32 以降 | 11gr2 | 4K | 4K | False |
結論
既定では、SSDの物理セクタサイズは4Kです。これはSSDの読み取り/書き込みユニットで、論理セクタサイズが同じ場合にI/Oパフォーマンスを最適化できます。論理セクタサイズはディスクの論理ユニットLUN(Logical Unut Number)を作成するときに決定されます。4Kセクタフォーマットにより、ディスクのパフォーマンスと容量使用率が向上するため、これからは物理的セクター4Kのディスクが主流を成すものと見られます。4Kセクタ形式は、SSDを適用してI/Oパフォーマンスを向上させるために不可欠です。つまり、論理セクタサイズは物理セクタサイズと一致します。
ただし、O/Sカーネルのバージョンとファイルシステムの種類によっては、4K形式が不可能な場合があります。この場合、LUNは 512 bytes論理セクタを使用して生成する必要があります。
Oracleでは、11gr2からファイルのセクタサイズを変更できます。
512bytesのセクタサイズのみ認識できるOSカーネルでも、Oracleは4KセクタサイズのREDOログを生成できます。
従って、REDOログにSSD を正しく適用するためには、Oracle バージョンが 11gr2、OSコア(Linuxは2.6.32)より後かどうかで、4Kセクタサイズを認識できる場合に可能です。
実際、SSDは従来のディスクよりも優れた I/O パフォーマンスを提供します。
ただし、操作原理が正しく理解されておらず、盲目的に適用した場合、効果は期待どおり大きくならないことに注意してください。
参考文献
http://en.wikipedia.org/wiki/Advanced_Format http://en.wikipedia.org/wiki/Solid-state_drive http://flashdba.com/4k–sector–size/
http://ashminderubhi.wordpress.com/2013/01/14/4k–configurations-with–oracle/
http://guyharrison.squarespace.com/ssdguide/


